OpenAI announces 'OpenAI o1' and 'OpenAI o1-mini' AI models with complex reasoning capabilities, demonstrating high capabilities in programming and mathematics

OpenAI has announced new AI models, ' OpenAI o1 ' and ' OpenAI o1-mini '. By using a 'chain of thoughts' technique that performs step-by-step reasoning, it is able to correctly perform complex reasoning, and it was ranked in the top 500 in the US in the preliminary rounds of the Mathematical Olympiad. It is also said to have human doctoral level abilities in the fields of physics, biology, and chemistry.
Learning to Reason with LLMs | OpenAI
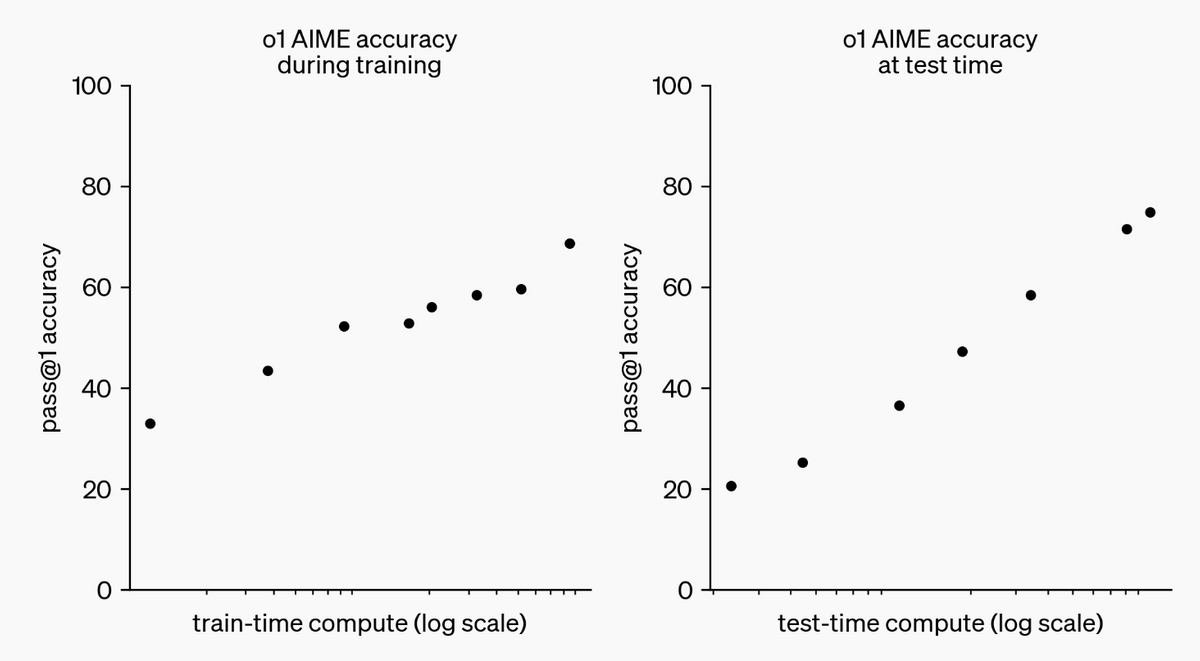
It is stated that the performance of OpenAI o1 not only improves with increasing training time, but also with increasing inference time. This phenomenon will continue to be investigated.
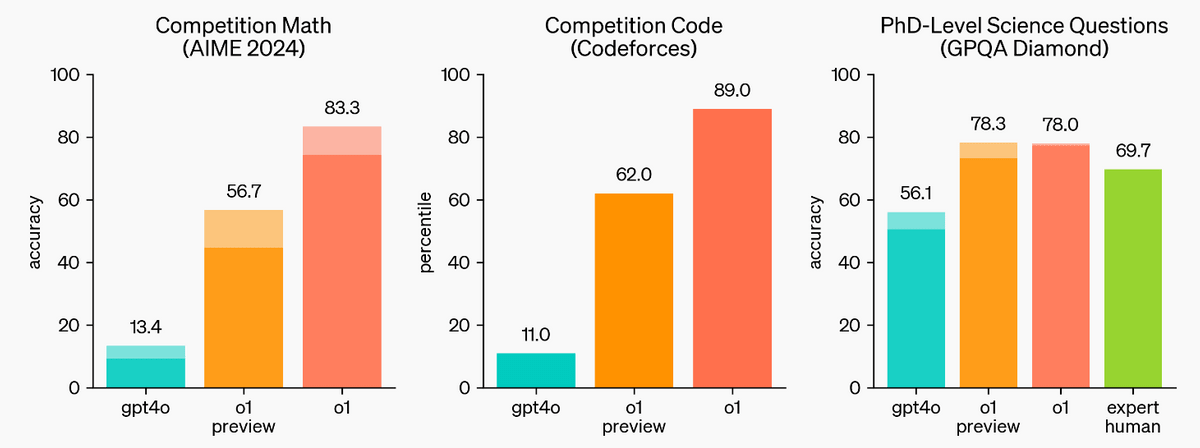
When time was spent on inference, OpenAI o1 significantly outperformed GPT-4o in
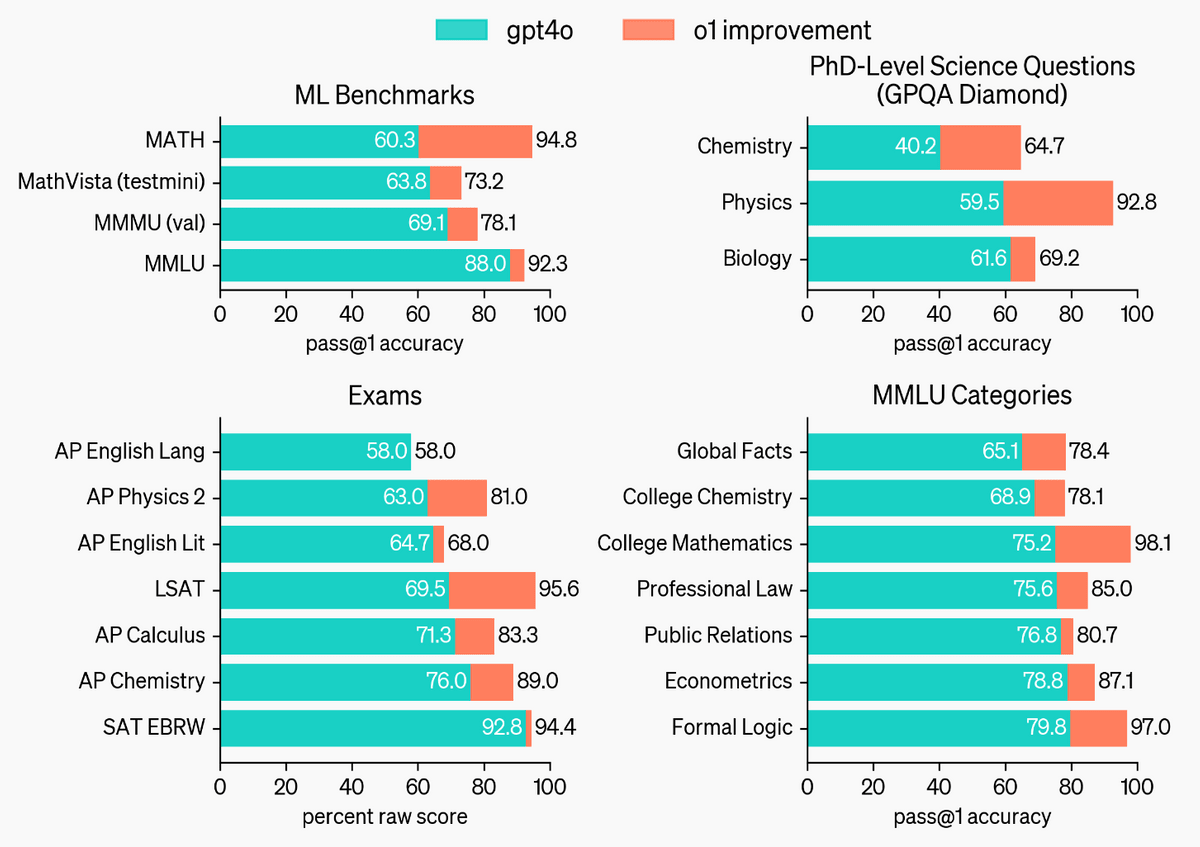
In addition, OpenAI o1 outperformed GPT-4o in 54 out of 57 benchmarks.
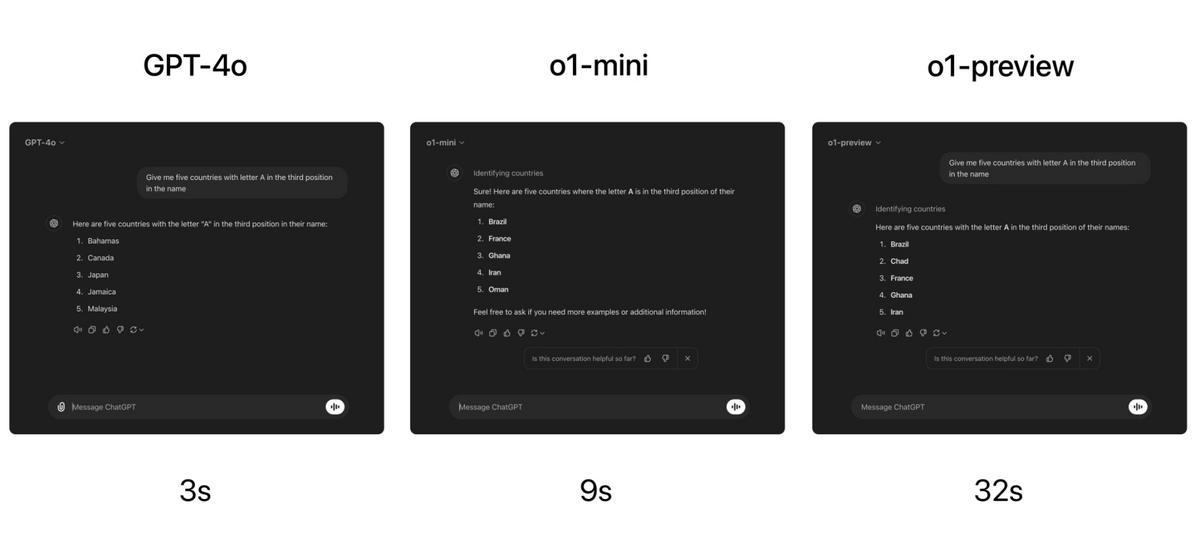
The OpenAI page contains several examples of actual inference, and in the 'encryption' example, 'oyfjdnisdr rtqwainr acxz mynzbhhx' becomes 'Think step by step' based on the example, 'oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz'.
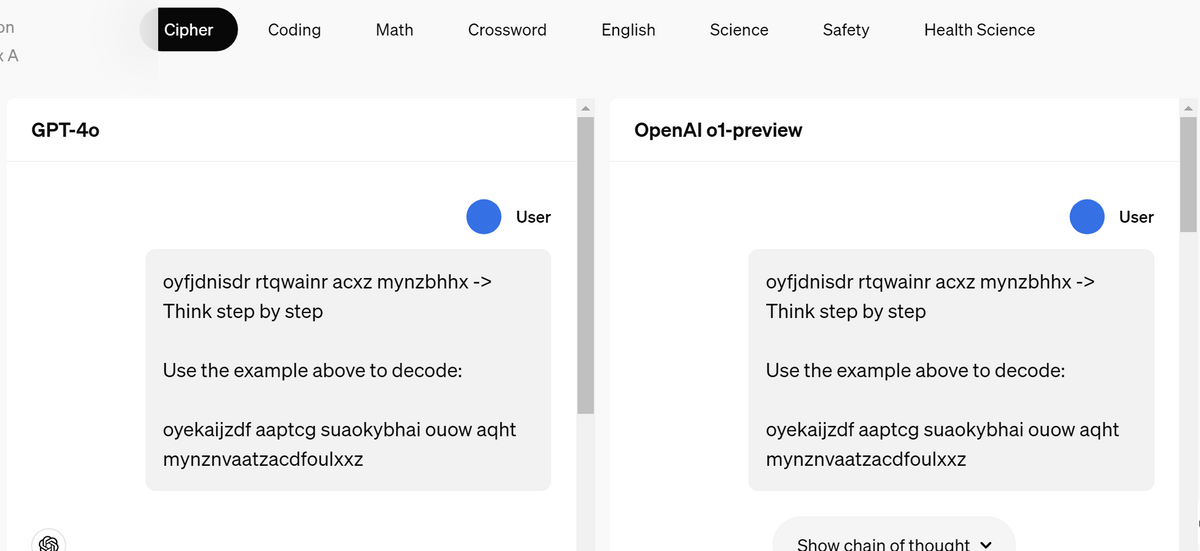
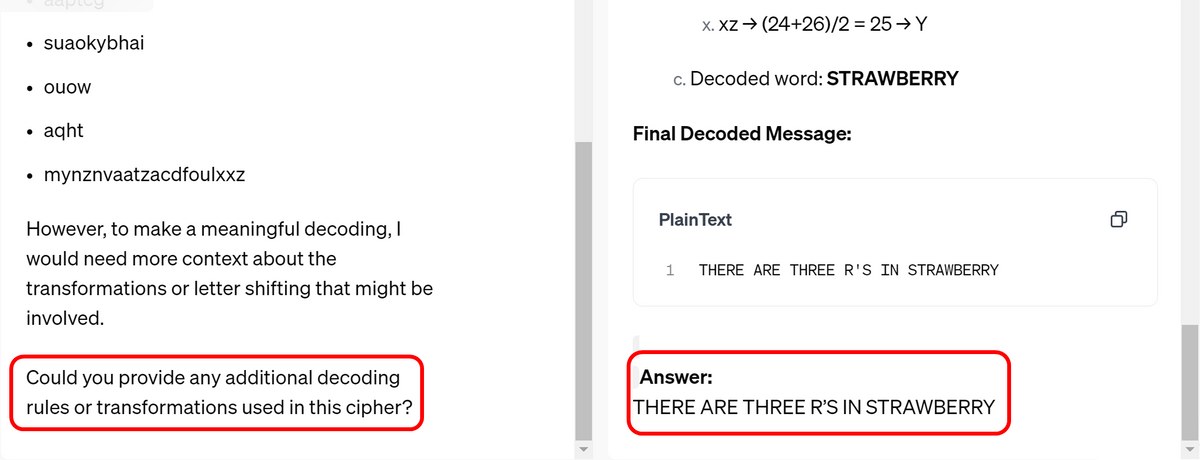
While GPT-4o failed to crack it, OpenAI o1-preview succeeded.
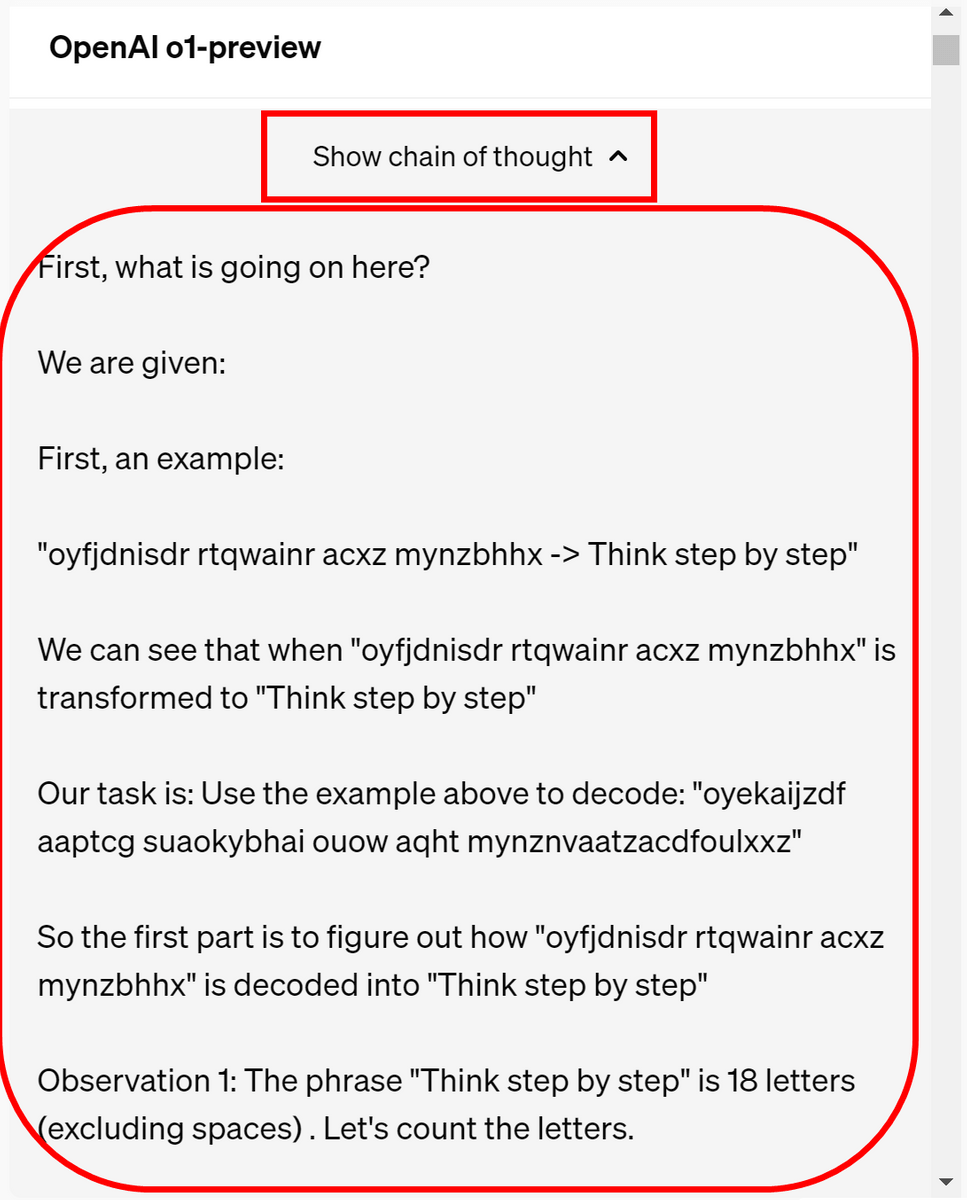
By clicking the 'Show chain of thought' button, you can see what kind of 'chain of thought' process was performed internally. In addition, it is said that in the retail version, the contents output by the chain of thought process will be charged as 'output tokens' but will not be disclosed.
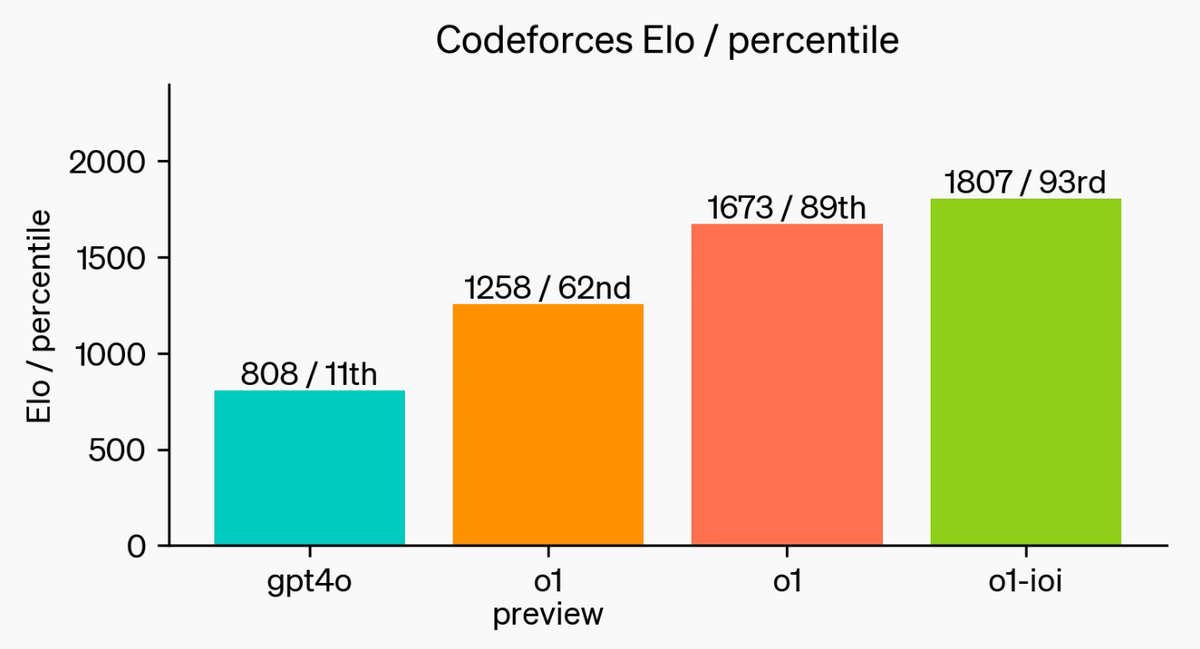
When OpenAI o1 participated in a competitive programming contest, it placed in the top 11% of participants. In addition, by specializing OpenAI o1 for programming, it was possible to improve its performance to the top 7%.
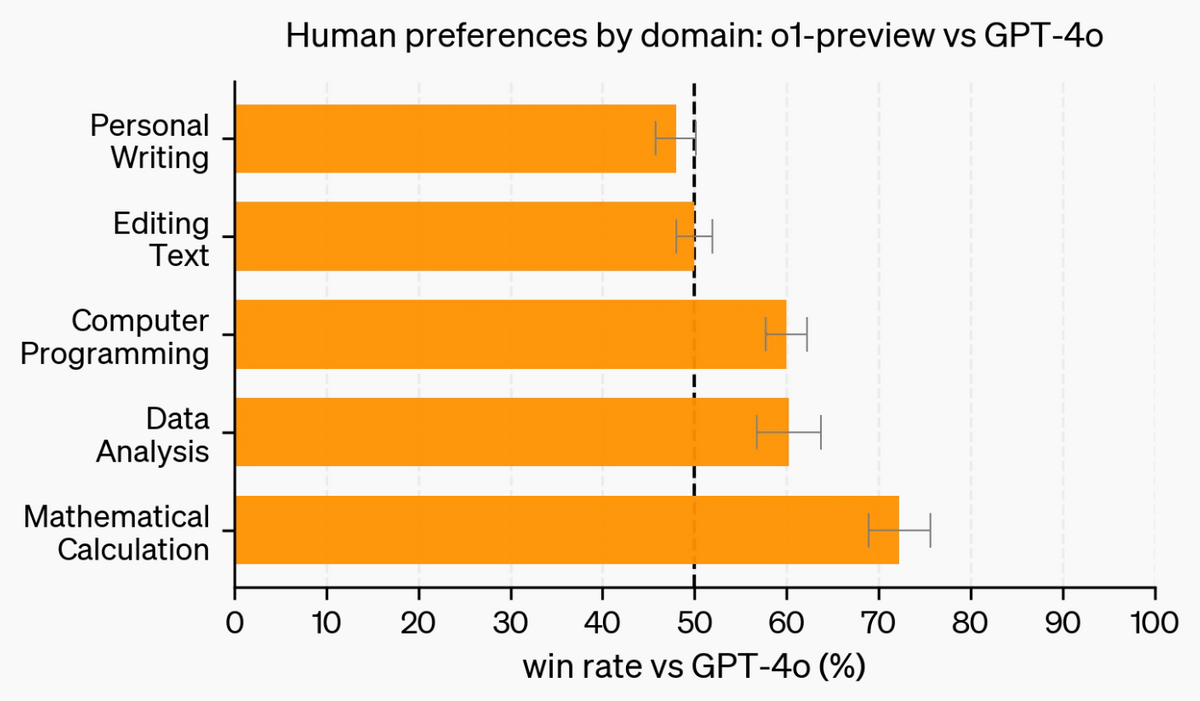
The figure below shows the results of an evaluation of responses to a wide range of free-text prompts written by humans. Responses from GPT-4o and OpenAI o1-preview were displayed anonymously to human-written prompts, and we evaluated which one was better. OpenAI o1-preview was rated higher in areas where inference is important, such as programming, data analysis, and mathematical calculations, but was rated roughly equal in areas such as writing and editing text.
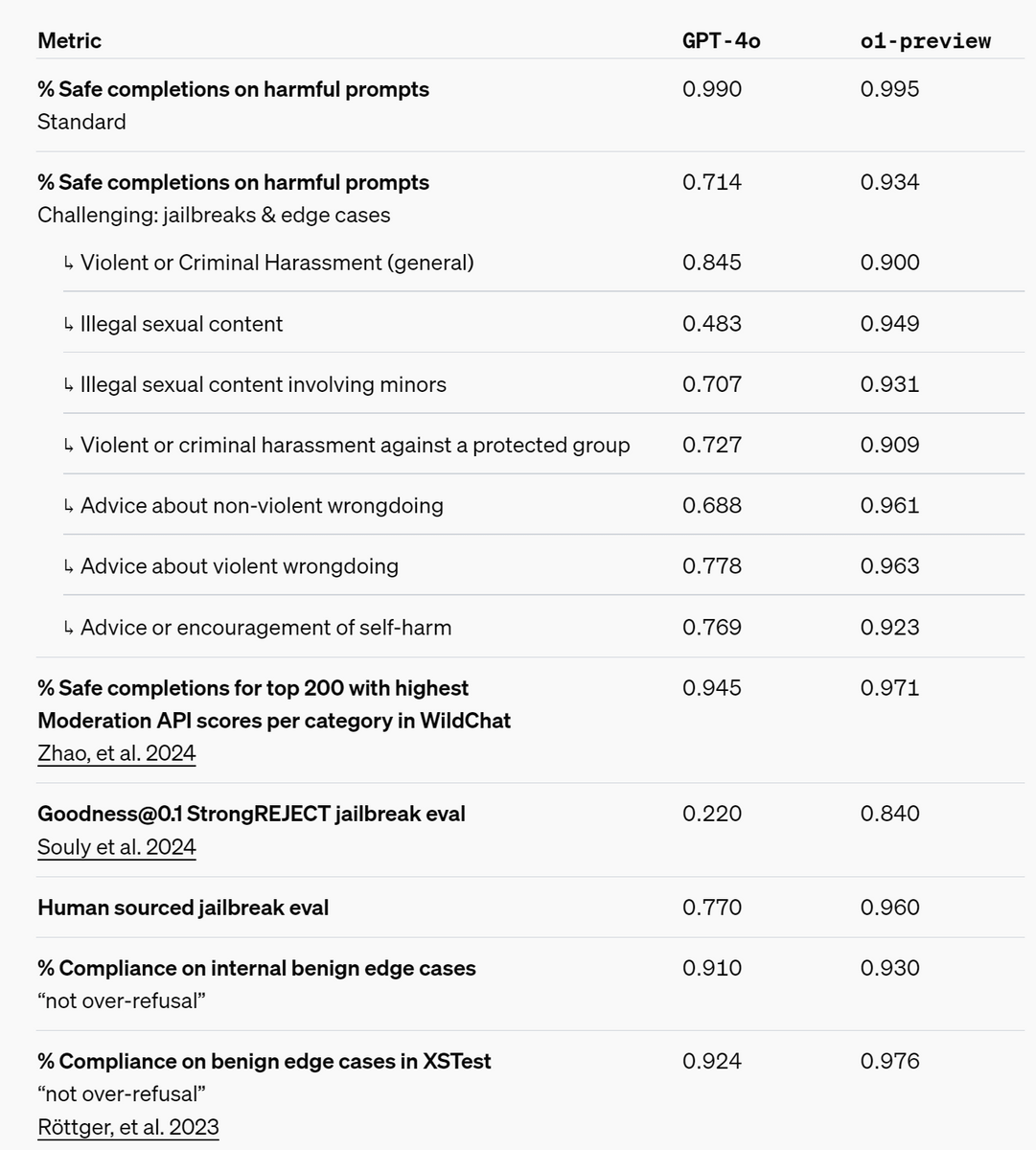
In addition, the safety of the model has been improved by integrating policies regarding the model's operation into the chain of thoughts process. OpenAI o1 has significantly improved the scores of many safety benchmarks over GPT-4o. Detailed safety measures are described on
The OpenAI o1-mini, which was announced at the same time, is a model that cuts out a wide range of world knowledge, while maintaining the same
The OpenAI o1-preview and OpenAI o1-mini models are available as beta versions and are available only to Tier 5 developers at the time of writing. ChatGPT Enterprise and Edu users will be able to use both models starting next week, and the company plans to release the OpenAI o1-mini model to ChatGPT Free users in the future.
Related Posts:





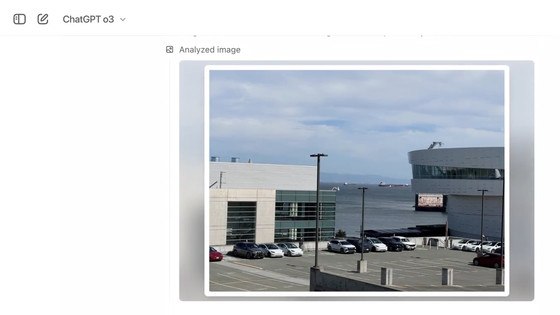
in AI, Software, Web Service, Web Application, Posted by log1d_ts