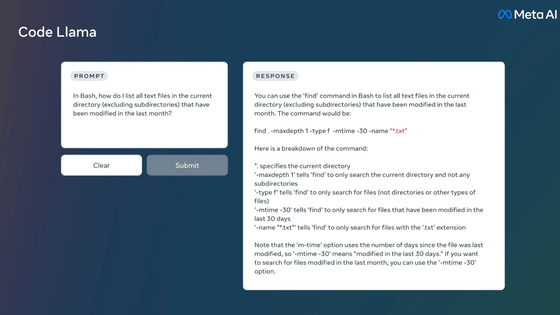
Meta announces generation AI 'CM3leon' that can handle both 'text to image' and 'image to text' with one model

Introducing CM3leon, a more efficient, state-of-the-art generative model for text and images
https://ai.meta.com/blog/generative-ai-text-images-cm3leon/
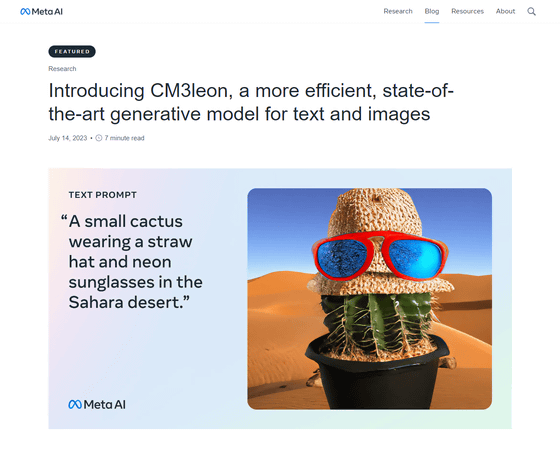
Introducing CM3leon, a first-of-its-kind multimodal model that achieves state-of-the-art performance for text-to-image generation with 5x the compute efficiency of competitive models.
—Meta AI (@MetaAI) July 14, 2023
More details ➡️ https://t.co/VR12zkmLDs pic.twitter.com/jUnG7G1Fxf
Meta claims its new art-generating model is best-in-class | TechCrunch
https://techcrunch.com/2023/07/14/meta-generative-transformer-art-model/
Meta reveals new AI image generation model CM3leon, touting greater efficiency | VentureBeat
https://venturebeat.com/ai/meta-reveals-new-ai-image-generation-model-cm3leon-touting-greater-efficiency/
CM3leon is the first multimodal model trained using a text-only language model, including REALM and a second multitask fine-tuning (STF) stage.
CM3leon generates a simple yet powerful model, allowing tokenizer- based transformers to be trained as efficiently as existing diffusion models. Furthermore, it can be trained with 5x less compute than Transformer-based training and still achieve performance similar to state-of-the-art models in terms of text-to-image generation performance.
CM3leon also possesses the versatility and effectiveness of autoregressive models while maintaining low training cost and inference efficiency. It is also a causal mask mixed modal (CM3) model, Meta explains, because it can generate text image sequences conditional on arbitrary sequences of other images and text content.
In general, text-only generative AIs have multitasking instructions tailored to different tasks to improve their ability to follow instructional prompts. On the other hand, it seems that the image generation model is specialized for a specific task. On the other hand, CM3leon applies large-scale multitasking instruction tuning so that it can generate both text and images. The performance of base editing, conditional image generation, etc. has been significantly improved.
Comparing performance with zero-shot MS-COCO, the most widely used image generation benchmark, CM3Leon achieves a FID (Fréchet Inception Distance) score of 4.88, which is excellent for generating images from text. It achieves the same level of performance as the most advanced models. In addition, it seems that this exceeds the performance of ' Parti ' which is Google's image generation AI.
CM3Leon can not only generate images with complex components, such as 'a small cactus with a straw hat and sunglasses in the Sahara Desert', but also responds to visual questions, long-form captions, and various other images. It can demonstrate excellent performance such as visual language tasks. This seems to be the same even when training with a dataset consisting of only 3 billion text tokens.

With CM3leon, image generation tools can generate 'consistent images that closely follow input prompts.' Regarding this, Meta said, ``Many image generation models struggle with the ability to recover global shapes and local details. Tasks can be executed with one model.'
Meta lists the following seven tasks that CM3leon is good at.
◆ Create and edit images with text guides
Image generation becomes very difficult for complex objects or when prompts must contain all constraints. If you use CM3leon's text-guided image editing function, you can edit images by inputting things like 'change the color of the sky to bright blue.' This is possible because CM3leon's AI models understand both textual instructions and visual content at the same time.
◆ Generate images from text
CM3leon is able to follow prompts and generate consistent images even when given highly structured prompts. Below is an example of an image actually generated from text with CM3leon, from the left 'Small cactus wearing a straw hat and sunglasses in the Sahara Desert' 'Close-up photo of human hands. High quality' 'Epic battle A cartoon-style raccoon with a katana preparing for a 'fantasy-style stop sign with the number 1991' prompt-generated image.

◆ Text-based image editing
If both image and text prompts are present, follow the text instructions to edit the image. The great thing about CM3leon is that it also does this in a single model, unlike models such as
Below is an example of text-based image editing. From the left, the original image, the image edited with the text ``Looks like a man with a beard'', ``Wears sunglasses'', ``Looks 100 years old'', and ``Face paint'' .

◆ Text task
CM3leon can answer questions about images by generating short or long captions according to various prompts. For example, in the image below where the dog has a stick, if you enter 'What is the dog carrying?', CM3leon will answer 'stick'. Furthermore, if you enter 'Please describe the image in great detail', CM3leon will say 'There is a dog with a stick in the image, grass is growing on the ground and trees can be seen in the background.' It seems to reply.

It is clear that the performance of generating text from CM3leon's images is comparable to that of existing AI models. Compared to
◆ Structure-based image editing
Structure-based image editing involves understanding and interpreting structural and layout information used as input as well as textual instructions. CM3leon adheres to specified structure and layout guidelines, while providing visually consistent, contextually appropriate edits to images.
◆From object to image
You can also generate an image with a text description of the bounding box segmentation of the image.
For example, when generating a 'room with a washstand and a mirror', it is possible to specify the positions of the objects (washstand, bottle, bed) included in the image.

◆ From segmentation to images
It is also possible to specify an image that contains only segmentation and generate an image. The images below are, from the left, the input image, the segmentation output based on the input image, and the image 1 and 2 output based on the segmentation.

Meta said, “Models like CM3leon could ultimately help improve creativity and create better applications in the metaverse. We look forward to releasing many models.' It is unclear if and when Meta plans to release CM3leon.
Related Posts: