




テキスト・画像から3Dモデルを作成するAI「Shap-E」をGoogle Colaboratoryで使ってみた
チャットAIのChatGPTや音声認識AIのWhisperを開発するOpenAIが2023年5月に3Dモデル作成AI「Shap-E」を発表しました。Shap-Eはオープンソースで開発されており、誰でも利用可能とのことなので実際にGoogle Colaboratory上で使ってみました。
shap-e/sample_text_to_3d.ipynb at main · openai/shap-e · GitHub
https://github.com/openai/shap-e/blob/main/shap_e/examples/sample_text_to_3d.ipynb
Shap-Eでどんなことができるのかについては下記の記事が詳しいです。
テキストや画像から3Dモデルを生成するオープンソースのAI「Shap-E」をOpenAIが発表 - GIGAZINE

まずはGoogleドライブにアクセスし、右端の「+」マークをクリック。
検索欄に「Colaboratory」と入力し、表示されたColaboratoryアプリをクリックします。
「インストール」をクリック。
権限を求められるので「続行」をクリックします。
Colaboratoryをインストールするアカウントを選択。
これでインストール完了です。「完了」をクリック。
Googleドライブ画面の左端にある「新規」をクリックします。
「その他」に「Google Colaboratory」が追加されているのでクリック。
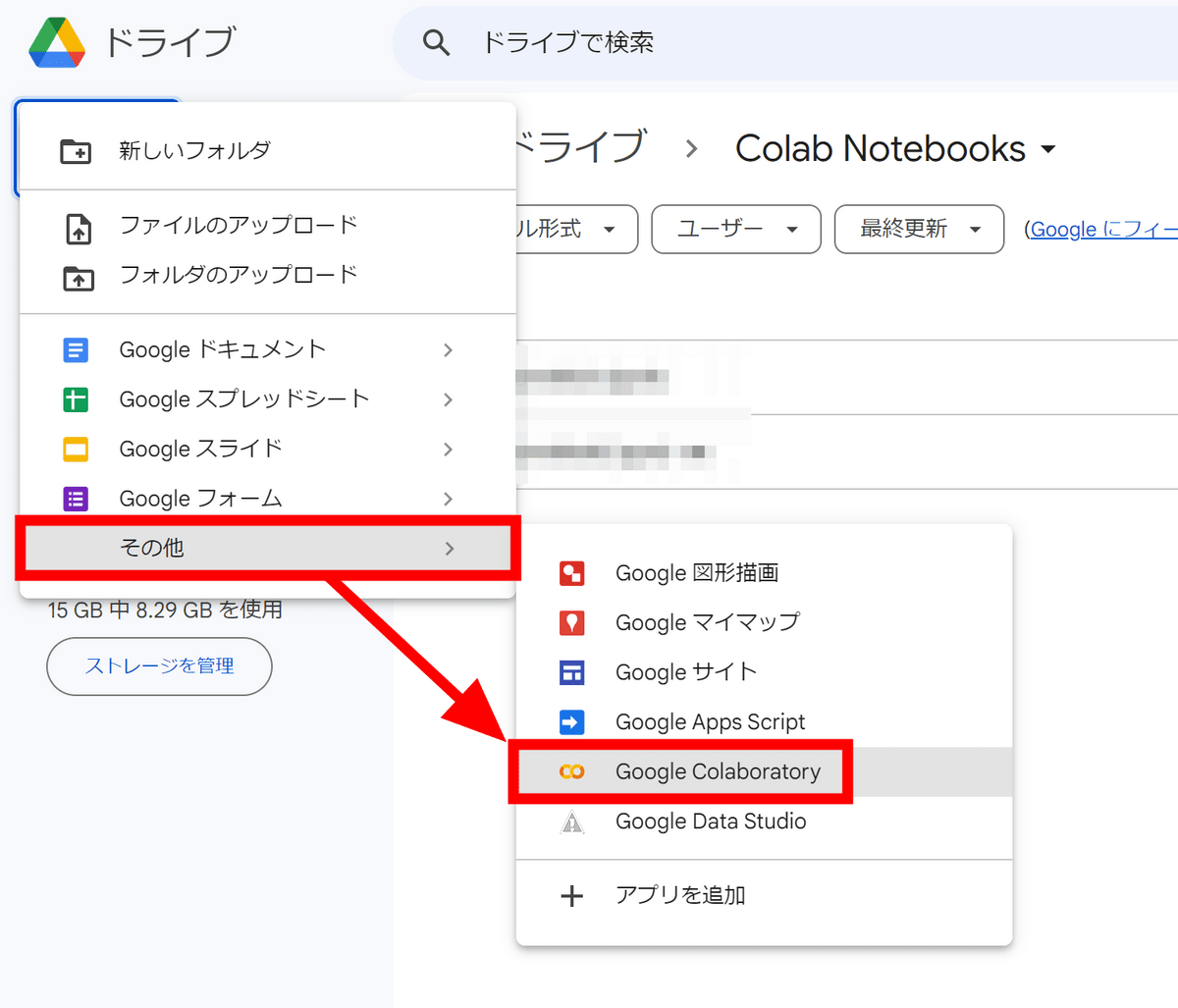
Colaboratoryが開いたら、まずGPUを利用する設定に変更します。「ランタイム」メニューの「ランタイムのタイプを変更」をクリック。
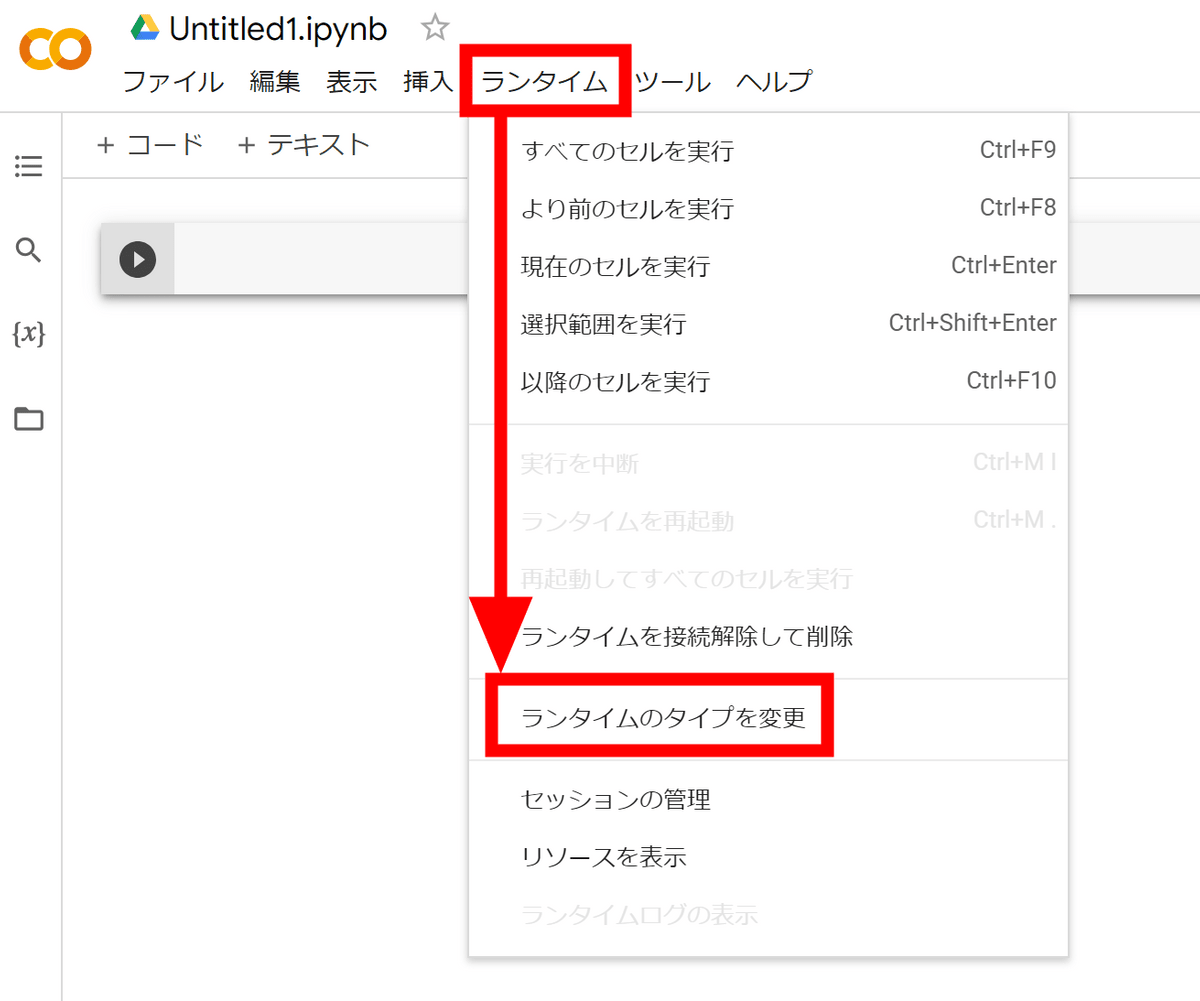
「ハードウェア アクセラレータ」欄を「GPU」にして「保存」をクリックします。

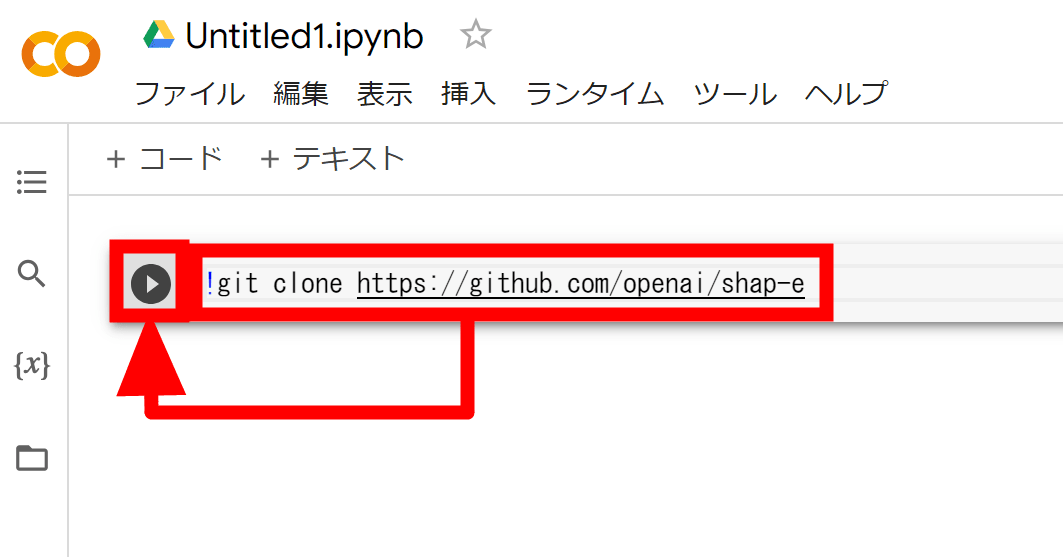
ここからはPythonのコードを入力していきます。まずはShap-Eのデータをインポートするので、入力するコードは下記の通り。
!git clone https://github.com/openai/shap-e
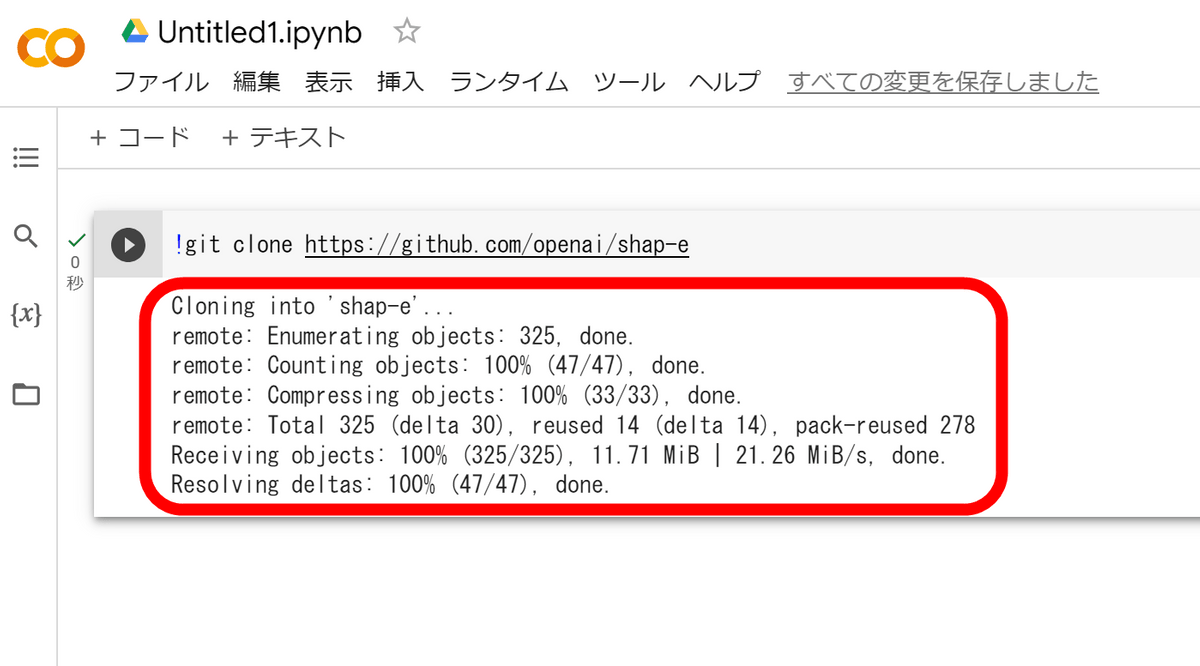
Colaboratoryでは、右の枠内にコードを入力して左の再生マークをクリックすればコードが実行可能。
実行が完了すると、コードの下にログが表示される仕組みとなっています。
新たにコードを入力する際は、上の「+コード」ボタンでコードブロックを追加すればOK。
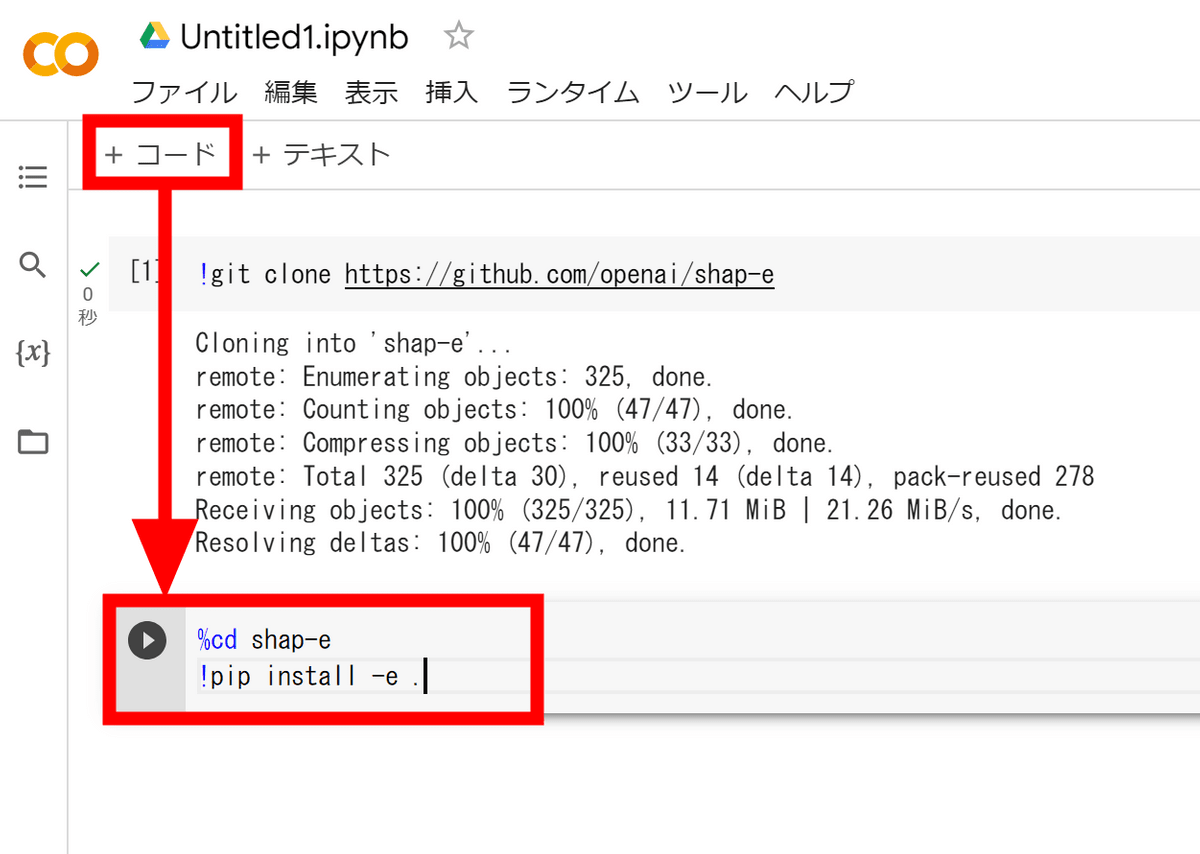
というわけで必要なライブラリを下記のコードでインストールします。
%cd shap-e
!pip install -e .
下記のコードでライブラリから必要な機能を読み込みます。
import torch
from shap_e.diffusion.sample import sample_latents
from shap_e.diffusion.gaussian_diffusion import diffusion_from_config
from shap_e.models.download import load_model, load_config
from shap_e.util.notebooks import create_pan_cameras, decode_latent_images, gif_widget
GPUを利用する設定を下記のコードで行います。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
3Dモデルを生成するのに利用するAIモデルをロードします。
xm = load_model('transmitter', device=device)
model = load_model('text300M', device=device)
diffusion = diffusion_from_config(load_config('diffusion'))
約2分程度でロードが完了しました。

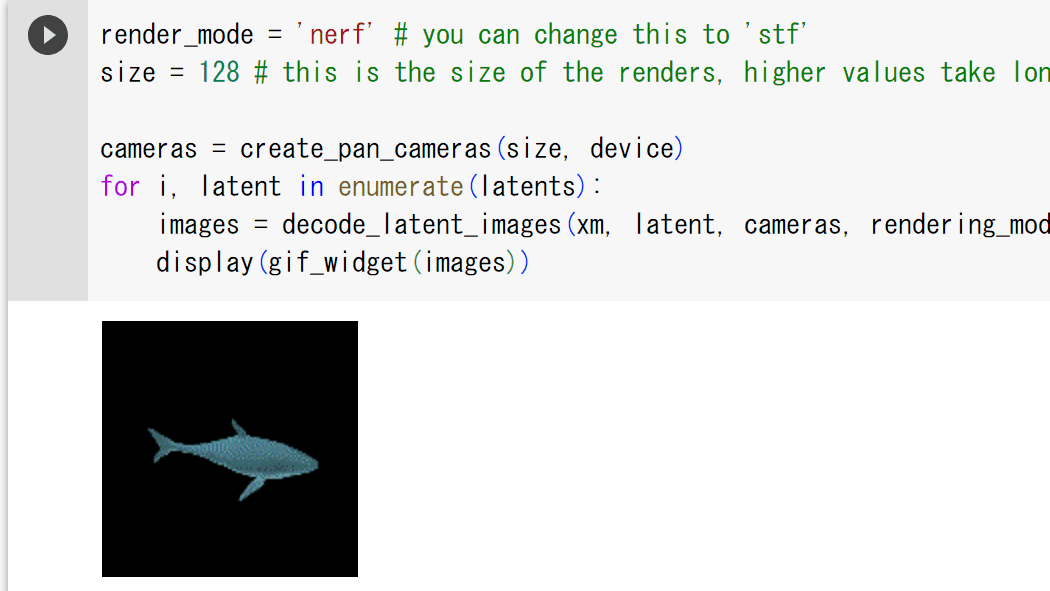
そして下記のコードで3Dモデルを生成します。「batch_size」は生成する3Dモデルの数で、「guidance_scale」はプロンプトへの忠実度を表しています。「prompt」でどんな3Dモデルを生成するかを指定可能。今回はサメを出力してみるので、「a shark」と入力しました。
batch_size = 1
guidance_scale = 15.0
prompt = "a shark"
latents = sample_latents(
batch_size=batch_size,
model=model,
diffusion=diffusion,
guidance_scale=guidance_scale,
model_kwargs=dict(texts=[prompt] * batch_size),
progress=True,
clip_denoised=True,
use_fp16=True,
use_karras=True,
karras_steps=64,
sigma_min=1e-3,
sigma_max=160,
s_churn=0,
)
今回の設定では23秒で3Dモデルの生成が完了しました。
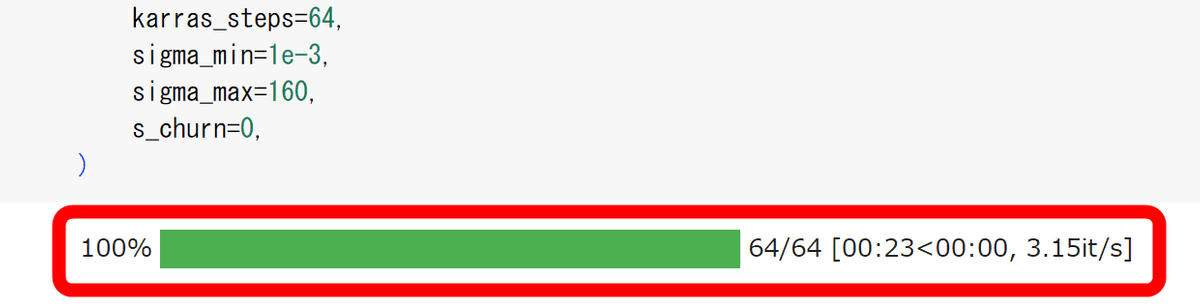
下記のコードを入力すると、生成された3Dモデルを回転するgif画像で表示してくれます。
render_mode = 'nerf' # you can change this to 'stf'
size = 64 # this is the size of the renders, higher values take longer to render.
cameras = create_pan_cameras(size, device)
for i, latent in enumerate(latents):
images = decode_latent_images(xm, latent, cameras, rendering_mode=render_mode)
display(gif_widget(images))
こんな感じのサメちゃんが生成されていました。

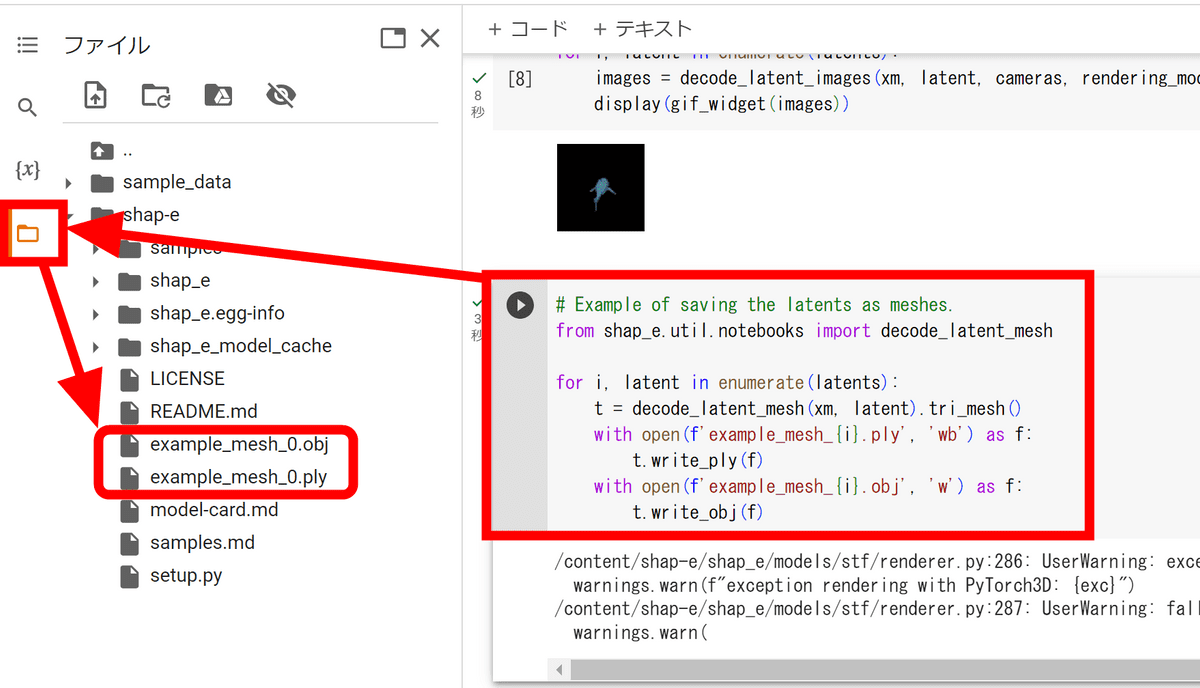
生成された3Dモデルを保存するには下記のコードを利用します。
from shap_e.util.notebooks import decode_latent_mesh
for i, latent in enumerate(latents):
t = decode_latent_mesh(xm, latent).tri_mesh()
with open(f'example_mesh_{i}.ply', 'wb') as f:
t.write_ply(f)
with open(f'example_mesh_{i}.obj', 'w') as f:
t.write_obj(f)
コードを実行すると、ファイル欄に「example_mesh_0」という名前でobjファイルとplyファイルが生成されます。
右クリックして「ダウンロード」をクリック。
後はダウンロードしてきたファイルを3Dモデル編集ソフトに取り込めばOKというわけです。今回はテキストから3Dモデル作成する手順を行いましたが、画像から3Dモデルを作成する例もShap-Eのリポジトリに入っているので、気になる人は確認してみてください。
・関連記事
テキストを入力するだけで3Dモデルを生成できる3D自動生成AI「DreamFusion」 - GIGAZINE
文章を入力するだけで実在の人物やアニメキャラクターの頭部3Dモデルを生成できるAI「HeadSculpt」 - GIGAZINE
たった1枚の画像から別視点の画像を生成するAIモデル「Zero-1-to-3」をトヨタ・リサーチ・インスティテュートなどの研究チームが開発 - GIGAZINE
3DCG製作ソフトのBlenderにGPT-4を統合し「球体を作って」などのプロンプトを入力するだけで3Dモデルを作成するアドオン「BlenderGPT」レビュー - GIGAZINE
AIにテキストを入力するだけで3Dの部屋が自動的に生成できる「Text2Room」が開発される - GIGAZINE
・関連コンテンツ


in AI, ソフトウェア, レビュー, Posted by log1d_ts
You can read the machine translated English article I tried using AI 'Shap-E' to create 3D m….