CerebrasがNVIDIA H100の22倍高速な爆速AI推論サービスを発表、デモページも公開されたので使ってみた

AI処理用プロセッサなどの開発を進めるテクノロジー企業のCerebrasが、高速な推論サービス「Cerebras Inference」を発表しました。Cerebras InferenceはNVIDIAのH100を用いた推論サービスと比べて22倍高速で、コストは5分の1に抑えられるとのことです。
Inference - Cerebras
https://cerebras.ai/inference
Introducing Cerebras Inference: AI at Instant Speed - Cerebras
https://cerebras.ai/blog/introducing-cerebras-inference-ai-at-instant-speed
AI関連の計算処理を大きく分類すると、AIモデルを構築する「学習」とAIモデルにプロンプトを入力して出力を得る「推論」の2つに分けられます。Cerebras Inferenceはこのうち推論処理を担うサービスです。Cerebras Inferenceの処理サーバーはCerebrasの独自開発チップ「WSE-3」を用いて構築されており、高速な推論処理が可能です。
Cerebras Inferenceとその他の推論サービスの「1ユーザー・1秒当たりの処理トークン数」を示すグラフが以下。Llama 3.1 8Bの推論処理を実行した結果、GPUで構築されたクラウド推論サービス比べてCerebras Inferenceは圧倒的に高い推論性能を備えているほか、独自プロセッサを採用した高速推論サービス「Groq」よりも高速な処理が可能であることが示されています。
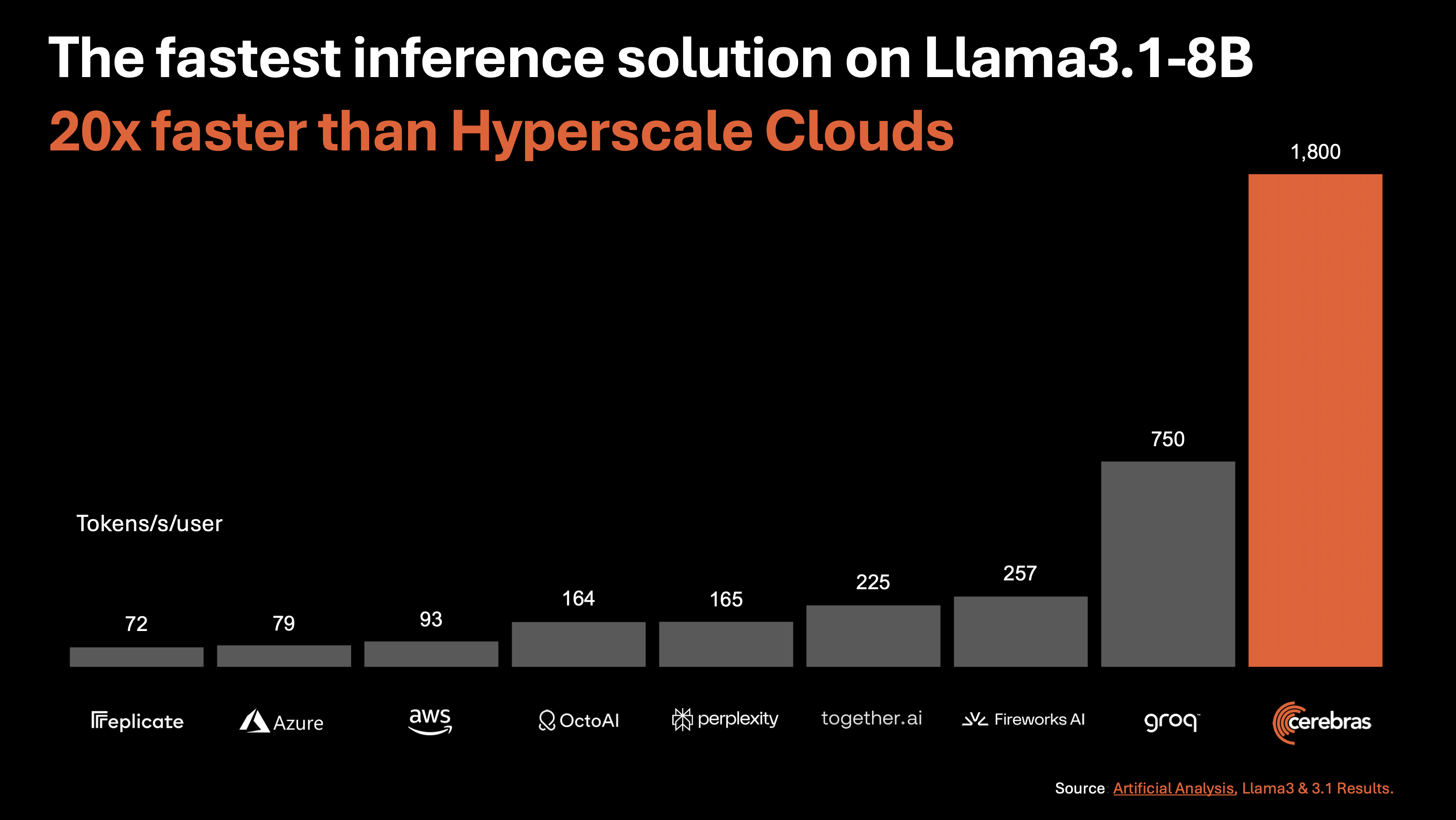
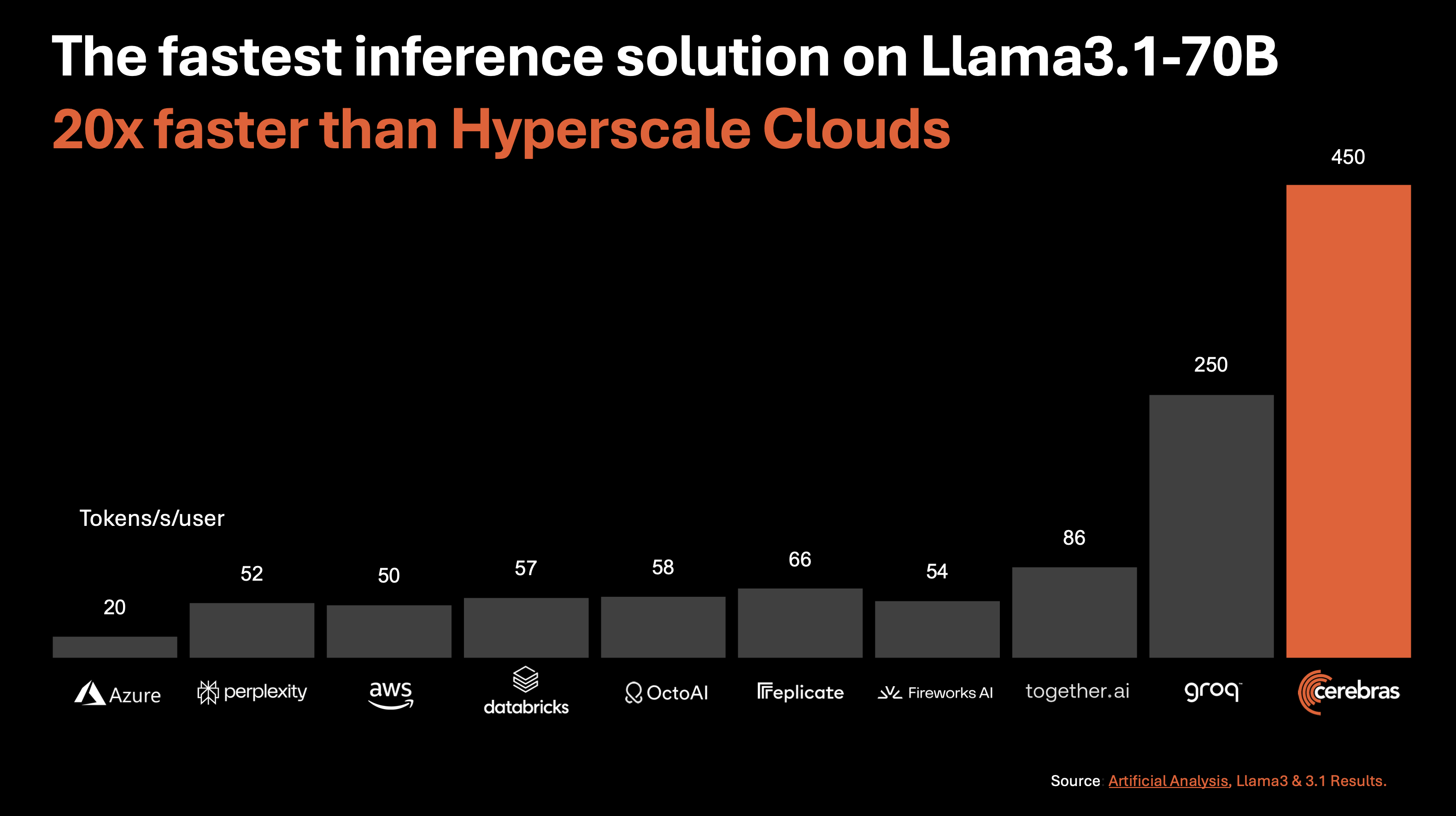
Llama 3.1 70Bでも同様にCerebras Inferenceの性能の高さが際立っています。
Cerebras Inferenceの性能やコストをH100を採用した推論サービスと比較するとこんな感じ。処理性能はH100の22倍で、コストはH100の5分の1に抑えられています。

以下のデモページでは、Llama 3.1 8BもしくはLlama 3.1 70Bとのチャットを介してCerebras Inferenceの性能を体感できます。なお、デモを実行するにはGoogleアカウントかMicrosoftアカウントでログインする必要があります。
Cerebras Inference
https://inference.cerebras.ai/
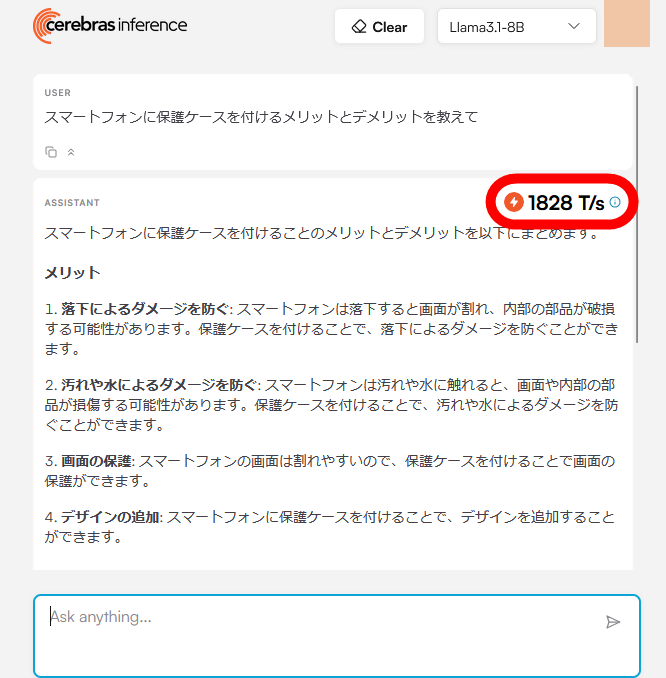
実際にLlama 3.1 8Bと会話してみたところ、一瞬で応答が返ってきました。応答の右上には毎秒1828トークンの処理を実行できたことが示されています。
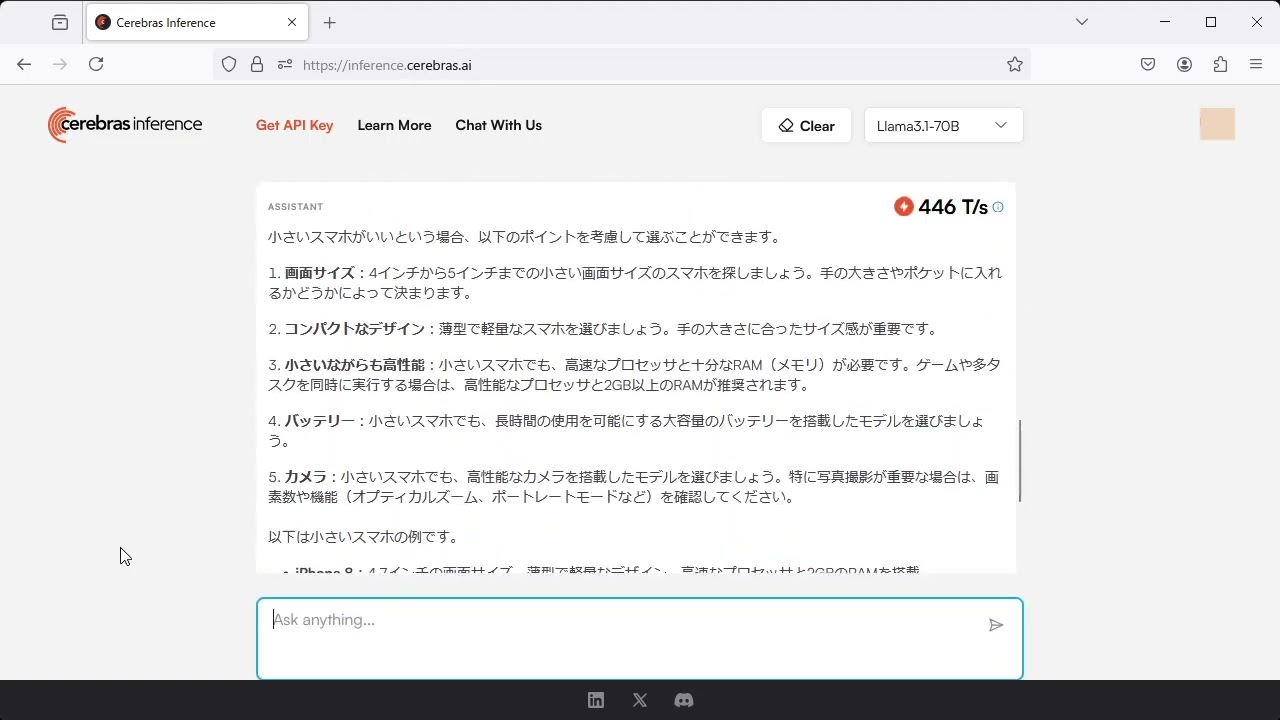
言語モデルは画面右上のダイアログで変更可能。Llama 3.1 70Bに切り替えてチャットしてみます。
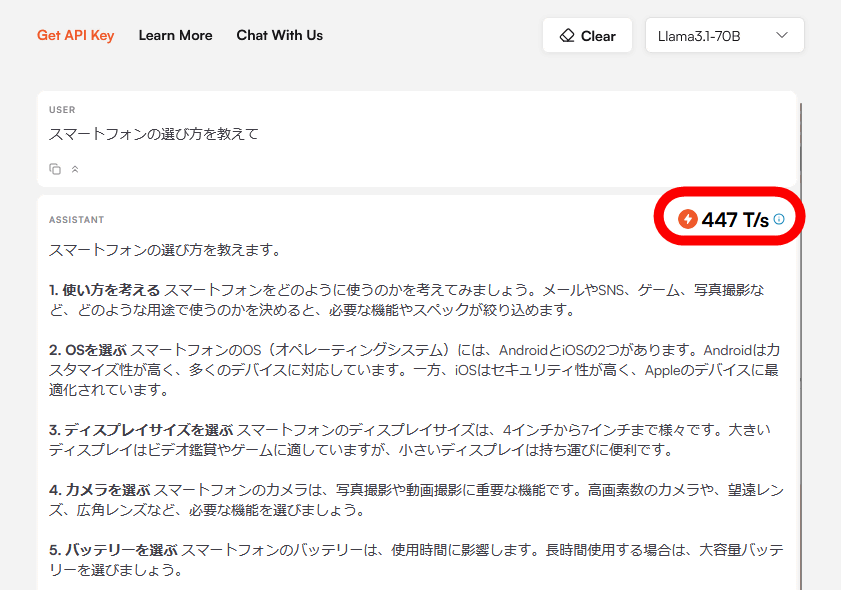
Llama 3.1 70Bの場合は、秒間処理トークン数は447でした。
Cerebras Inferenceの推論処理はとにかく高速で、文章を送信すると一瞬で返答が表示されます。実際にLlama 3.1 8BやLlama 3.1 70Bと会話する様子は、以下の動画で確認できます。
爆速AI推論サービス「Cerebras Inference」でLlama 3.1 8BやLlama 3.1 70Bとの会話を試す - YouTube
なお、Cerebras Inferenceの料金はLlama 3.1 8Bが100万トークン当たり10セント(約14円)で、Llama 3.1 70Bの場合は100万トークン当たり60セント(約87円)です。
・関連記事
4兆個のトランジスタを搭載した世界最速のAIチップ「WSE-3」をCerebrasが発表 - GIGAZINE
1億6300万のコアで120兆個のAIパラメーターをトレーニング可能なモンスターマシン「Cerebras CS-2」が発表される - GIGAZINE
オープンソースでGPTベースの大規模言語モデル「Cerebras-GPT」7種類が一気に誰でもダウンロード可能に - GIGAZINE
大規模言語モデル(LLM)を爆速で動作させる「言語処理ユニット(LPU)」を開発する「Groq」が爆速アルファデモを公開 - GIGAZINE
・関連コンテンツ