




中国IT大手TencentがNVIDIAに頼らず自社製AIインフラのAI学習能力を20%強化

企業や研究機関が用いる大規模なAIインフラストラクチャには大量の計算処理チップが搭載されており、膨大なデータを並列処理できるように構成されています。新たに、中国の大手IT企業であるTencentが、AIインフラストラクチャのネットワーク処理を改善し、AI学習性能を20%向上することに成功したと発表しました。
大模型训练再提速20%!腾讯星脉网络2.0来了_腾讯新闻
https://new.qq.com/rain/a/20240701A067GC00
Tencent boosts AI training efficiency without Nvidia’s most advanced chips | South China Morning Post
https://www.scmp.com/tech/big-tech/article/3268901/tencent-boosts-ai-training-efficiency-without-nvidias-most-advanced-chips
Tencentによると、AIインフラストラクチャのような大規模なHPCクラスタでは、全処理時間のうちデータ通信時間が最大50%を占めるとのこと。ネットワーク処理性能を向上してデータ通信時間を短縮できれば、GPUの待機時間が減って全体的な処理能力を向上できます。このため、Tencentは自社製AIインフラストラクチャのネットワーク処理性能の向上に取り組みました。
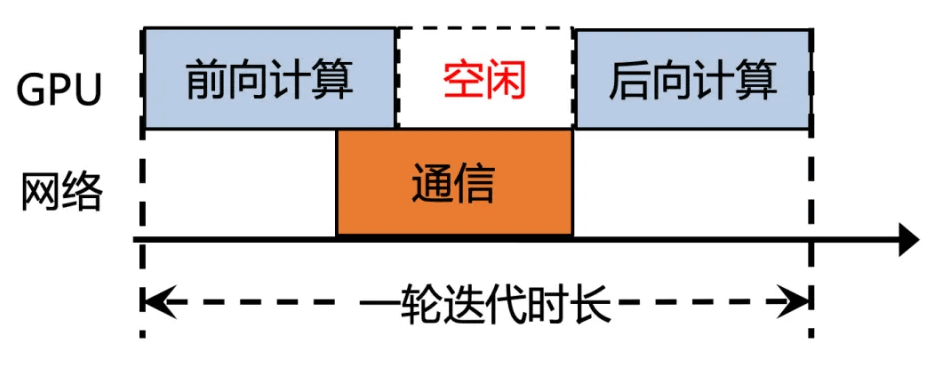
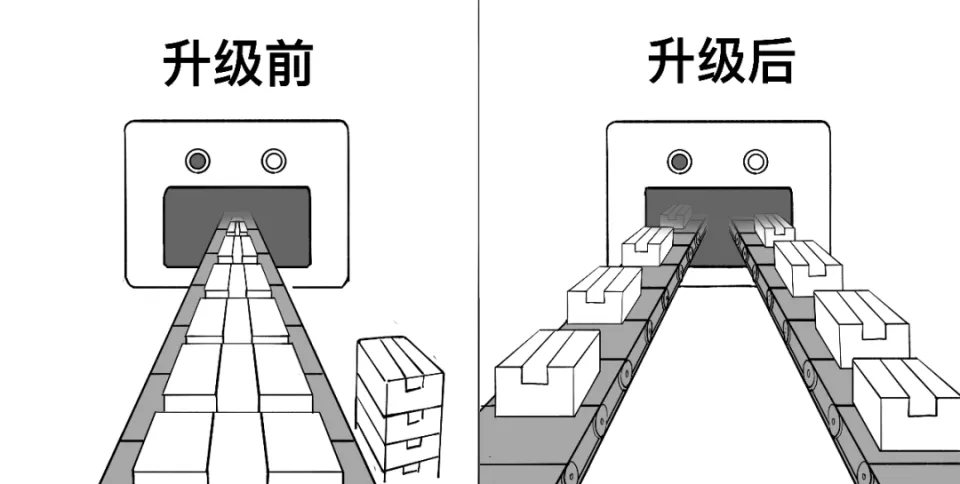
Tencentは2024年7月1日に新たなネットワーク処理システム「Xingmai 2.0」を発表しました。Xingmai 2.0を採用したAIインフラストラクチャでは、従来のものと比べて通信効率が60%、AIモデルの学習効率が20%向上するとのこと。Tencentのテストでは、大規模なAIモデルの学習時間が50秒から40秒へ短縮できたとされています。

Xingmai 2.0にはTencentが開発した通信プロトコル「TiTa2.0」が採用されており、データの効率的な配分が可能です。また、TiTa2.0はデータの並列送信にも対応しているとのこと。さらに、Xingmai 2.0は新開発のネットワークスイッチや光通信モジュールを採用することで帯域幅が拡大しており、単一クラスタで10万台以上のGPUを管理できます。
AI計算処理の分野ではアメリカ企業のNVIDIAが大きな存在感を示していますが、アメリカは中国に対して高性能半導体の輸出を制限しており、中国に拠点を置く企業がNVIDIA製の高性能半導体を入手することは困難となっています。このため、TencentがGPUの増強ではなくネットワーク処理の改善でAI処理性能を向上できた点は注目に値します。
また、South China Morning Postは、「AIの学習はエネルギーを大量に消費する。AIインフラストラクチャの処理効率を向上することはエネルギーコストの削減につながるため、価格競争において極めて重要である」と指摘しています。
・関連記事
NVIDIAは2024年に中国でH20チップを100万個販売して2兆円を売上げる予定、HuaweiのAIチップの2倍を販売して存在感を示す - GIGAZINE
HuaweiがHBMチップ開発で中国のファウンドリ武漢新信半導体製造と提携、制裁を回避する体制確立へ - GIGAZINE
HuaweiがAIを統合した「HarmonyOS NEXT」のベータ版と独自LLMの「Pangu Large Model 5.0」を正式に発表 - GIGAZINE
OpenAIがロシア・中国・北朝鮮などサポート対象外の国からのアクセスを無期限でブロックすると発表 - GIGAZINE
中国製GPUで学習した純中国製LLM「MT-infini-3B」が「Llama3-8B」を超える性能を示し中国単独で高性能AIを開発できることが明らかに - GIGAZINE
中国の生成AI特許出願数は3万8000件以上でぶっちぎりの世界1位、2位のアメリカの6倍近く - GIGAZINE
・関連コンテンツ








in AI, ハードウェア, Posted by log1o_hf
You can read the machine translated English article Chinese IT giant Tencent improves AI lea….