




TencentがWeChatにOpenClawベースのAIエージェントを統合した「微信ClawBot」を発表、10億人を超えるユーザーがWeCahtを通じてAIエージェントへの指示が可能
中国のTencentが同社のメッセージングプラットフォームであるWeChatにOpenClawを統合した新ツール「微信ClawBot」を発表しました。これにより、ユーザーはアプリを切り替えることなく、WeChatから対話を通じて様々なタスクを実行できるようになります。
Today, we are officially opening the capability to integrate #OpenClaw into #Weixin.
— WeChat (@Weixin_WeChat) March 22, 2026
With the launch of the #WeixinClawBot, users can use Weixin as a dedicated messaging channel for OpenClaw.
Now, you can send and receive messages with OpenClaw just like texting a friend.… pic.twitter.com/rIE0Tn3Amq
.@Weixin_WeChat now supports OpenClaw ????
— Tencent AI (@TencentAI_News) March 22, 2026
Install the #WeixinClawBot plugin, scan a QR code or run a command to connect, and you're all set to chat with ???? right in Weixin.
QClaw, WorkBuddy, Lighthouse and more are rolling out support. Give it a try. pic.twitter.com/8lKlFJLJTO
Tencent integrates WeChat with OpenClaw AI agent amid China tech battle | Reuters
https://www.reuters.com/technology/tencent-integrates-wechat-with-openclaw-ai-agent-amid-china-tech-battle-2026-03-22/
Tencent integrates OpenClaw into WeChat for Chinese users - The Economic Times
https://economictimes.indiatimes.com/tech/internet/tencent-integrates-openclaw-into-wechat-for-chinese-users/articleshow/129730190.cms
OpenClawはパソコン操作やスマートフォン連携による様々な作業を自動化できるAIエージェントフレームワークです。OpenClawは中国を中心に「ロブスターを育てる」という愛称で爆発的な流行を見せており、ハイテク都市で知られる広東省・深圳では中国の各企業がOpenClawの導入支援ツールを公開したり、OpenClawの新規セットアップを手助けするサービスが路上で提供されたりしていることが報じられました。
中国で「OpenClaw」ブーム到来、AI研究機関がOpenClawの導入支援ツールを公開して深圳ではOpenClawの初期設定を求める長蛇の列も - GIGAZINE

Tencentによれば、ユーザーは微信ClawBotを用いることで、検索エンジンや文書ツールを個別に起動する代わりに、WeChatの画面上でファイルの転送やメール送信、データ分析、予約といったアクションを完結させることが可能になるとのこと。
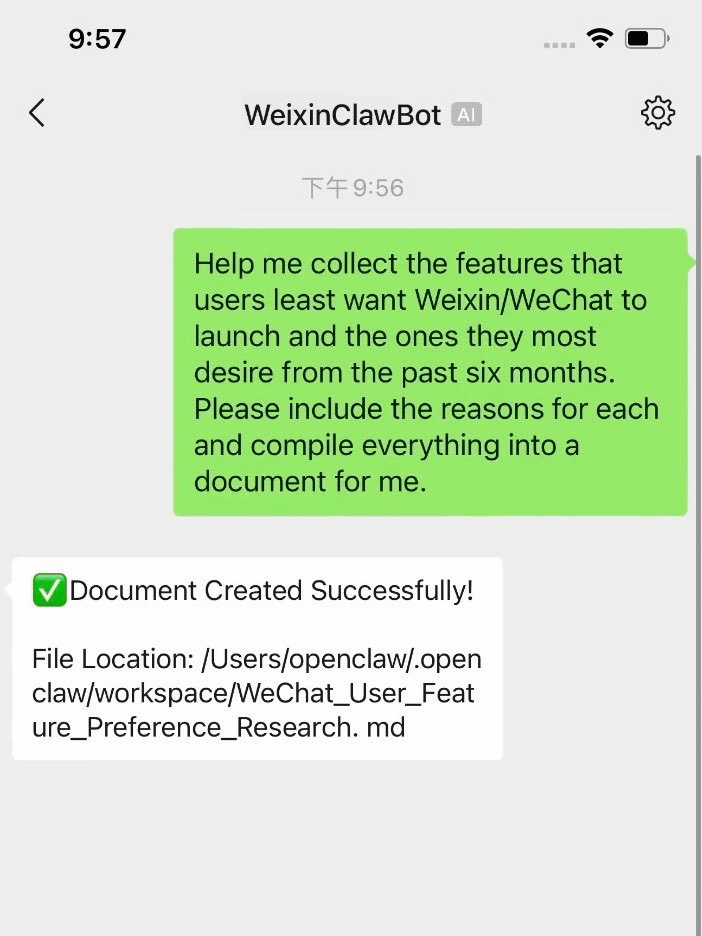
今回の動きは、AlibabaやBaiduといった競合他社がLLM(大規模言語モデル)の能力で先行する中、Tencentが日常生活に密着したアプリにエージェントAIを埋め込む戦略を強化していることを示唆しています。Alibabaは複雑なビジネスプロセスを調整するWukong(悟空)を、BaiduはOpenClawをベースにしたスマートホームやモバイル向けのエージェント製品をそれぞれ発表しており、中国のテック企業間ではAIエージェントが主要な主戦場となっています。
TencentはAIを重要な成長エンジンと位置付け、2025年の180億元(約4170億円)の投資に続き、2026年にはAI関連の資本支出を倍増させる計画を立てています。また、同時にユーザーのプライバシーや計算能力の確保に関する課題も認めているとのことです。
・関連記事
AIエージェントを美少女キャラつきのGUIで管理できる「OpenRoom」 - GIGAZINE
NVIDIAがオープンソースAIエージェントプラットフォーム「NemoClaw」発表、OpenClawを単一コマンドで導入でき安全性も確保 - GIGAZINE
中国の国営企業や政府機関がオフィス環境でのOpenClaw利用を制限する動き、中国全土でOpenClawの利用が広がりセキュリティ上の懸念が高まっているため - GIGAZINE
中国で「OpenClaw」ブーム到来、AI研究機関がOpenClawの導入支援ツールを公開して深圳ではOpenClawの初期設定を求める長蛇の列も - GIGAZINE
AIエージェント「OpenClaw」を予定チェック・グルチャの要約・価格アラート・冷蔵庫の管理などに使っている体験談 - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article Tencent has announced 'WeChat ClawBot,' ….