




DeepMindのAI「DeepNash」がコマの正体を隠す軍人将棋「ストラテゴ」をマスター

by SonnyandSandy
チェスや囲碁のようにコマの正体をプレイヤー同士が最初から把握できるものとは違い、お互いが持つコマの正体を隠しながら戦うボードゲーム「ストラテゴ」をAIがマスターしました。情報が隠されている分AIによる学習が非常に困難だったのですが、DeepMindが開発する「DeepNash」がクリアし、オンラインゲームで歴代トップ3に君臨しました。
Mastering the game of Stratego with model-free multiagent reinforcement learning | Science
https://www.science.org/doi/10.1126/science.add4679
ストラテゴは1対1のターンベースで進行するボードゲームです。将棋やチェスのように一つ一つ役割が違うコマをボード上に置いて動かしていくゲームですが、大きな特徴は「コマ同士が接触するまで相手のコマの正体が分からない」というもの。初期配置も好きなように決められるため、はったりなどの心理的要素を含めた戦略が重要になります。

by Scouse Smurf
一般的にチェスの最大棋譜数は10の120乗以上、将棋の最大棋譜数は10の220乗以上などといわれていますが、ストラテゴはその複雑さから、最大棋譜数は10の535乗以上にもなるとのこと。チェスや将棋、囲碁のようにコマの情報がすべて公開された「完全情報ゲーム」では、指手のパターンを考慮して解析する「ゲーム木探索」と呼ばれる手法が使われますが、ストラテゴのような情報が隠された「不完全情報ゲーム」でこの手法を使うのは困難です。
そのため、DeepNashは、ゲーム理論とモデルフリーな深層強化学習に基づく新しいアプローチを採用したとのこと。新たな学習を行ったDeepNashは「Regularised Nash Dynamics(R-NaD)」と呼ばれるアルゴリズムのアイデアが採用されており、そのプレイスタイルは「お互いが常に最も合理的な選択を行うと、お互いに戦略を譲らない状態となる」というナッシュ均衡に収束していくものだとのこと。相手にとっても非常に攻略しにくいスタイルに仕上がっているそうです。
ストラテゴのボードの一例はこんな感じ。各コマにはS(1)、2~10、B、Fの記号が割り当てられており、それぞれスパイ(S)、斥候(2)、元帥(10)、爆弾(B)、旗(F)などの名前が付けられています。10は9に強く、2はSに強いなど、基本的に数字の大きい方が小さい方のコマを取れるのですが、最弱のSは最強の10にのみ勝ち、10を取ることができます。2以外は上下左右に1マスずつ移動可能。BとFは動かせず、マイナー(3)のみがBを処理できます。相手の移動可能な全コマを取るか、相手のFを取れば勝ちというルールです。
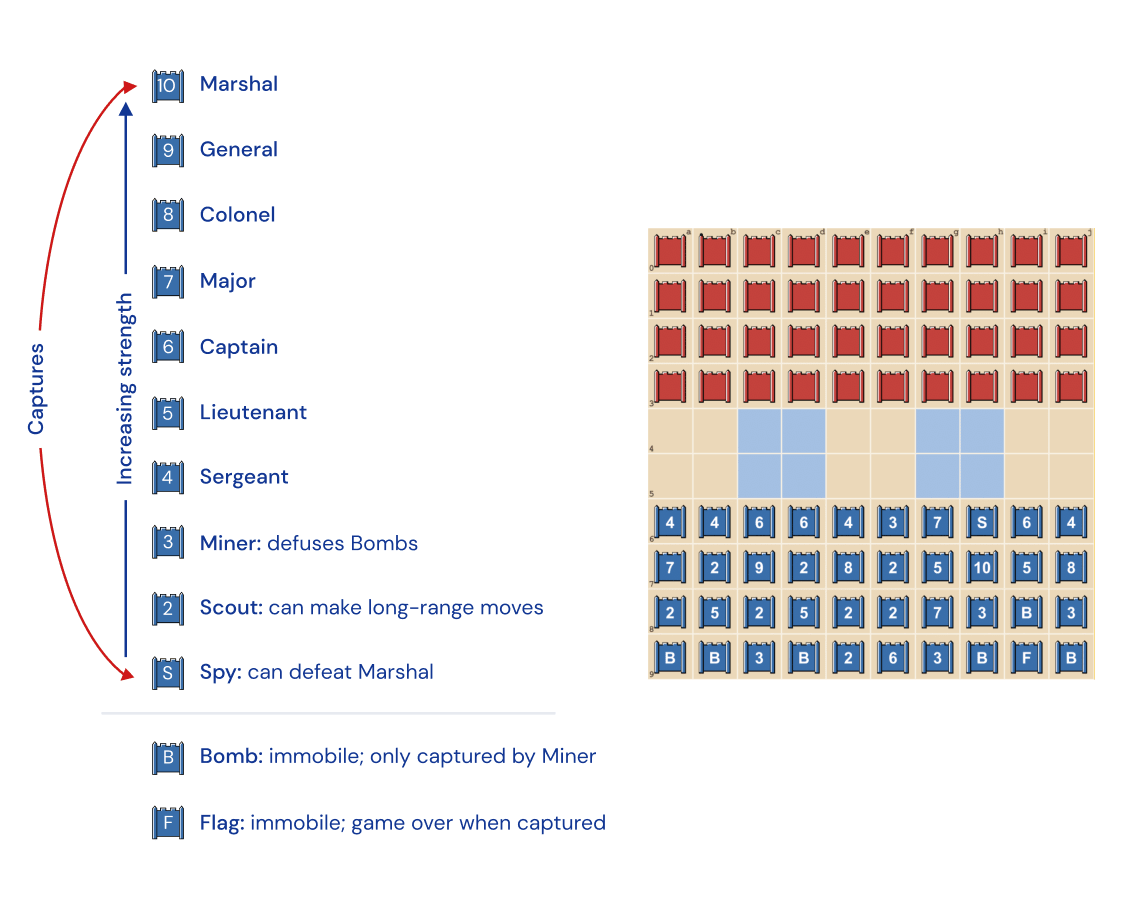
相手のコマと接触して初めて相手のコマの正体が分かるというルールから、はったりや綿密な情報収集、相手との駆け引きが重要となるゲームです。しかし、DeepNashが収束するナッシュ均衡という考え方は、「自分の戦略を変えない」というのが基本形。相手の戦略に惑わされることはありません。
さらに、DeepNashはコマの初期配置やコマ移動に驚くべき挙動を示したとのこと。初期配置では、DeepNashはあらゆる置き方を試して相手にパターンを見破られないようにし、コマ移動においては、一見すると同じように見える動かし方をランダムに繰り返し、相手に手の内を明かさないようにしたそうです。
DeepNashははったりもうまく使い、例えば相手の8を2で追いかけることで、相手に「これは10なのでは」と思わせるような戦略も行いました。この時、相手は10を取れるSで待ち構えていましたが、まんまと2に負けてしまいます。また、比較的強力な7と8のコマを犠牲にして脅威となる9や10を見つけ出すなど、多種多様な戦略を導き出しました。
世界選手権の勝者を含む対戦では、DeepNashの勝率は97%を超え、100%になることもしばしばでした。また、世界最大のオンラインストラテゴサイト「Gravon」における人間のトップエキスパートプレイヤーとの対戦では、DeepNashは84%の勝率を記録し、歴代トップ3の座を獲得しているそうです。
DeepNashはストラテゴのために開発されたものですが、今回DeepMindのジュリアン・ペロラット氏らが開発したR-NaD法は、ストラテゴのような他の不完全情報ゲームに直接適用することが可能だとのこと。ペロラット氏らは「ゲーム以外にも、大規模な交通管理における場面など、他者の意図が混在して何が起こっているか分からない領域においてもAIの新しい可能性を引き出すことができるのではないかと期待しています」と述べています。
論文共著者で元ストラテゴ世界選手権優勝者のビンセント・ボーア氏は「DeepNashのプレイレベルには驚かされました。AIが経験豊富な人間のプレーヤーのレベルに近づいていることを聞いたことがなかったからです。しかし、実際にDeepNashと対戦してみると、Gravonでトップ3の成績を収めたことには納得がいきました。人間の世界大会に参加させたら、きっといい成績を残してくれると思います」と語りました。
なお、DeepNashが人間と戦った際のゲームプレイ映像は以下から視聴可能です。これがDeepMindが公開した1戦目の映像。
DeepNash Stratego game 1 - YouTube

2戦目
DeepNash Stratego game 2 - YouTube
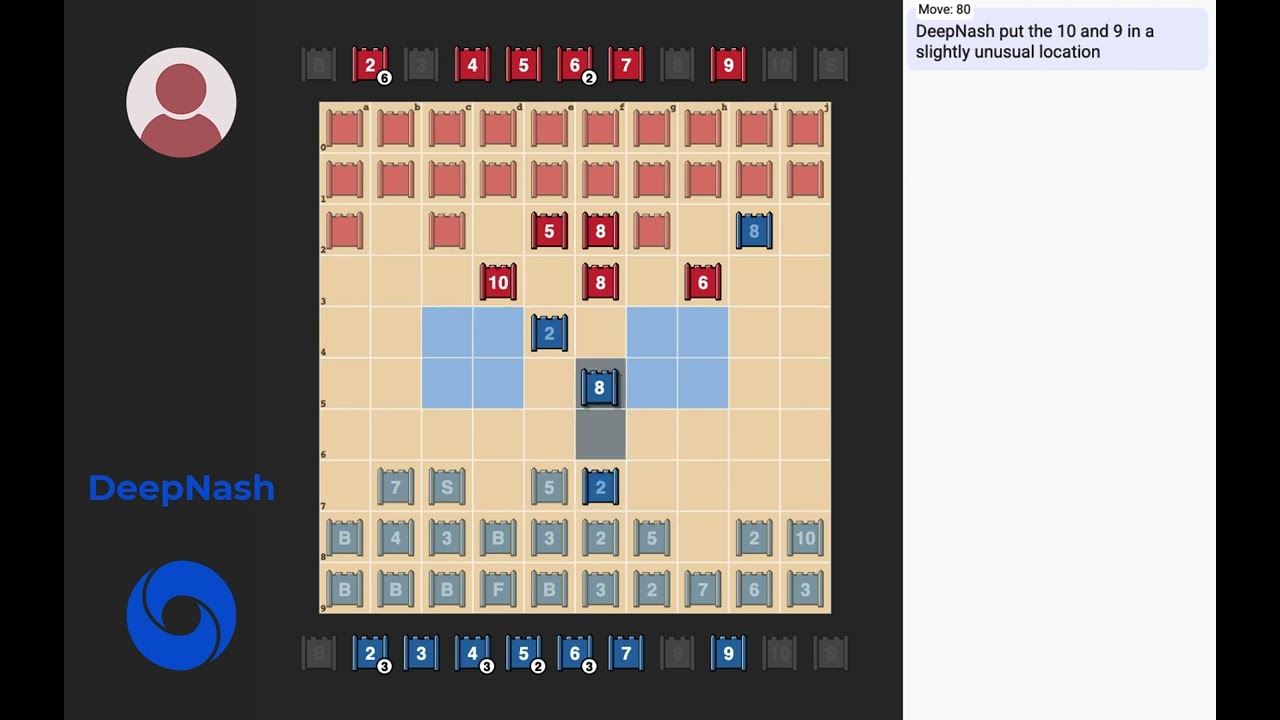
3戦目
DeepNash Stratego game 3 - YouTube

4戦目です。
DeepNash Stratego game 4 - YouTube

なお、ボード版「ストラテゴ」がAmazon.co.jpにて税込3954円で販売されています。
Amazon | Jumbo (ジャンボ) Stratego ストラテゴ オリジナル 戦略バトルボードゲーム 19816 正規品 | ボードゲーム | おもちゃ
・関連記事
最強の囲碁AI「KataGo」相手に99%勝つことができるAI学習手法が考案される、特殊すぎてAI相手にしか効果なし - GIGAZINE
最強将棋AIが新境地へ、DeepMindのAI「AlphaTensor」が50年以上停滞していた行列乗算アルゴリズムの改良に成功 - GIGAZINE
人間の動きを学習して3日でサッカーの動きを学習できるAI学習システムが開発される - GIGAZINE
DeepMindが人間レベルにかなり近づいたAI「Gato」を構築、ゲームプレイ・チャット・ロボットアーム操作などが可能 - GIGAZINE
DeepMindの研究者が「AIが人類を滅ぼす可能性は高い」との論文を発表 - GIGAZINE
・関連コンテンツ







in ソフトウェア, ゲーム, Posted by log1p_kr
You can read the machine translated English article DeepMind's AI ``DeepNash'' m….