Introducing AnyGPT, a multimodal large-scale language model (LLM) that supports input and output of audio, text, images, and music.
AnyGPT , a
AnyGPT
https://junzhan2000.github.io/AnyGPT.github.io/
AnyGPT is a new multimodal LLM that can be trained stably without changing the architecture or training paradigm of existing large-scale language models (LLMs). AnyGPT relies solely on data-level preprocessing and can facilitate seamless integration of new modalities into LLM, as well as incorporating new languages. By building multimodal text-centric datasets for multimodal alignment pre-training, generative models can be used to generate large-scale “any-to-any” output. ) Build a multimodal instruction dataset.
AnyGPT's multimodal instruction dataset consists of 108,000 samples of multiturn conversations with a complex interweaving of different modalities, allowing models to handle any combination of multimodal inputs and outputs. Did. Additionally, the development team has shown that AnyGPT can facilitate 'Any-to-Any' multimodal conversations while achieving performance comparable to specialized models across all modalities, meaning that discrete representations can be We have successfully demonstrated that modalities can be effectively and conveniently integrated.
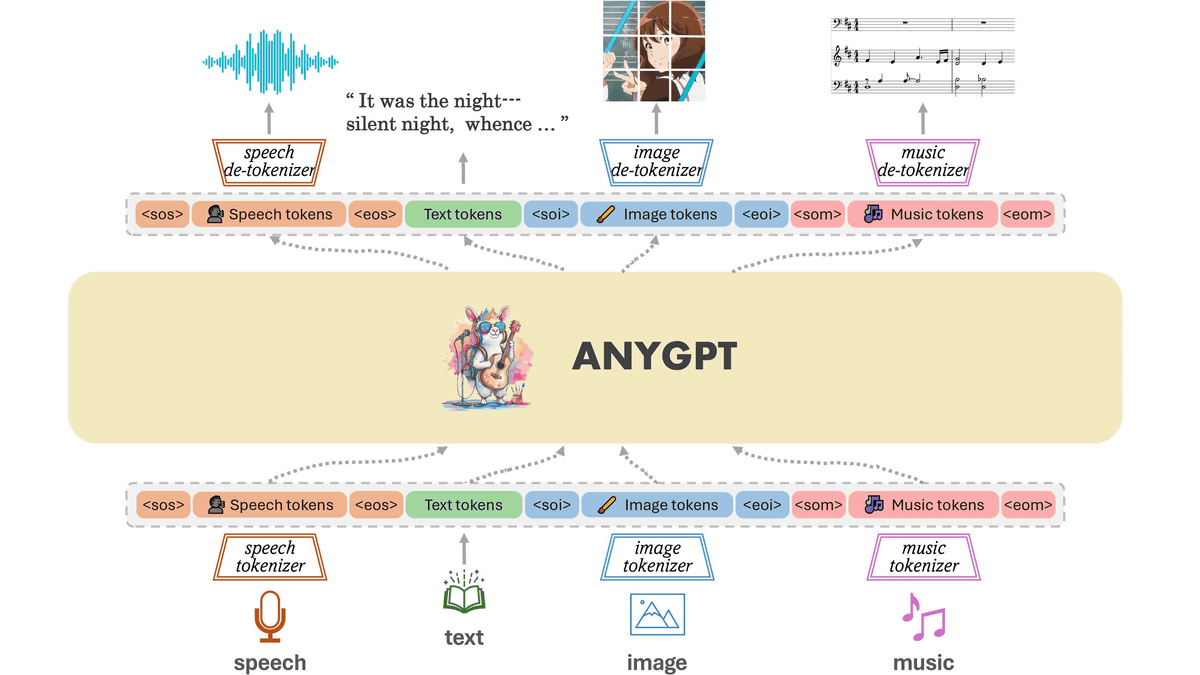
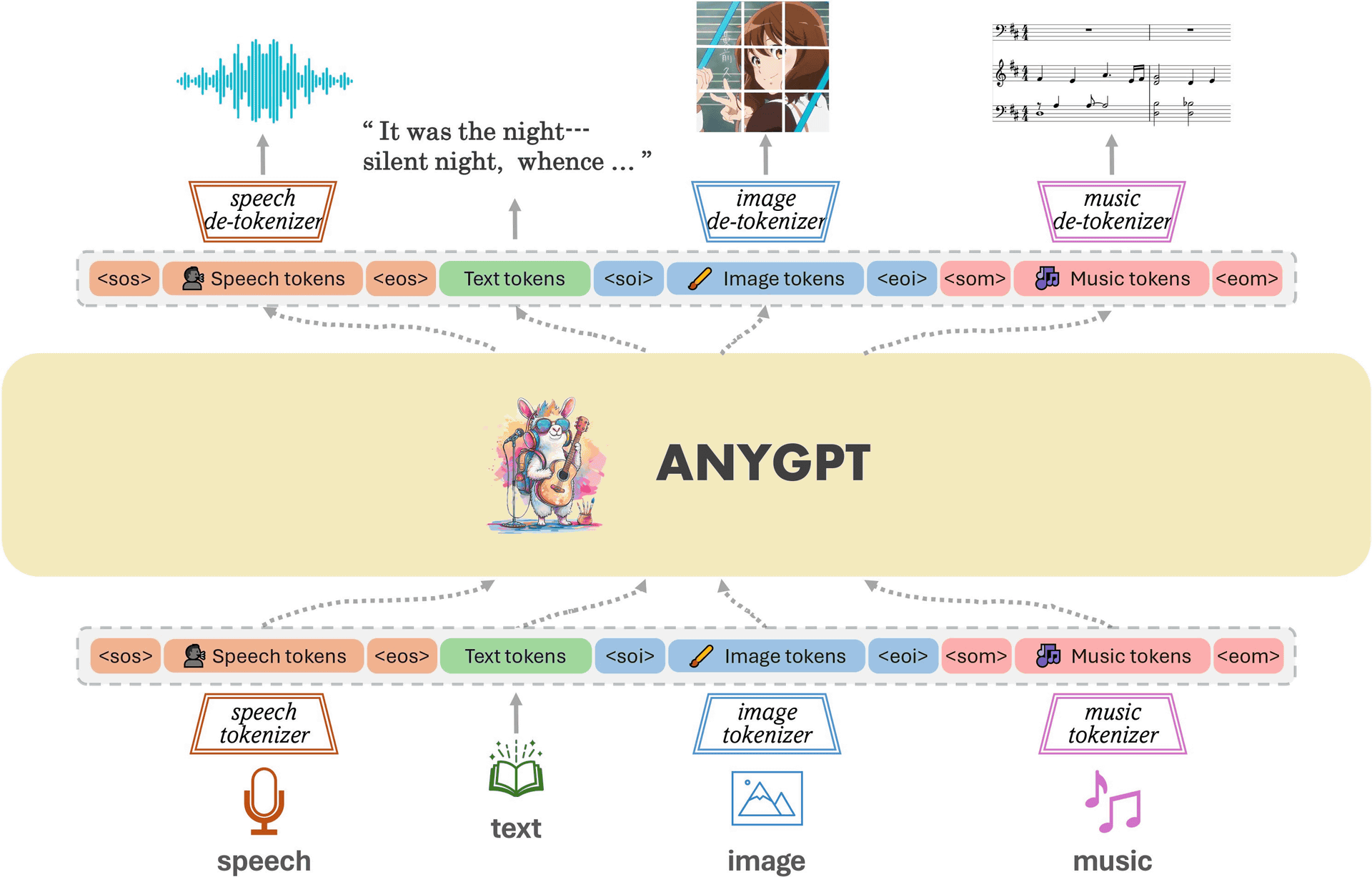
The figure below shows an overview of AnyGPT's model architecture. AnyGPT individually tokenizes multiple types of data such as audio, text, images, and music, and based on this, LLM performs multimodal understanding and generation in an autoregressive manner. Only data pre- and post-processing is required; no changes to the model architecture and training goals are required.
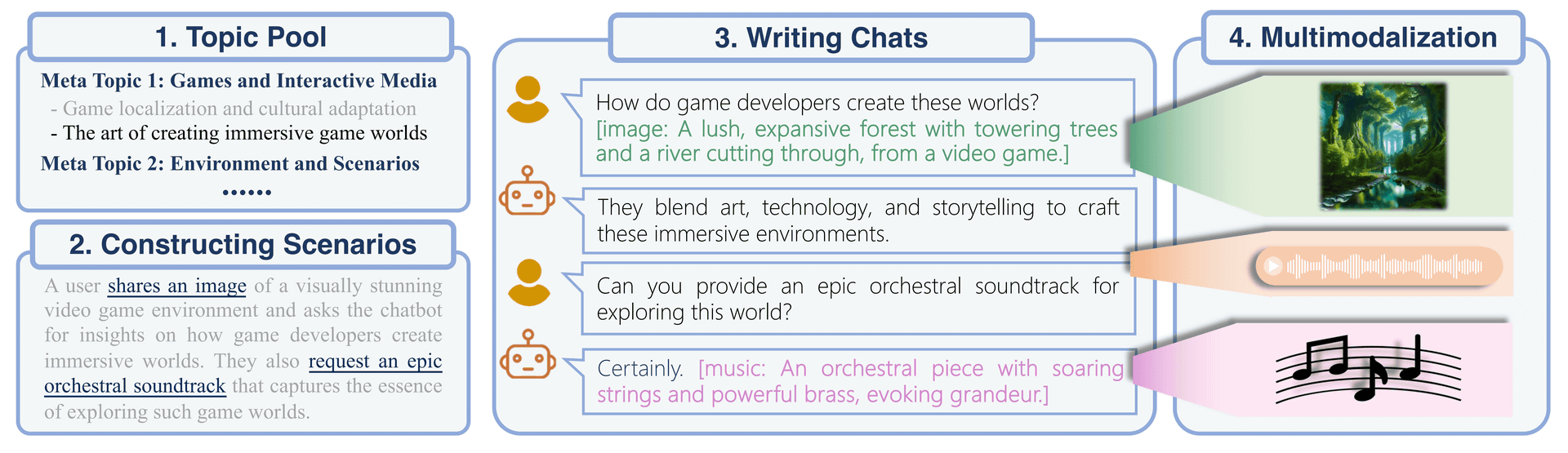
AnyGPT's multimodal instruction dataset is called 'AnyInstruct', and its construction process consists of two steps: 'generation of text-based interactions incorporating multimodal elements' and 'text-to-multimodal conversion'. Divided into stages. The first stage, 'Generation of text-based dialogue incorporating multimodal elements,' generates topics, scenarios, and text-based dialogue, and the second stage, 'Text-to-multimodal conversion,' generates the final multimodal dialogue. A dialogue is generated.
Since AnyGPT is a multimodal LLM, it can output data in various formats from audio, text, images, and music. Prompts can also accept multiple data formats, such as 'Generate music from this image' or 'Convert this music to an image.'
In fact, the video demonstration below shows what kind of audio, text, images, and music can be output with AnyGPT.
Below is the image output when inputting the voice text 'I've been feeling tired lately, where do you think is a good place to relax?'

In addition, below is the image output when inputting a music file and inputting the question 'Can you convert this music to an image?' by voice.

Furthermore, enter the image below and enter 'Please convert it to music'.

The resulting music is below.
Related Posts:







