Microsoft uses 'AI that adds descriptive text to images with higher accuracy than humans' to improve Word, Outlook, etc.

Microsoft has reported on its official blog that it has built a new 'caption-generating artificial intelligence (AI) model' that can add more accurate descriptions to images in many cases than humans.
What's that? Microsoft's latest breakthrough, now in Azure AI, describes images as well as people do --The AI Blog
Microsoft's new image-captioning AI will help accessibility in Word, Outlook, and beyond --The Verge
https://www.theverge.com/2020/10/14/21514405/image-captioning-seeing-ai-microsoft-algorithm-word-powerpoint-outlook
'The system for adding captions to images is one of the core computer vision features that enable a wide range of services,' said Xuedong Huang , a technical fellow and CTO at Microsoft.
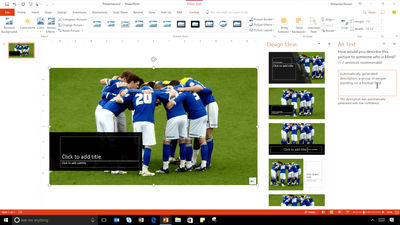
Microsoft's newly built caption-generating AI model will be available through the computer vision offering of Azure Cognitive Services , which is part of the Azure AI service. Developers can also use this feature to improve the accessibility of their own services. The caption generation AI model has already been incorporated into the camera app ' Seeing AI ' for the visually impaired developed by Microsoft, and in the latter half of 2020, Microsoft Word and Outlook for Windows / macOS, and PowerPoint for Windows / macOS / web Will be incorporated into.
Japanese version of Seeing AI
Microsoft's caption-generating AI model allows you to add captions to any image, from images displayed on search engines to photos embedded in PowerPoint. Saqib Shaikh , Software Engineering Manager, AI Platform Group at Microsoft, said, 'Using the ability to add captions to images to generate photo descriptions embedded in web pages and documents can be a blind person or It's especially important for people with poor eyesight. '
The team led by Mr. Shaikh seems to have worked on incorporating a caption generation AI model into Seeing AI. Seeing AI generates captions for what is projected through the camera, helping blind people to see what is in front of them. 'Ideally, every image on a document, web, or social media should have a caption, which gives the visually impaired access to all the information, and it's commonplace. But unfortunately people don't, so how many apps provide image captions as a way to explain what's missing. There is, 'he said, arguing the importance of applications like Seeing AI that caption images.
In addition, the caption generation AI model created by Microsoft is a benchmark for image captions, nocaps , and has a score equal to or higher than that of humans. In addition, nocaps measures the score by 'how accurate caption can be attached' to the image that is not included in the dataset used by the AI model for training. The caption-generating AI model pre-trains the AI model by using a rich dataset of images paired with word tags to enhance the mapping between word tags and specific objects.
Regarding Microsoft's method of 'strengthening the mapping between word tags and specific objects,' Wang said, 'For example, it is similar to teaching children about cats using a book with a picture of a cat and the letters' cat 'printed on it. I am. '
The AI model, which has been learned word by word in advance, will improve the accuracy of captions by training using a dataset of images with captions. As a result, Microsoft's caption generation AI can generate accurate captions even for new images by utilizing natural vocabulary.
In the following movie, an example of what kind of caption was actually generated by the caption generation AI model created by Microsoft is summarized.
Microsoft AI breakthrough in automatic image captioning --YouTube
For the following city landscape photos, the conventional caption generation AI model is captioned as 'cityscape' and the new AI model is captioned as 'train running in the city'.

In the photo below, the old AI model correctly captioned 'clock on the roof', while the new AI model correctly described it as 'a statue on top of the building'.

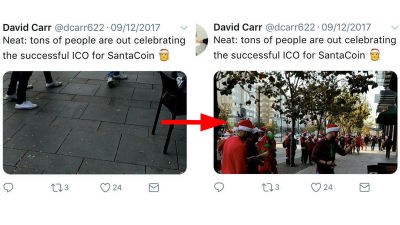
In the photo of American football players celebrating the moment of victory, the old AI model 'a group of baseball players is standing on the grass' and the new AI model 'a group of American football players are celebrating'.
In the photo of the cat, the old AI model could only explain 'up photo of the cat', but the new AI model explained more accurately to the photo that 'the gray cat has closed eyes'. I'm adding.

Also, using another benchmark widely used in the industry, Microsoft's new caption-generating AI model is twice as good as the image caption model used in Microsoft products since 2015. It seems to be.
Related Posts: