




音声・テキスト・画像・音楽の入出力に対応したマルチモーダル大規模言語モデル(LLM)「AnyGPT」が登場
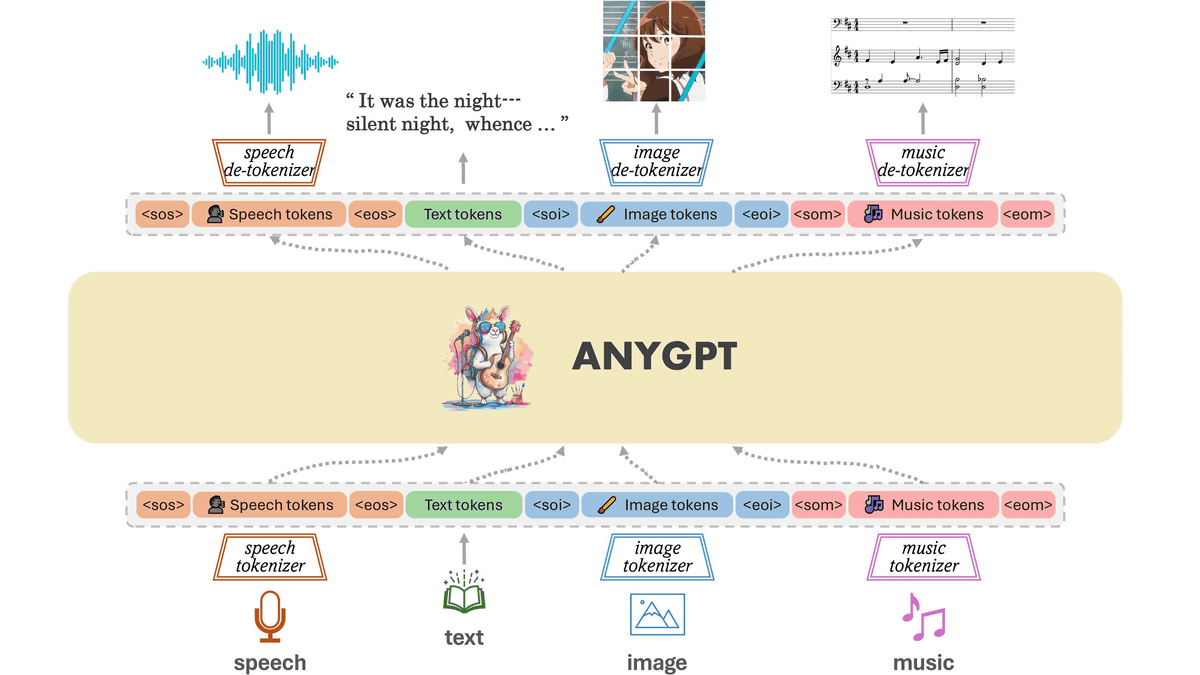
音声・テキスト・画像・音楽など複数の種類のデータを一度に処理できるマルチモーダルな大規模言語モデル(LLM)の「AnyGPT」が発表されました。
AnyGPT
https://junzhan2000.github.io/AnyGPT.github.io/
既存の大規模言語モデル(LLM)のアーキテクチャやトレーニングパラダイムを変更することなく、安定してトレーニングすることができるという新しいマルチモーダルLLMがAnyGPTです。AnyGPTはデータレベルの前処理のみに依存しており、新しい言語を組み込むのと同様に、新しいモダリティのLLMへのシームレスな統合を促進することが可能。マルチモーダルアライメントの事前トレーニング用に、マルチモーダルテキスト中心のデータセットを構築することで、生成モデルを利用して大規模な「Any-to-Any」(任意のデータ形式から任意のデータ形式に出力できる)マルチモーダル命令データセットを構築します。
AnyGPTのマルチモーダル命令データセットは、さまざまなモダリティを複雑に織り交ぜたマルチターン会話の10万8000サンプルで構成することで、モデルがマルチモーダルな入力と出力の任意の組み合わせを処理することを実現しました。なお、開発チームはAnyGPTがあらゆるモダリティにわたって特殊化されたモデルに匹敵するパフォーマンスを達成しながら、「Any-to-Any」マルチモーダルな会話を促進できることを示しており、離散表現がLLM内の複数のモダリティを効果的かつ便利に統合できることを実証することに成功しています。
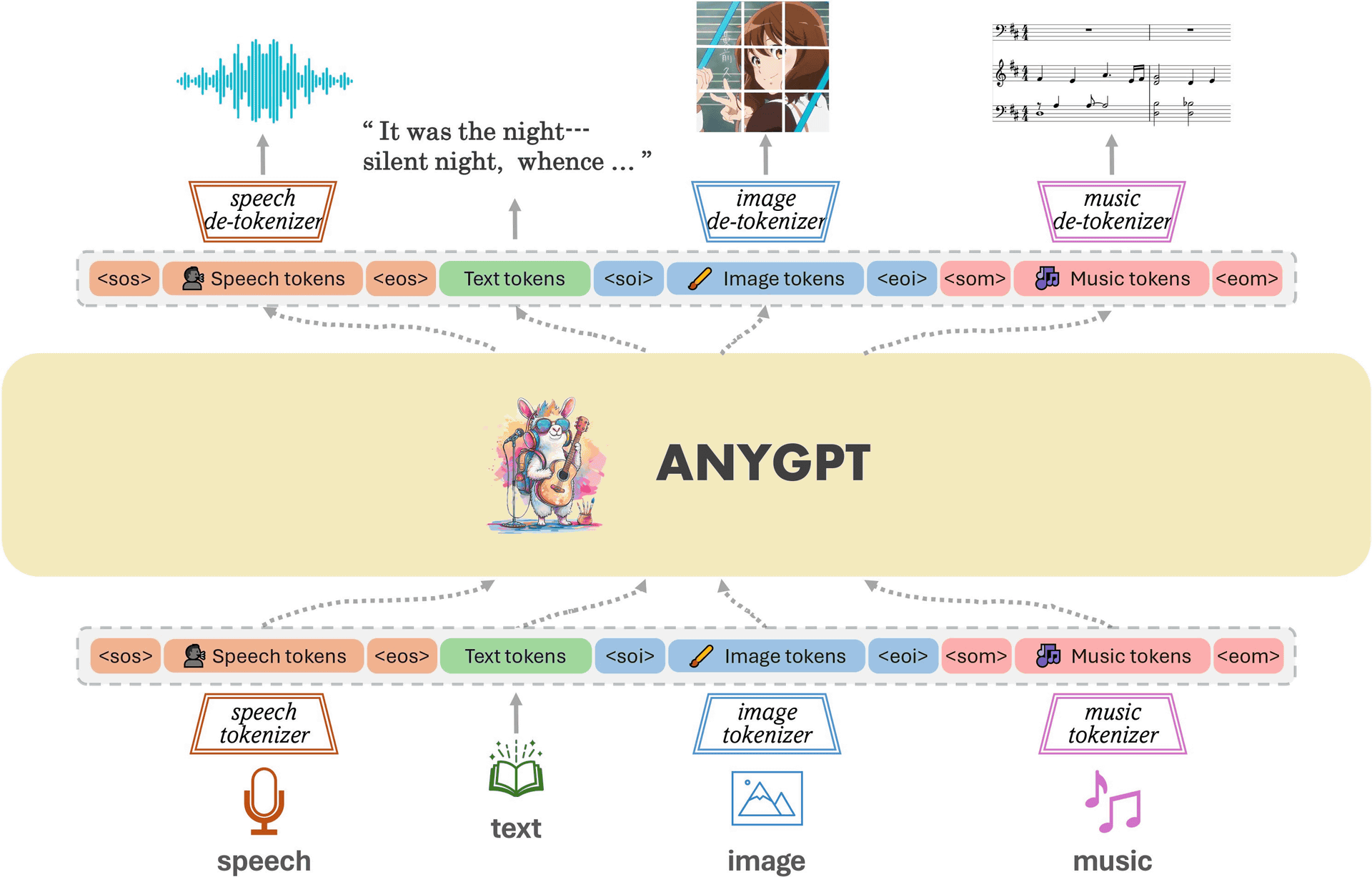
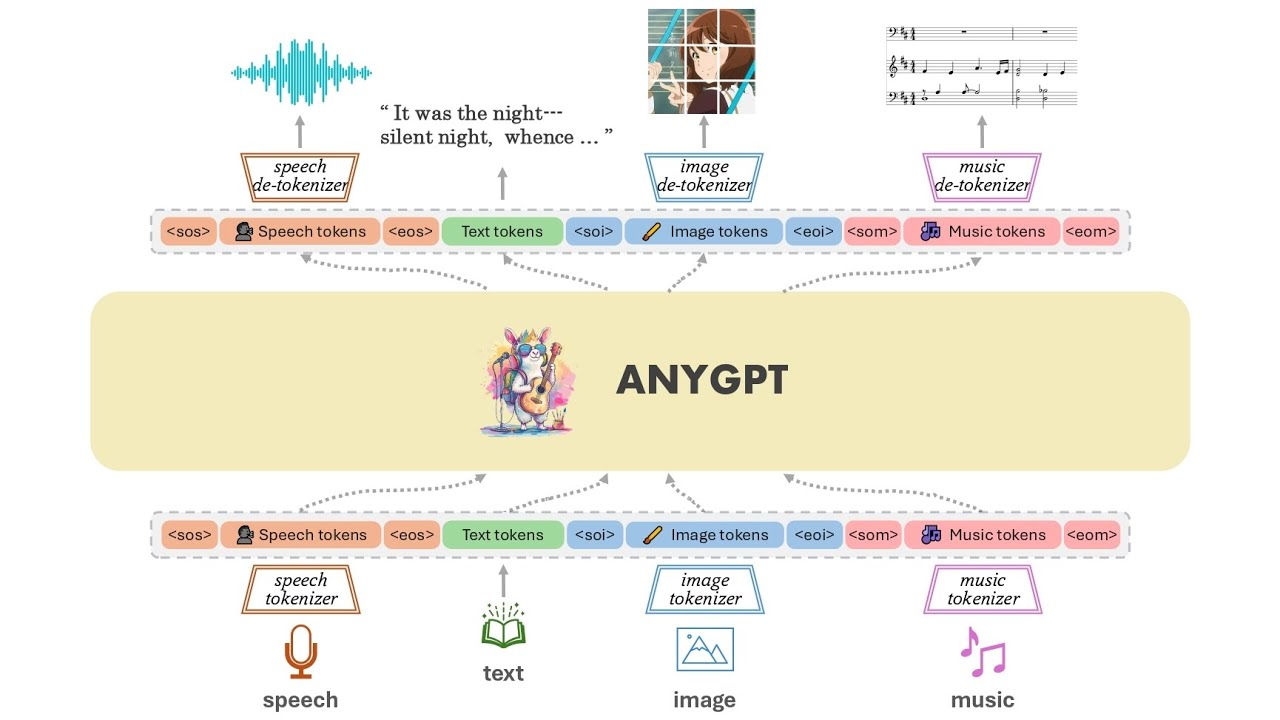
AnyGPTのモデルアーキテクチャの概要を示したのが以下の図。AnyGPTは音声・テキスト・画像・音楽という複数の種類のデータを個別にトークン化しており、これに基づいてLLMがマルチモーダルの理解と生成を自己回帰的に実行します。データの前処理と後処理のみが必要で、モデルのアーキテクチャとトレーニングの目標を変更する必要はありません。
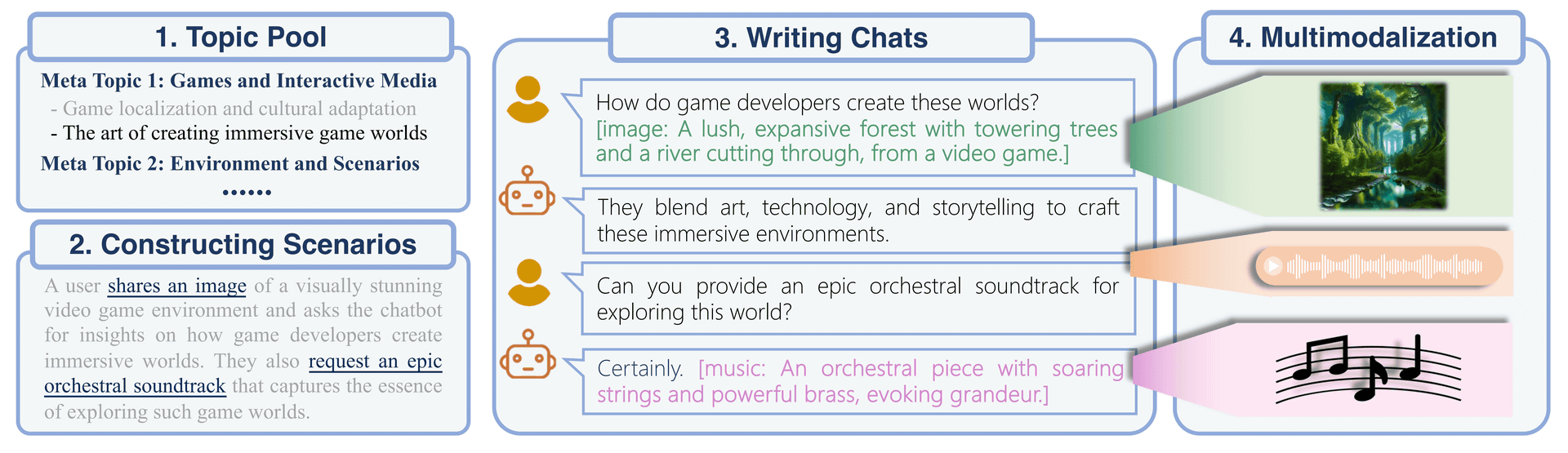
AnyGPTのマルチモーダル命令データセットは「AnyInstruct」と呼ばれており、これの構築プロセスは「マルチモーダル要素を組み込んだテキストベースの対話の生成」と、「テキストからマルチモーダルへの変換」という2つの段階に分かれています。第1段階の「マルチモーダル要素を組み込んだテキストベースの対話の生成」ではトピック・シナリオ・テキスト形式の対話が生成され、第2段階の「テキストからマルチモーダルへの変換」では最終的なマルチモーダル対話が生成されます。
AnyGPTはマルチモーダルLLMであるため、音声・テキスト・画像・音楽からさまざまな形式のデータを出力することができます。プロンプトでは複数のデータ形式を入力することもでき、例えば「この画像から音楽を生成してください」や「この音楽を画像に変換してください」といったプロンプトも利用可能です。
実際、AnyGPTでどんな音声・テキスト・画像・音楽を出力できるのかは、以下の動画のデモンストレーションで示されています。
Demo for "AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling" - YouTube
「最近疲れてるのですがリラックスするにはどこが適していると思いますか?」という音声テキストを入力した際に出力された画像が以下。

他にも、音楽ファイルを入力して「この音楽を画像に変換できますか?」と音声で入力した際に出力された画像が以下。

さらに、以下の画像を入力して、これを「音楽に変換してください」と入力。

その結果出力された音楽が以下です。
・関連記事
大規模言語モデル(LLM)を爆速で動作させる「言語処理ユニット(LPU)」を開発する「Groq」が爆速アルファデモを公開 - GIGAZINE
Appleは大規模言語モデルをiPhone上でローカルに動作させることを目指している - GIGAZINE
大規模言語モデル(LLM)に精度・知識の更新速度・回答の透明性などを与える「RAG(検索拡張生成)」 - GIGAZINE
ネット上に流出した大規模言語モデルは自社製のものだとAI企業・MistralのCEOが確認 - GIGAZINE
101言語に対応したオープンソースの大規模言語モデル「Aya」をCohere for AIがリリース - GIGAZINE
・関連コンテンツ








in 動画, ソフトウェア, Posted by logu_ii
You can read the machine translated English article Introducing AnyGPT, a multimodal large-s….