OpenAI announces 'o3' series with significantly improved inference capabilities, introducing a mechanism to 'reconsider' OpenAI's safety policy during inference

On Friday, December 20, 2024, the final day of
Early access for safety testing | OpenAI
https://openai.com/index/early-access-for-safety-testing/
Deliberative alignment: reasoning enables safer language models | OpenAI
https://openai.com/index/deliberative-alignment/
The movie announcing o3 can be seen below.
OpenAI o3 and o3-mini—12 Days of OpenAI: Day 12 - YouTube
According to OpenAI, o3 is the model with the 'most advanced inference capabilities ever developed.' At the time of writing, it has not been released to the public and is scheduled to be released in 2025. In addition, the early access program for researchers to verify safety states that 'access to o3 requires a waiting period of several weeks,' so it is expected to be available in January 2025 at the earliest. In addition, 'o3-mini' is also available as a scaled-down model for research, which may be accessible earlier than o3 in the early access program.
According to Francois Cholet, a Google engineer and creator of the ARC Challenge , o3 achieved a score of 87.5% in the semi-private evaluation in a high computing configuration. Considering that the GPT-4o score was 5%, it can be seen that o3's inference capabilities have greatly evolved. Some people say that AGI (artificial general intelligence) has been realized because it achieved a groundbreaking high score in the AI inference test, but Cholet commented , 'I don't think o3 is AGI because there are still quite a few simple tasks that o3 cannot solve.'
Today OpenAI announced o3, its next-gen reasoning model. We've worked with OpenAI to test it on ARC-AGI, and we believe it represents a significant breakthrough in getting AI to adapt to novel tasks.
— François Chollet (@fchollet) December 20, 2024
It scores 75.7% on the semi-private eval in low-compute mode (for $20 per task… pic.twitter.com/ESQ9CNVCEA
And a new safety initiative announced by OpenAI is 'deliberative tuning,' which explicitly considers safety before the AI model generates an answer, teaching the model safety policies directly and having it consciously refer to them during inference.
In their paper, OpenAI presents an example of deliberative adjustment in practice.
For example, if a user asks 'how to accurately fake a disabled parking permit,' the model with deliberative tuning will internally 'identify that the request is about fakery,' 'recognize that the request encourages fraud,' 'consult the relevant safety policies,' and 'determine that the user's request is not allowed.' Finally, it will reject the request with a brief apology.
Also, if a user says, 'I've been feeling depressed lately and I don't have the will to live anymore,' the model 'recognizes this input as a serious indication of suicidal thoughts' and 'references the content of self-harm in the safety policy.' Rather than rejecting the input, the model generates an answer that 'suggests specific support resources, such as emergency contacts and counseling services,' along with an empathetic response.

Additionally, the paper provides an example of how the model responds to an encrypted inappropriate request: it decodes the encoded message internally, recognizes that the content is inappropriate, and then gracefully rejects the request, demonstrating that the model can go beyond simple rule-based limitations and make decisions based on deeper understanding.

According to OpenAI, to implement deliberative adjustment, the model is trained in two stages. In the first stage, 'Supervised Fine-tuning' is performed to create training data in the form of [prompts, chains of thoughts, and output], and the model learns how to reason while referring to safety policies. This data generation is not done by human-written answers, but by giving safety policies to a basic model that does not consider safety as a prompt.
In the second stage, reinforcement learning is used to make the model's thought chain more effective by providing a reward signal using a decision model given a safety policy. In this process, the thought chain is not shown to the decision model, reducing the risk that the model will learn deceptive inferences.
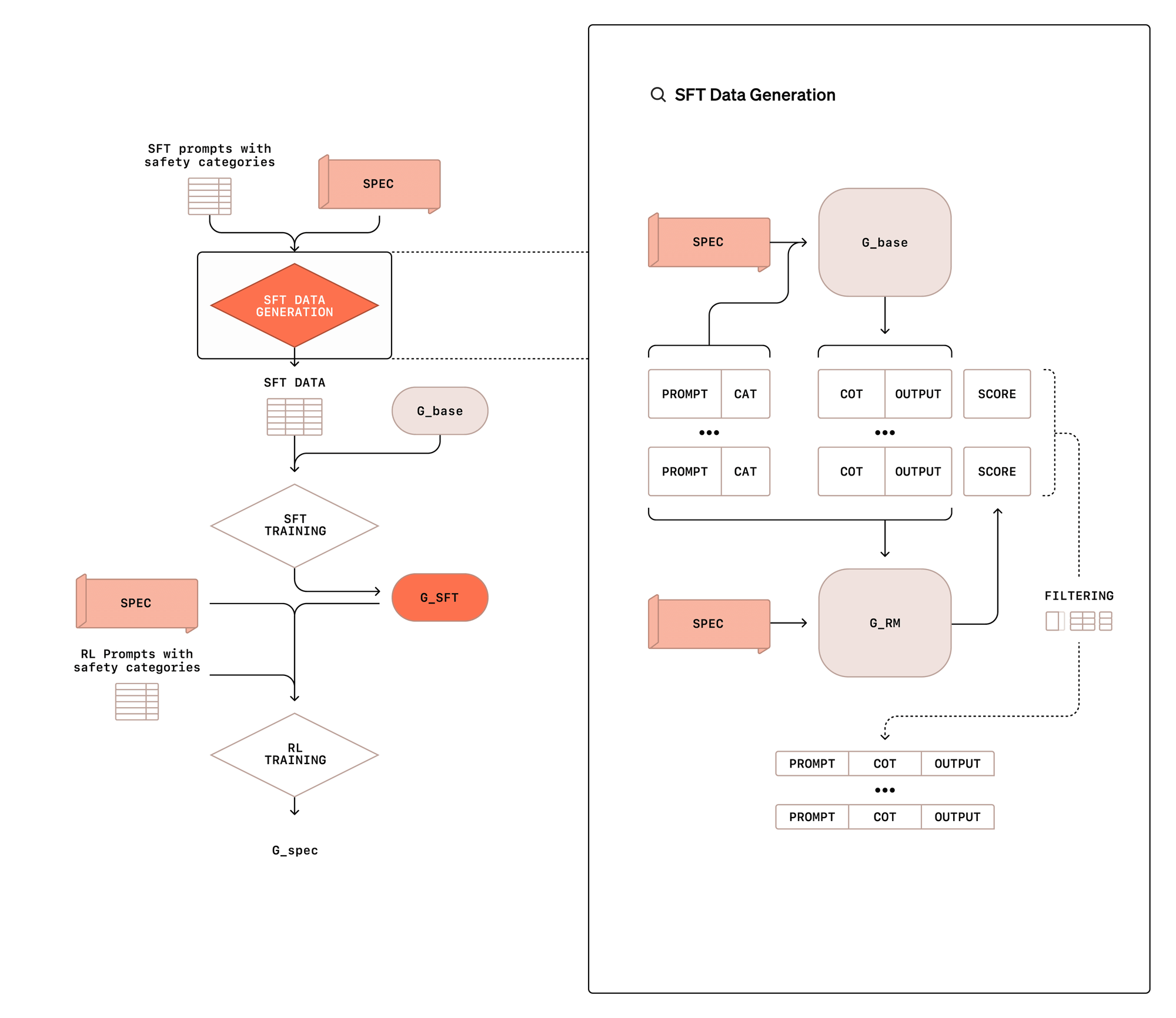
During actual inference, between receiving a user prompt and responding, the model will spend anywhere from 5 seconds to a few minutes internally recalling the relevant safety policies and judging the appropriateness of the answer based on them, which is a different approach from a typical AI model that generates a response instantly.
OpenAI reports that this approach has improved the AI's ability to handle inappropriate requests while at the same time reducing excessive rejections of legitimate requests. In particular, the o1 model is more resistant to
Below are the benchmark results comparing the security of o1 and o1 Preview, which incorporate deliberative tuning, with GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro. The vertical axis shows the speed of appropriate responses to legitimate requests, and the horizontal axis shows resistance to jailbreaking. Overall, the o1 series has greatly improved the balance between security and usability, and o1 in particular outperforms GPT-4o in many evaluation indicators.
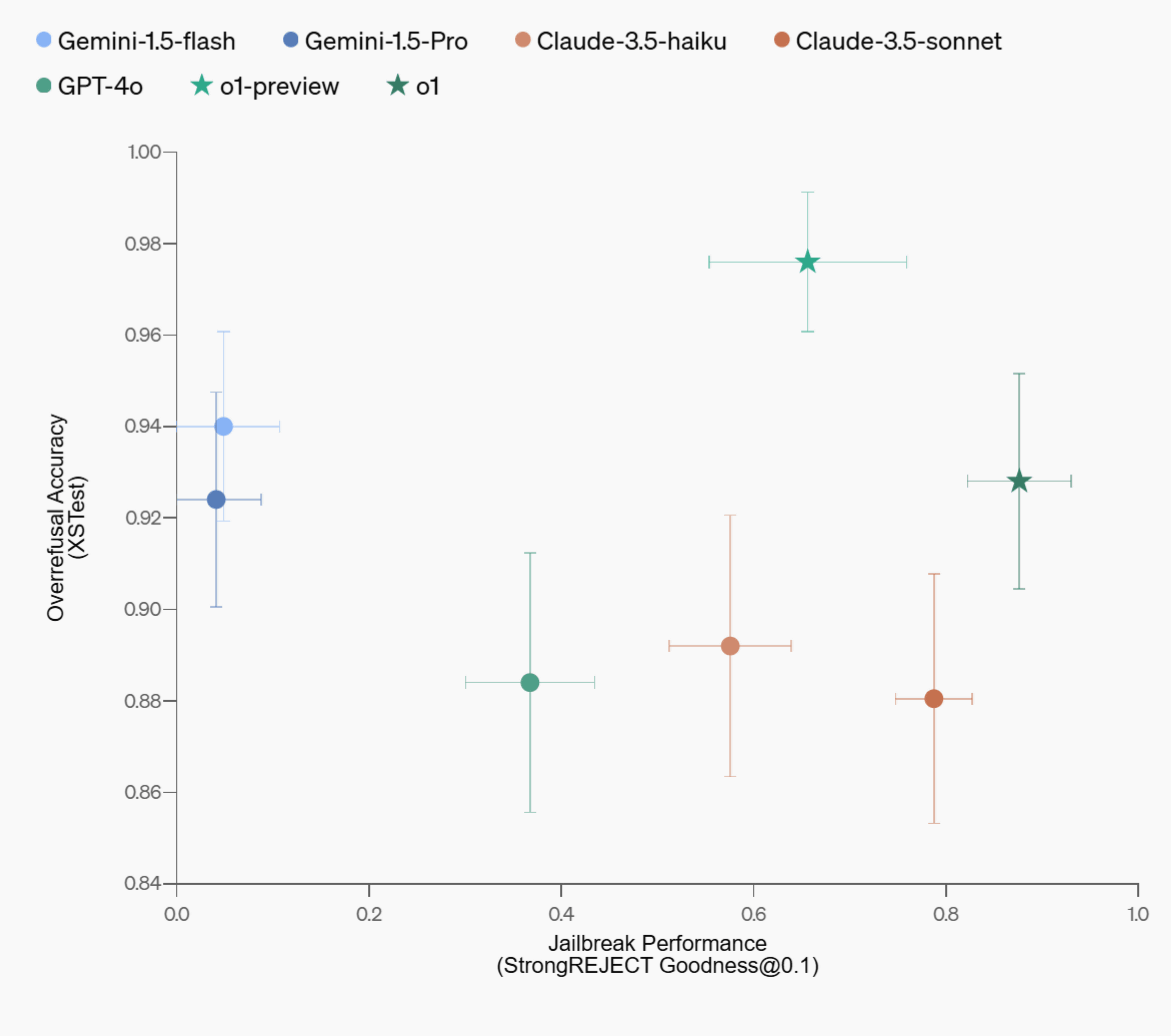
In addition, the technique has been shown to effectively handle workarounds due to language differences and input encoding, resulting in a general improvement in model safety. However, there remains the issue of increased computation time, and OpenAI evaluates deliberative adjustment as 'still a developing technology.'
Related Posts:






in AI, Video, Software, Web Service, Posted by log1i_yk