




Googleによるウェブページ収集は1ページ当たり最大15MBまで、検索順位を下げないために必要な対策は?

Googleは検索結果に表示するウェブサイトの情報を収集するために、ネット上に公開されている無数のウェブページの情報を「Googlebot」と呼ばれるクローラで収集しています。このGooglebotに関する公式ドキュメント(英語版)には「15MB以上のファイルをクロールする際は、先頭15MBまでしかクロールしない」という記載が含まれているのですが、この15MB制限の詳細についての解説が新たに公開されました。
Googlebot and the 15 MB thing | Google Search Central Blog | Google Developers
https://developers.google.com/search/blog/2022/06/googlebot-15mb
GoogleはGooglebotを用いて日々増え続けるネット上の膨大な数のウェブページをクロールしています。Googleはウェブサイトの管理者向けにGooglebotの仕様をまとめたドキュメントを公開しているのですが、このドキュメントに加わった「Googlebotは1ファイルにつき最大15MBまでしかクロールしない」という記述に関して多くの問い合わせが寄せられたとのこと。そこで、GoogleはGooglebotの15MB制限の詳細についての解説を新たに公開しました。
◆「15MB」とはウェブページのどの部分のサイズを示しているのか
Googlebotはページ上に読み込まれる全コンテンツではなく、ページのソースのみをクロールしています。15MBという制限はHTMLファイルなどの「対象ページのURLにアクセスした際に最初に読み込まれるファイル」を対象としたもので、ページ上に表示される画像やムービーといったコンテンツの合計サイズが15MBを超えた場合でも、HTMLファイルなどのサイズが15MBを超えていなければ15MB制限の対象にはなりません。
◆15MB制限はウェブサイトの管理者にどんな影響をもたらすのか
Googleによると、インターネット上に存在するHTMLファイルのサイズの中央値は30KBとのこと。このため、ほとんどのウェブサイトの管理者は15MB制限を気にする必要はありません。GoogleはHTMLファイルが15MBを超えているウェブサイトの管理者に対して、スクリプトを外部ファイルに移動するように推奨しています。

◆15MBを超えるファイルはどう扱われるのか
Googlebotはファイルの先頭から15MBまでをクロールし、それ以降はクロールしません。
◆15MB制限はGooglebotが画像やムービーを収集しないことを意味するのか
上述の通り、Googlebotは画像やムービーの実ファイルを収集しておらず、「<img src="https://example.com/images/画像ファイル.jpg">」のようなHTML形式で収集しています。
◆データURLはファイルサイズに含まれるのか
データURLと呼ばれる仕組みを利用すると、画像ファイルなどを文字列に変換してHTMLファイルに含ませることが可能です。このデータURLはGooglebotのクロール対象となるため、15MB制限に含まれます。
◆ウェブページのサイズを調査する方法は?
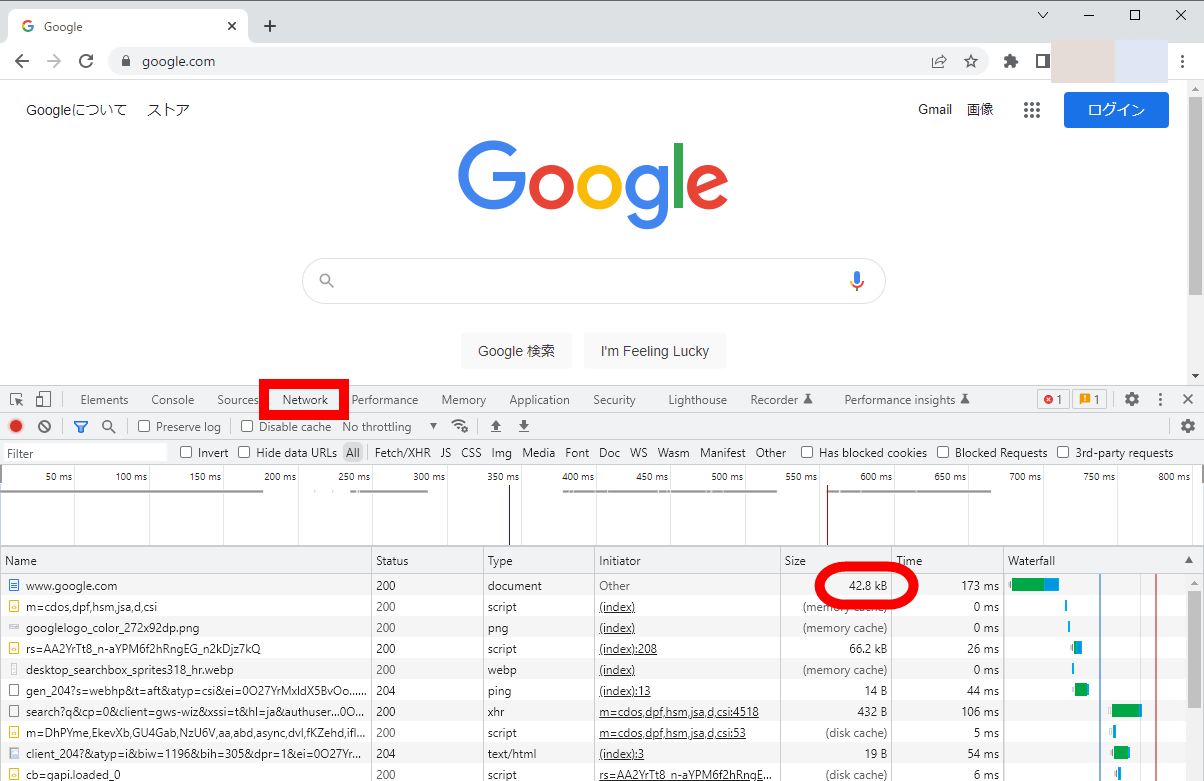
Googleは、ウェブページのサイズを調べる方法として、ウェブブラウザの開発者ツールを使う方法や、コマンドラインツール「cURL」を使う方法を紹介しています。例えば、Google Chromeでは「Ctrl+Shift+I」でデベロッパーツールを起動し、「Network」タブに切り替えた状態でウェブページを更新するとファイルサイズを調べられます。
・関連記事
Googlebotの各種統計情報「クロール統計レポート」が改善される、より詳細な情報が取得可能に - GIGAZINE
Googleの検索結果に表示される広告はどれくらいの効果があるのか? - GIGAZINE
Googleが6割以上のページのタイトルを勝手に書き換えて検索結果に表示、長すぎても短すぎてもダメ - GIGAZINE
知っていると便利なGoogle検索の隠れた27機能 - GIGAZINE
Google検索で「上手にググる」ための5つのポイントをソフトウェア工学の専門家が解説 - GIGAZINE
・関連コンテンツ




in ネットサービス, Posted by log1o_hf
You can read the machine translated English article Web page collection by Google is up to 1….