




AIのLLMアーキテクチャの新技法「KV共有」「mHC」「圧縮アテンション」とは何か?

オープンウェイトの大規模言語モデル(LLM)がプロンプト入力による質疑応答の枠を超え自律的かつ高精度な課題解決を行う方向に進化する上で、推論モデルやエージェントワークフローは欠かすことのできない手法となっていますが、より多くのトークンを長時間保持する必要があることからKey-Valueキャッシュ(KVキャッシュ)のサイズ・メモリ帯域幅・アテンションコストといったリソースが実行上の主要な制約となります。LLM開発者はリソースのコストを削減する目的でLLMアーキテクチャに様々な工夫を取り入れてきましたが、2026年4月から5月にかけてリリースされたLLMについて注目すると長文コンテキストの効率化に非常に重点を置いている傾向にある、とLLMリサーチエンジニアの Sebastian Raschka氏は指摘しています。
Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed Attention
https://magazine.sebastianraschka.com/p/recent-developments-in-llm-architectures
◆新技法の実例
Raschka氏は特に注目しているアーキテクチャの新技法の実例として以下の4つのLLMを挙げています。
・Gemma 4:KV共有・レイヤーごとの埋め込み(PLE)
・Laguna XS.2:レイヤーごとのアテンションバジェット
・ZAYA1-8B:圧縮畳み込みアテンション(CCA)
・DeepSeek V4:CSA/HCA・mHC・圧縮アテンションキャッシュ
上記のLLMに見られる変更点の多くはRaschka氏が示した図中では些細な調整のようにも見えますが、中には詳しく検討すべきかなり複雑な設計変更も含まれているとのことです。
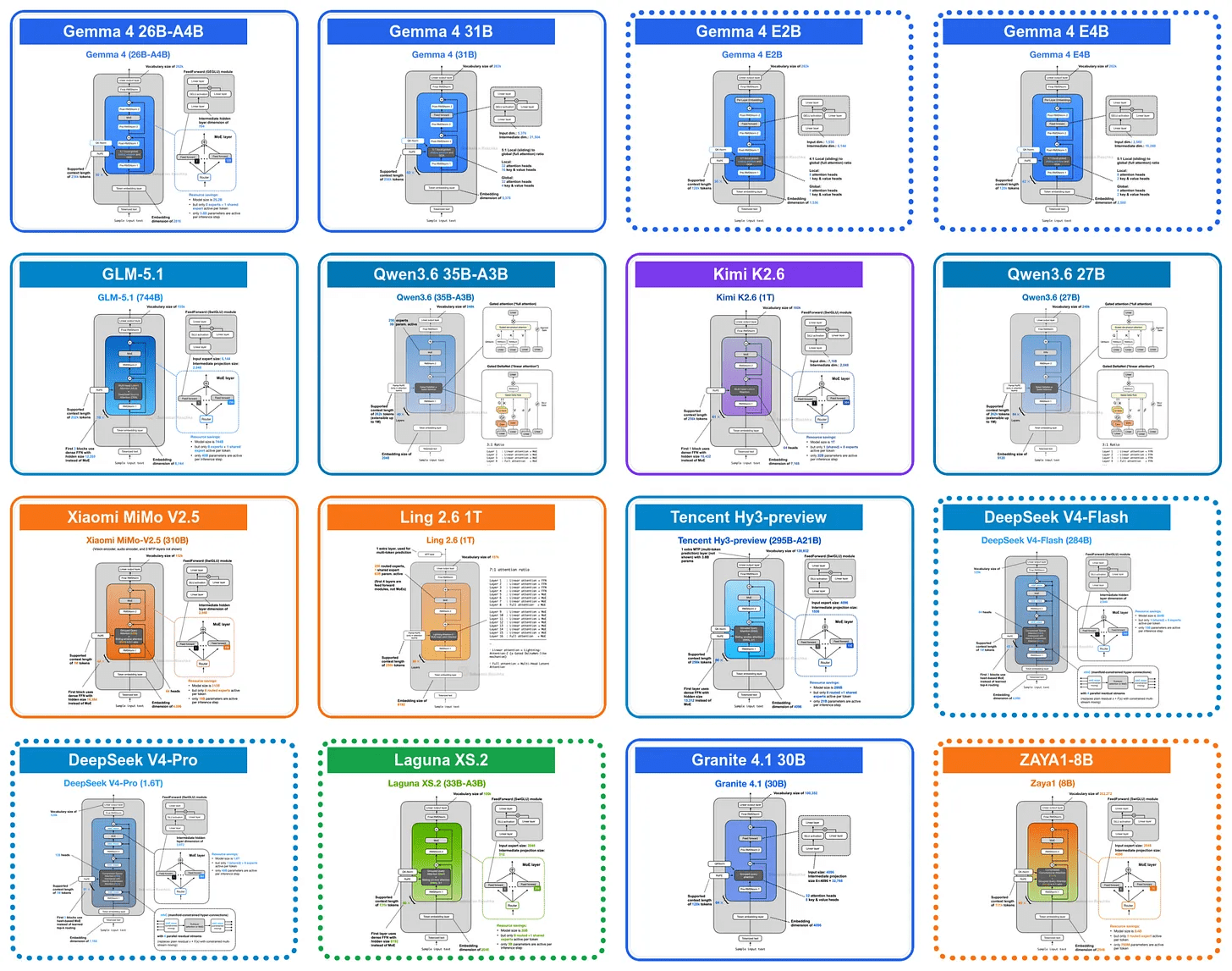
◆Gemma 4
Gemma 4のE2BおよびE4Bバリアントにおけるアーキテクチャの変更点の一つ「KV共有」とは、後続レイヤーが先行レイヤーの使用したキー・バリュー(KV)状態を再利用しKVキャッシュサイズを削減することによりロングコンテキストメモリと計算量を削減する手法です。Gemma 4では以前からGrouped Query Attention(GQA)と呼ばれる手法により異なるクエリヘッド間でKVヘッドを共有しKVキャッシュのサイズを削減してきました。
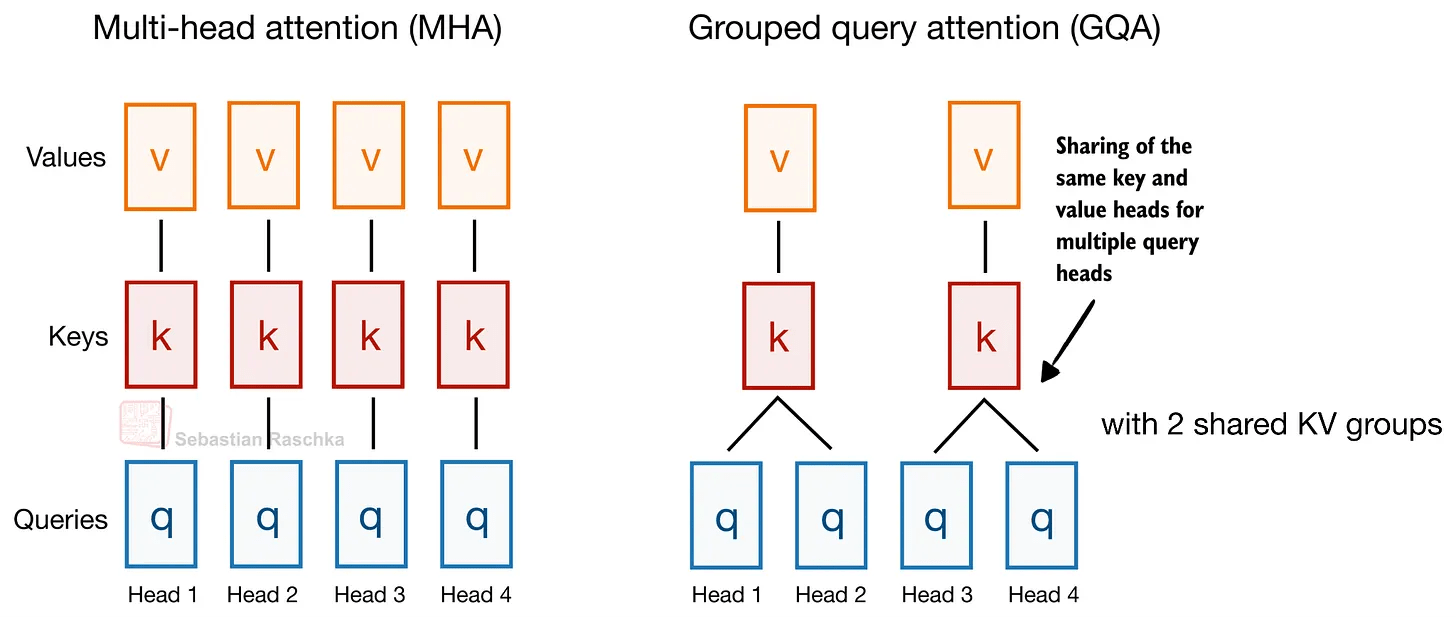
Gemma 4はGQAによりクエリ間でKVを共有することに加え、異なるレイヤー間でKVプロジェクションを共有します。このKV共有方式はクロスレイヤーアテンションとも呼ばれています(下図右)。
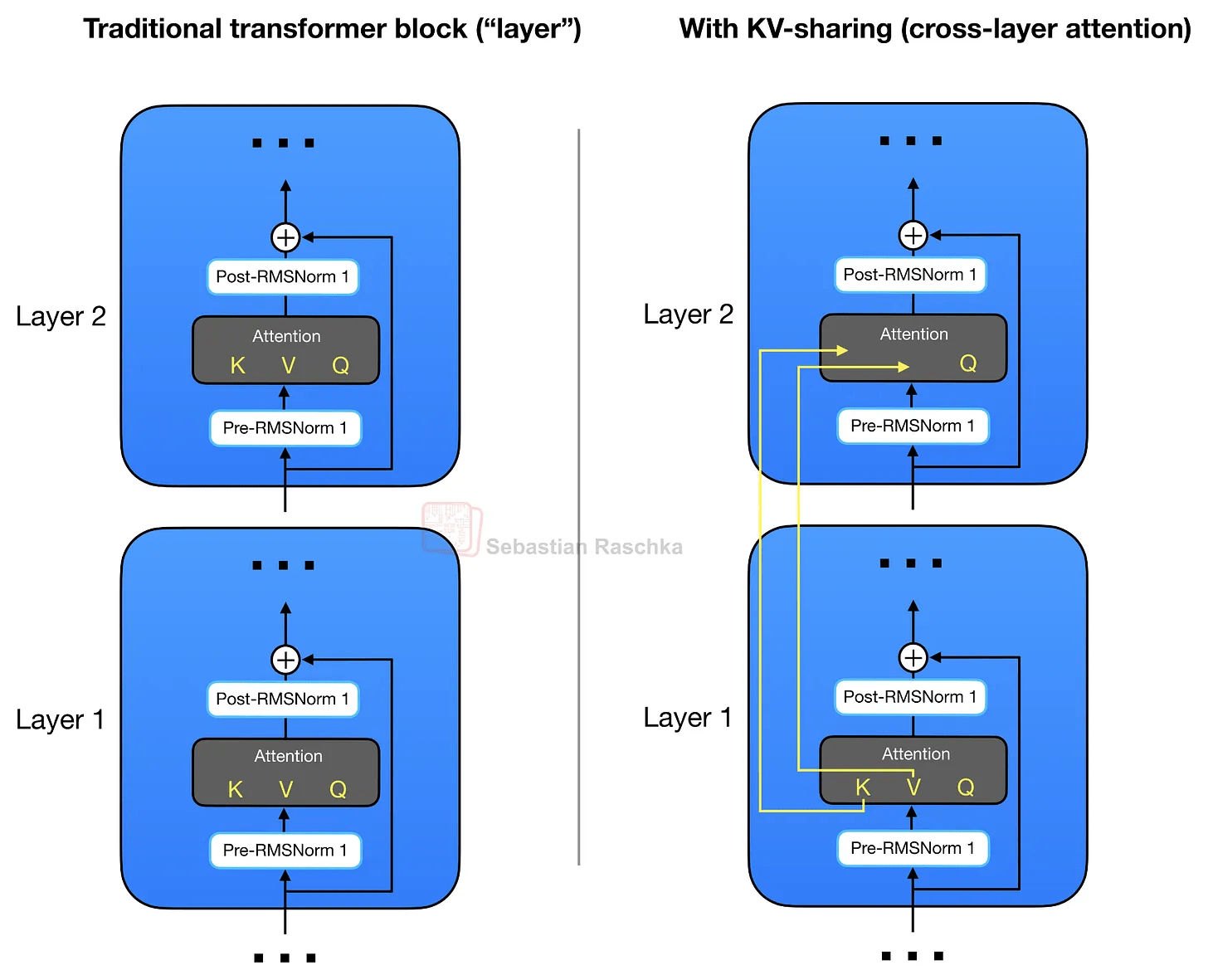
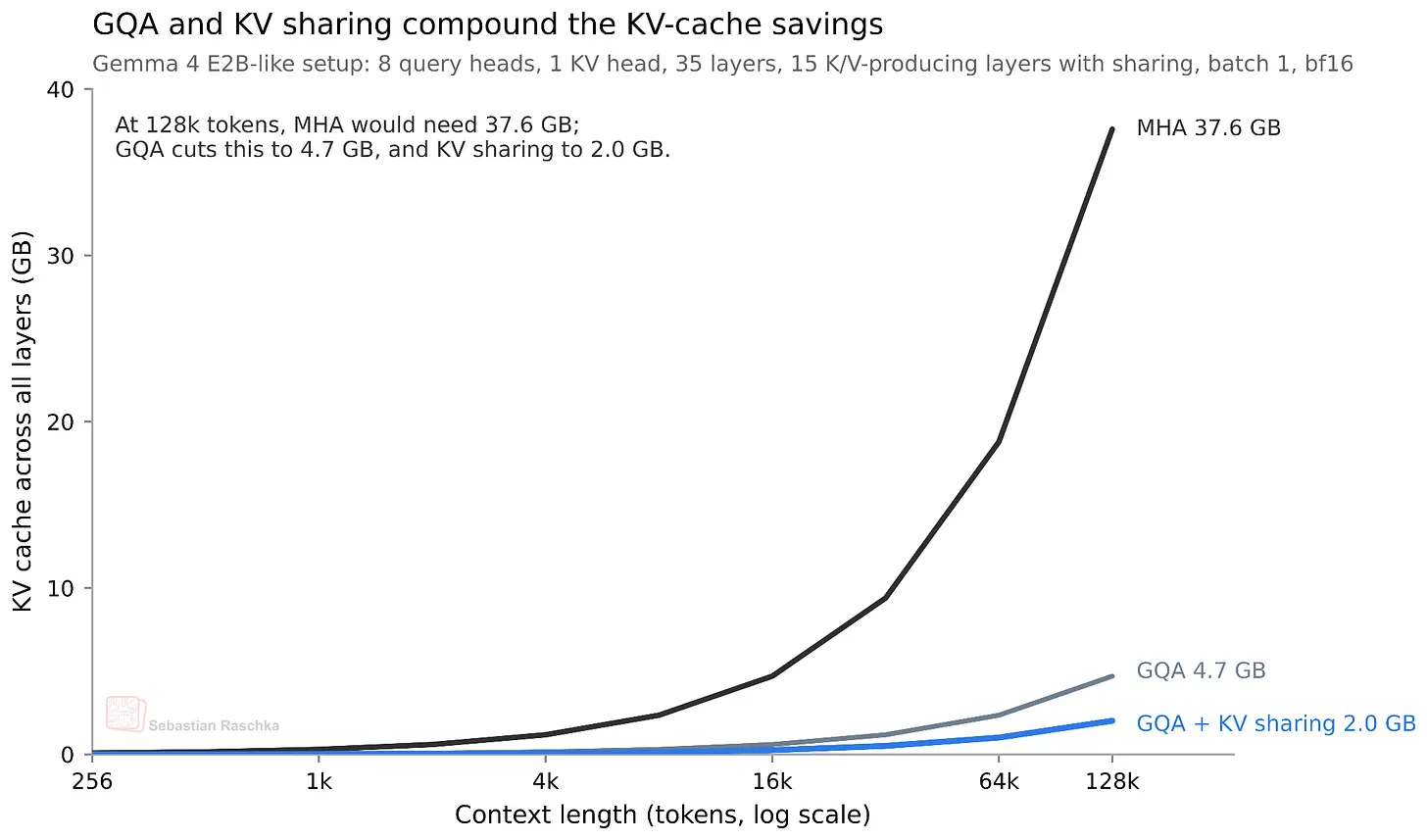
レイヤー間でKVの約半分を共有することになりKVキャッシュサイズも約半分に削減できるため、128Kの長文コンテキストにおいてE2Bモデルで約2.7GB、E4Bモデルで約6GBのKVキャッシュサイズ削減を実現しています。
Gemma 4のE2BおよびE4BバリアントはKV共有以外にも効率性を重視した設計オプションとして「レイヤーごとの埋め込み(PLE)」という手法を使っています。PLEはパラメータ効率を重視した設計となっており、同じ総パラメータ数を持つ高密度モデルほどメインのトランスフォーマースタックのコストをかけず、小規模なGemma 4モデルがより多くのトークン固有の情報を利用できるようにしています。
概念的には、PLEパスはアテンションとフィードフォワードの残差更新を計算した後に層固有のPLEベクトルをゲートし、ゲートされたPLEベクトルはモデルの隠れサイズに投影され正規化されて追加の残差更新として加算されます。PLE構築には「トークンIDのレイヤーごとの埋め込みルックアップ」と「通常のトークン埋め込みのパックされたPLE空間への線形射影」という2つの入力があり、両者は加算・スケーリング・形状変更されて各ブロックが独自のスライスを受け取るレイヤーごとに1つのスライスを持つテンソルになります。
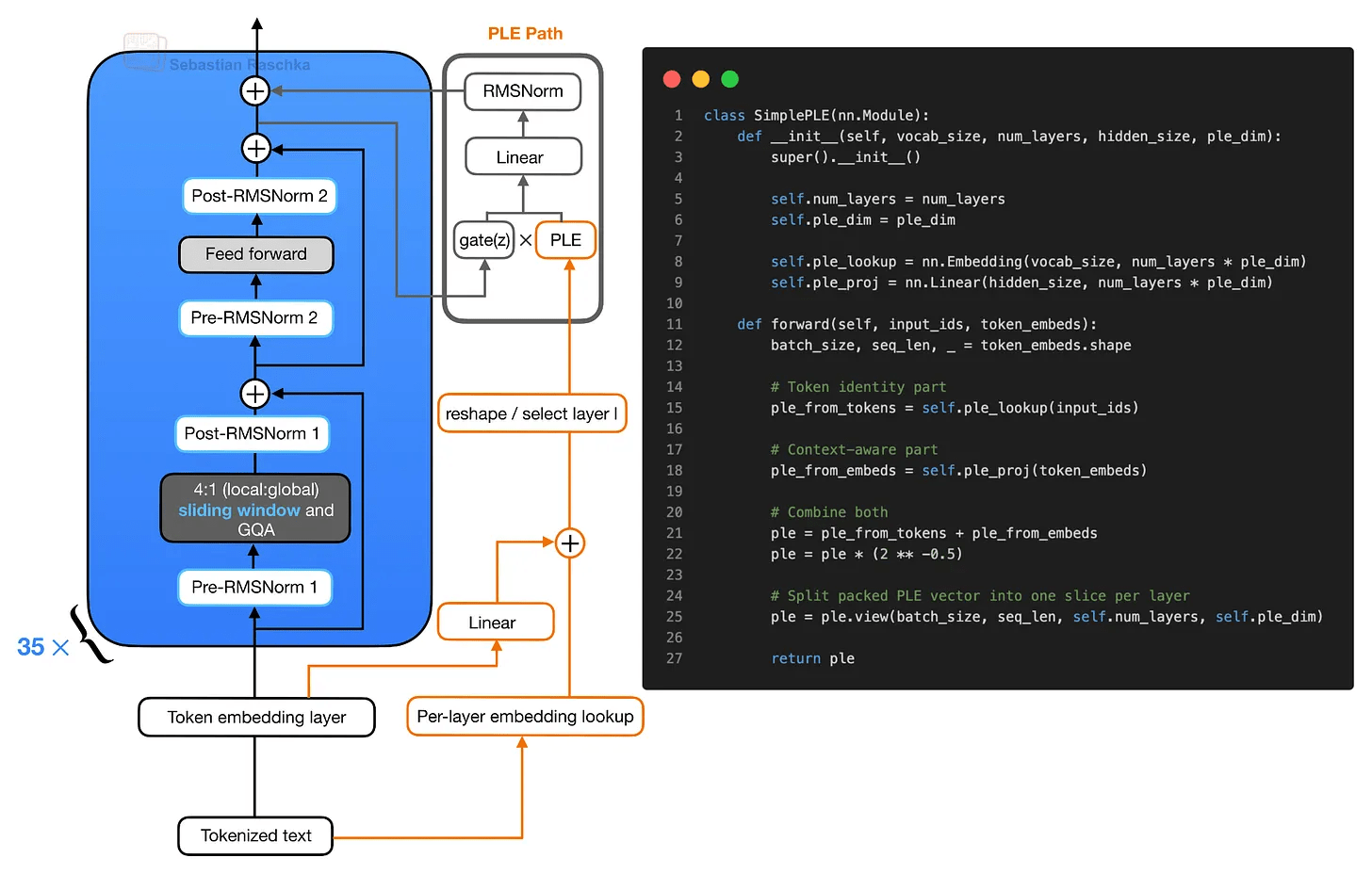
PLEは各トランスフォーマーブロックに通常のトークン埋め込みレイヤーの完全な独立したコピーを与えるのではなく、レイヤーごとの埋め込みルックアップを一度だけ計算し各レイヤーにトークン固有の小さな埋め込みスライスを提供します。PLEは計算オーバーヘッドの増加を抑えつつパラメータと小さな射影を埋め込むことでモデルの表現能力を高めています。
◆Laguna XS.2
Laguna XS.2のアーキテクチャは一見すると非常に標準的なものに見えますが、「レイヤーごとのアテンションバジェット(注意予算)」という概念があります。
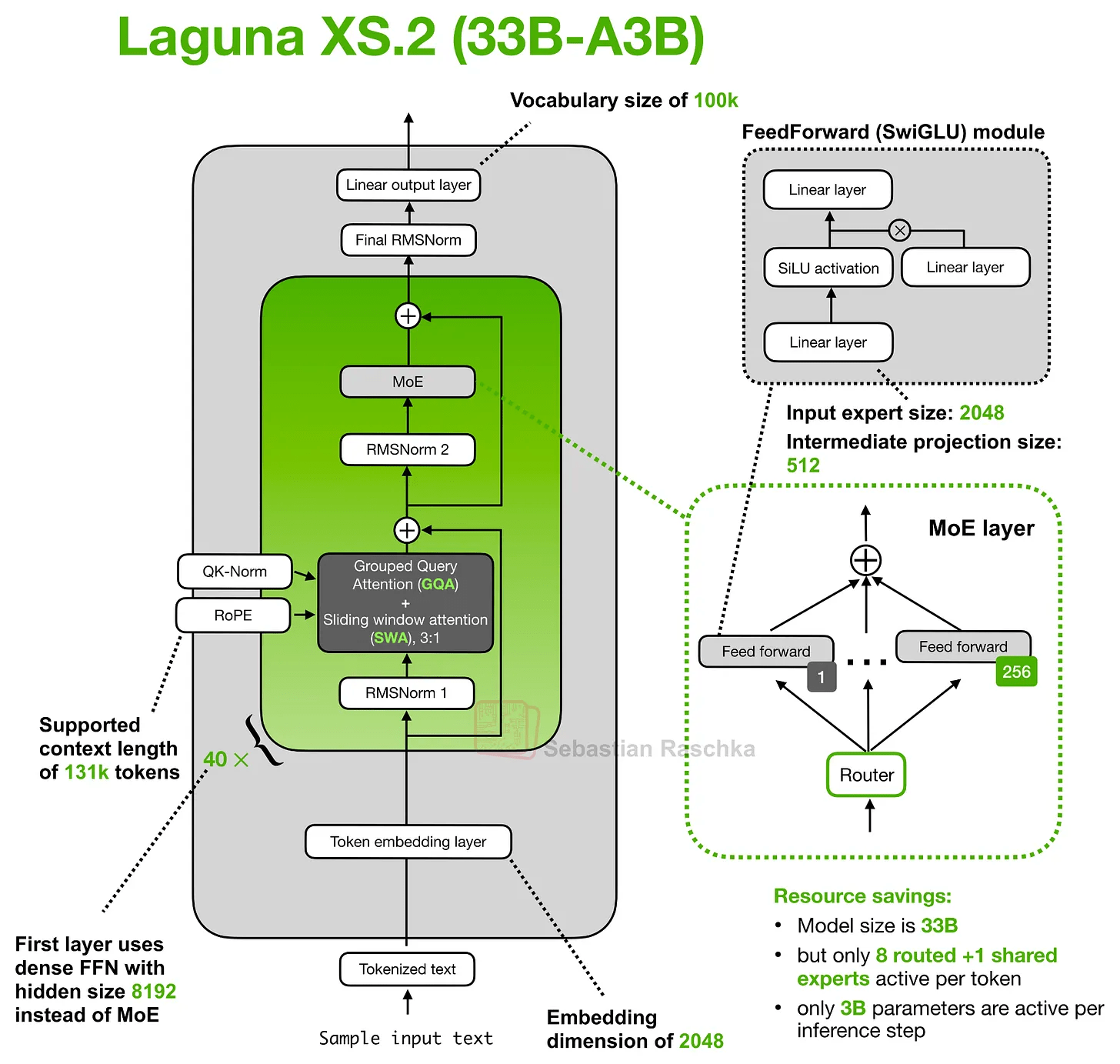
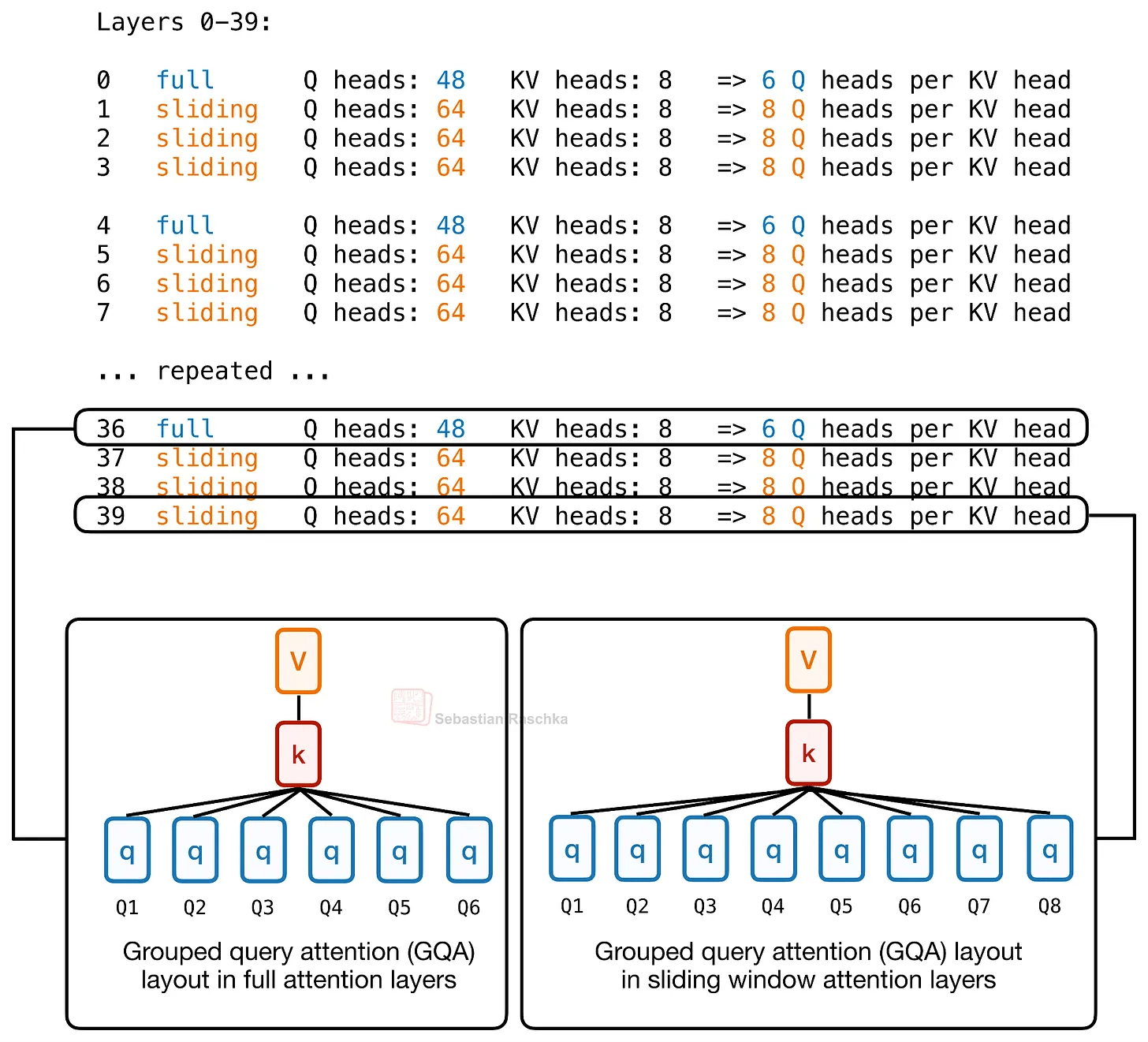
「レイヤーごと」とは、全レイヤーに同じアテンションバジェットを割り当てるのではなくレイヤーごとにアテンションコストを変動させることを意味します。具体的には、Laguna XS.2は30のSliding Windowアテンションレイヤーと10のGlobal/Fullアテンションレイヤーを持っていますが、Sliding Windowレイヤーはローカルウィンドウのみにアテンションをかけるため、KVキャッシュとアテンション計算のコストを抑えることができます。対して、Globalレイヤーはコストは高くなるもののコンテキストウィンドウ内のすべての情報にアクセスできる機能を維持します。
一方、レイヤーごとのクエリヘッド数に注目するとLaguna XS.2 では、スライディングウィンドウ層に多くのクエリヘッドを割り当て、コンテキスト全体を走査するためコストが高いグローバル層にはより少ないクエリヘッドを割り当てます。つまり、レイヤーごとのクエリヘッド数を調整することでアテンション能力を最も有用な箇所に集中させているのです。
◆ZAYA1-8B
ZAYA1-8Bのアーキテクチャ上の特徴はグループ化クエリアテンション(GQA)と組み合わせて使用される「圧縮畳み込みアテンション(CCA)」です。
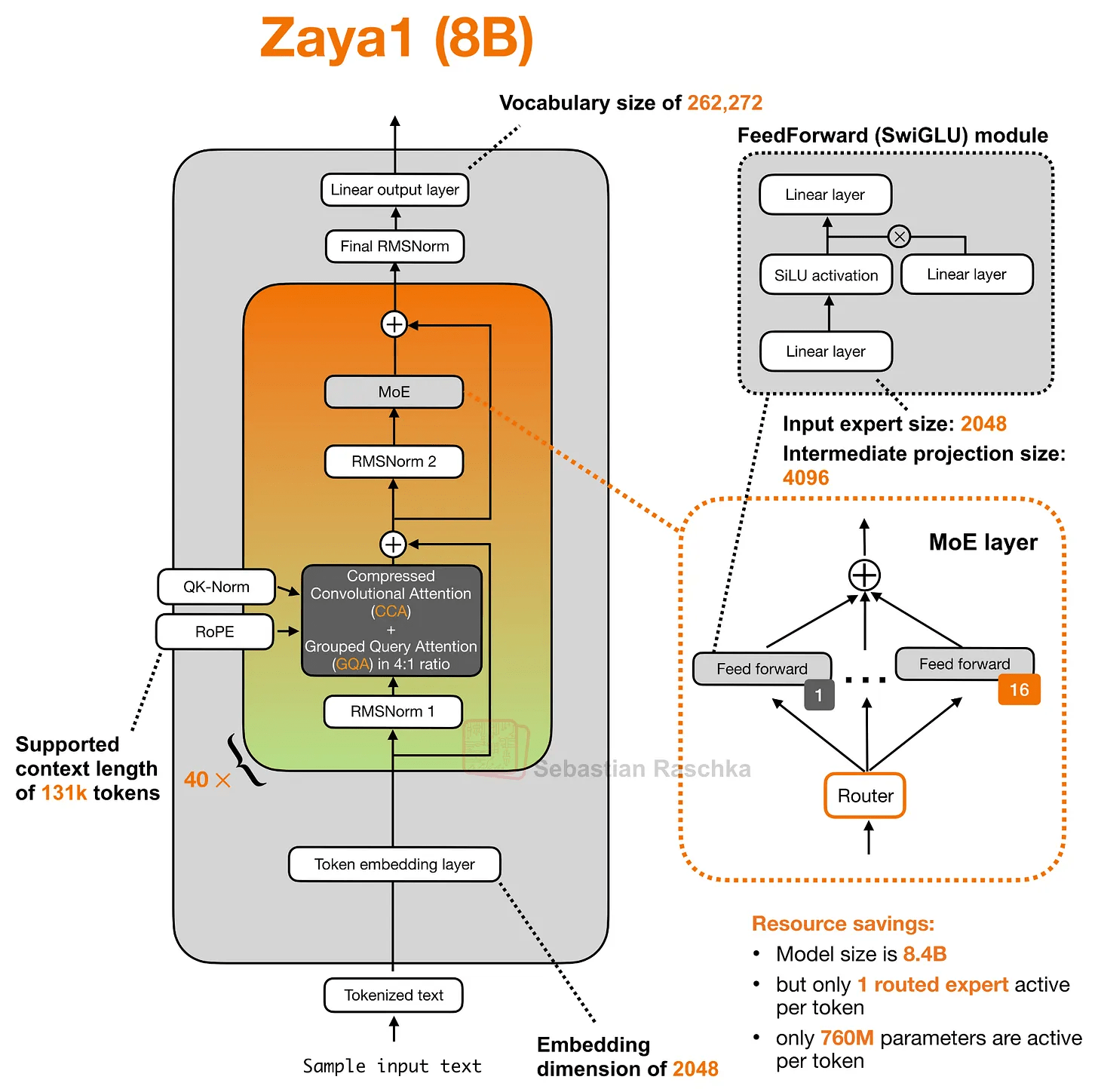
CCAは圧縮された潜在表現をアテンションブロックに導入する点ではマルチヘッド潜在アテンション(MLA)に似ていますが、MLAの主眼が マルチヘッドアテンションの課題であったKVキャッシュサイズ増大の解消にあるのに対して、CCAは圧縮された潜在空間内で直接アテンション演算を実行するためKVキャッシュサイズだけでなくアテンションFLOPsも削減します。
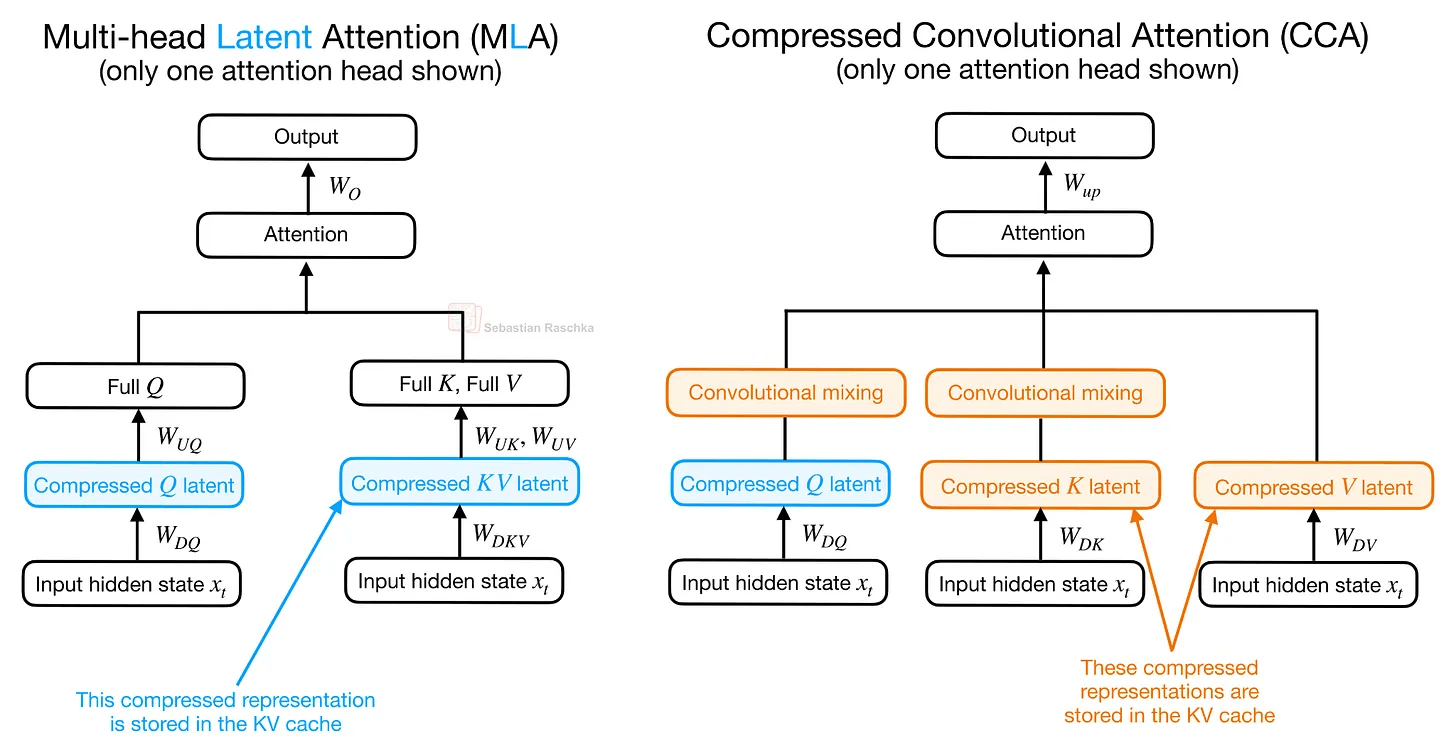
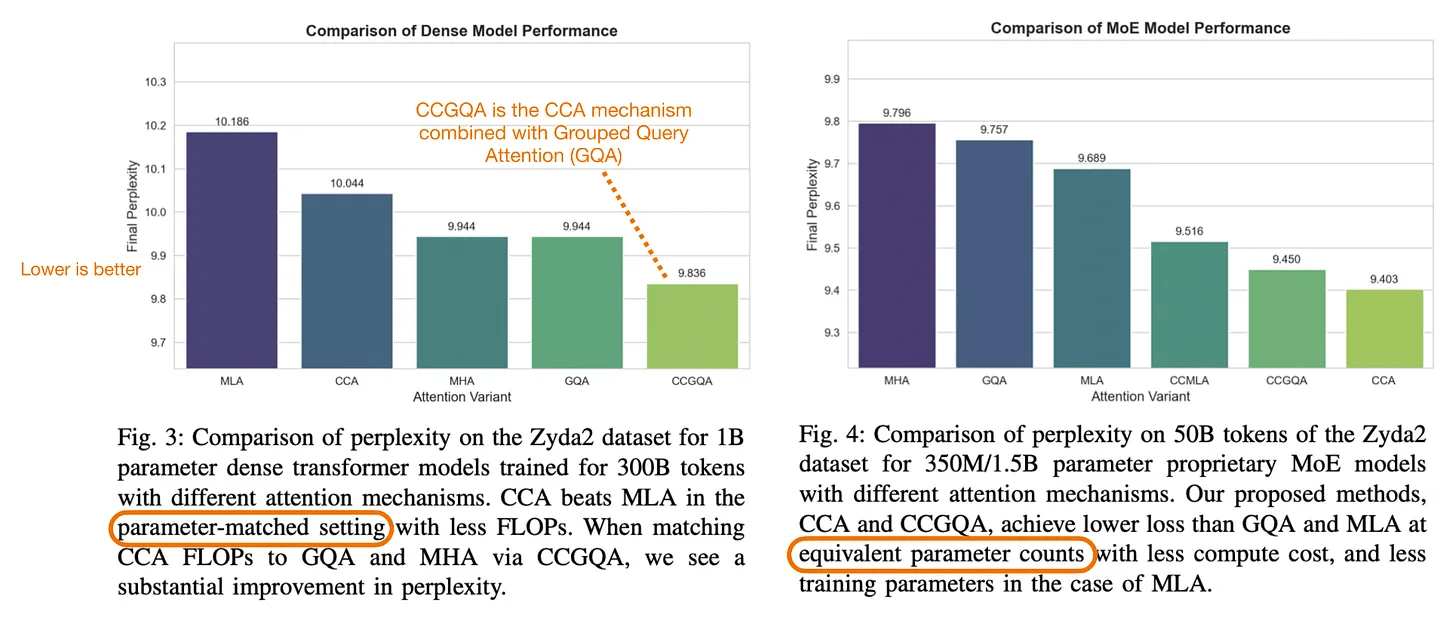
CCAに関する論文において、同等の圧縮設定においてCCAはMLAを上回る性能を発揮すると報告されていますが、CCAが圧縮された潜在空間でアテンション操作を直接実行することで圧縮されたアテンションの制約を軽減している点が実に興味深いといえます。つまりZAYA1-8Bは、フィードフォワード層だけでなくアテンションメカニズム自体においても計算コストを削減しようとしているのです。
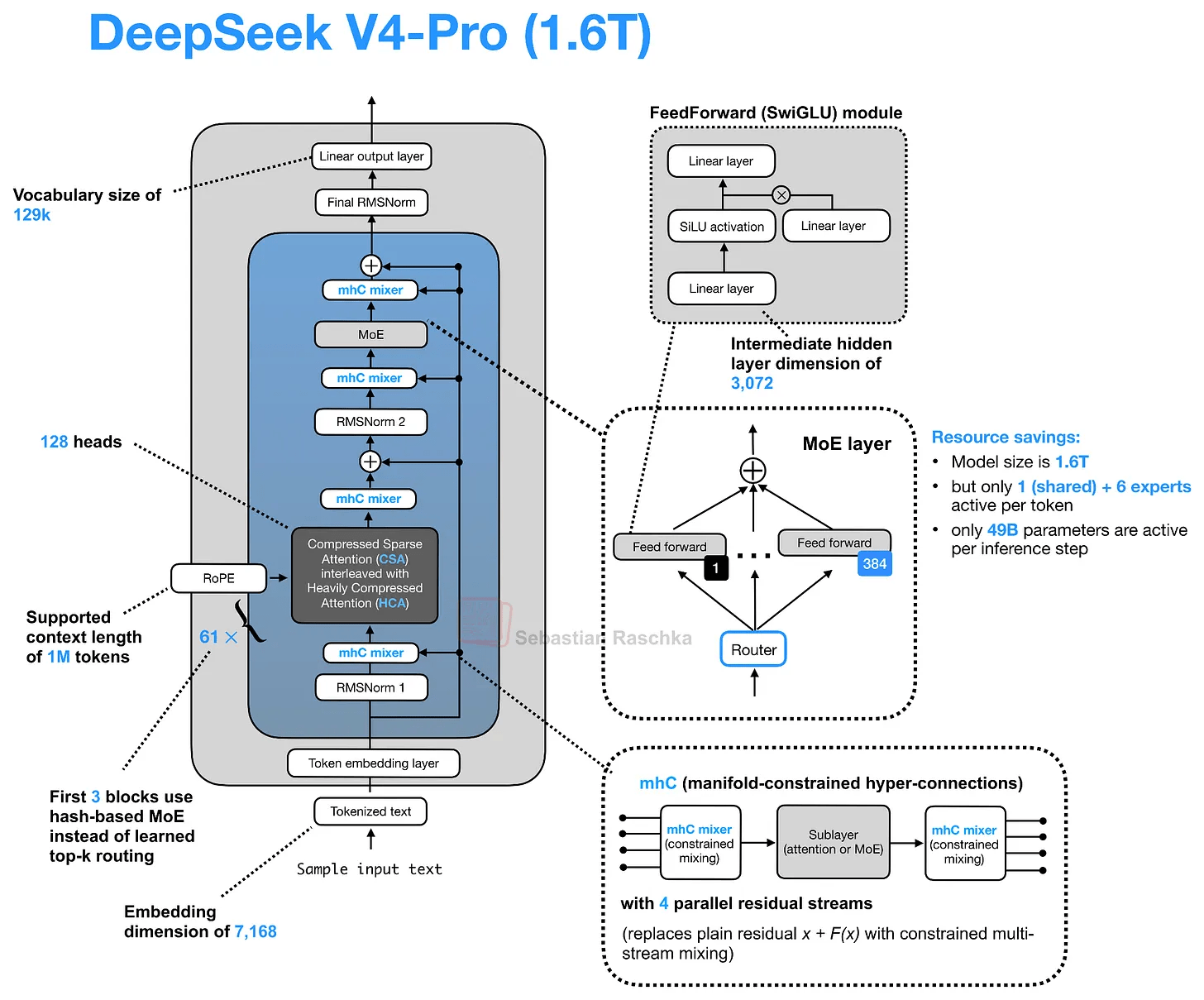
◆DeepSeek V4
DeepSeek V4のアーキテクチャを図示すると多くの要素が複雑に絡み合って見えますが、残差パスの変化(mHC)・アテンションパスの変化(CSA/HCA)・圧縮アテンションキャッシュを区切って捉えると理解しやすくなります。
「多様体制約付きハイパーコネクション(mHC)」の主な目的はトランスフォーマーブロック内の残差接続を近代化することにあり、名前が示す通りハイパーコネクションの研究に基づいています。ハイパーコネクションの基本的な考え方は残差ストリームを拡張することであり、トランスフォーマーブロック内の単一の残差ストリームを複数の並列残差ストリームとその間の学習済みマッピングに置き換えまるというものです。アテンション層やMoE層自体は通常の隠れ層サイズで動作しますが、ハイパーコネクションでは並列残差ストリームをレイヤーの通常の隠れベクトルに結合するためのプリマッピングとレイヤーの出力を並列残差ストリームに分配するためのポストマッピングが追加されます。
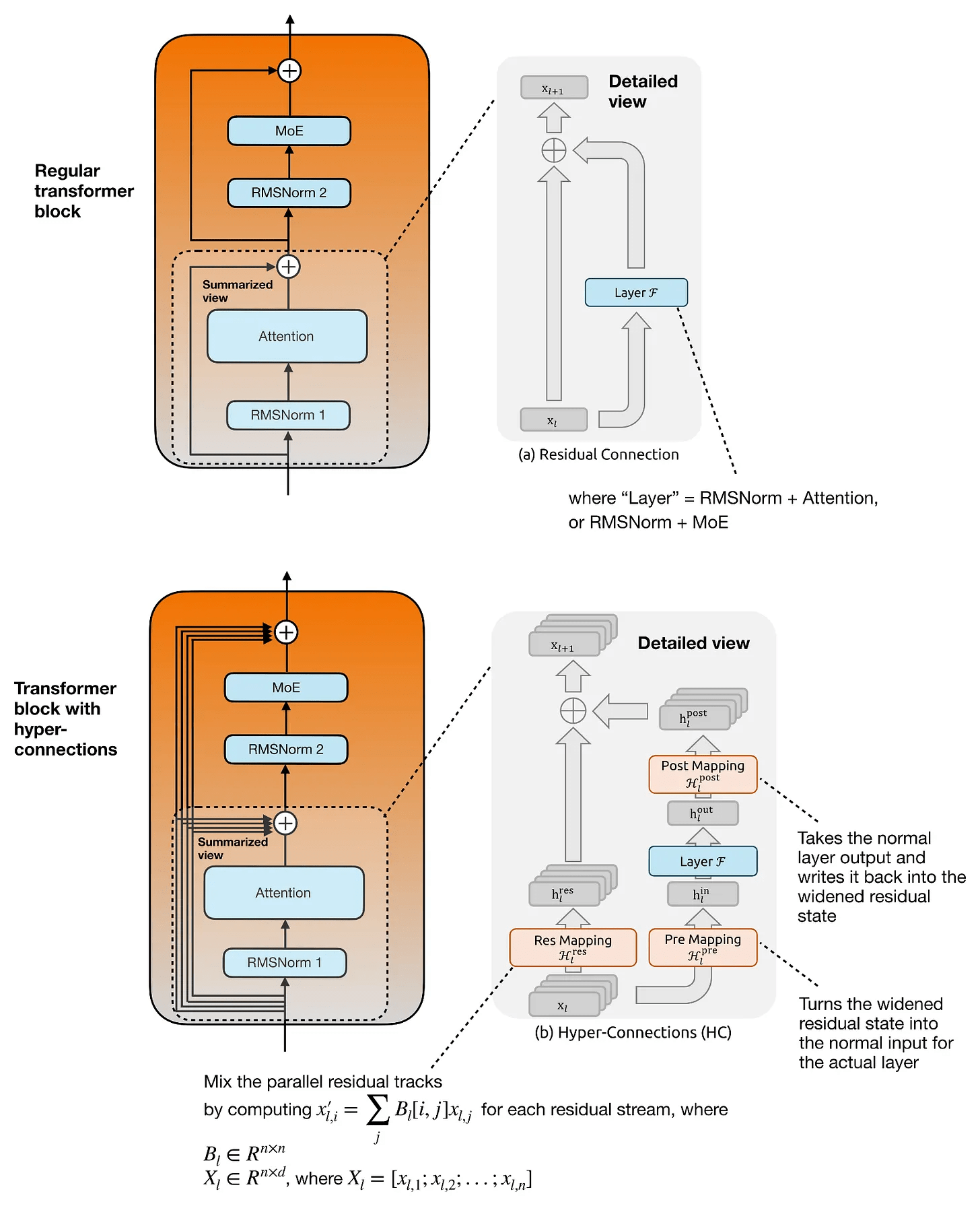
通常のハイパーコネクションとmHCの最も重要な違いは「マッピングが制約なしではなくなる」ことにあります。通常のハイパーコネクションで行われる学習済み行列による残差マッピングとは異なり、mHCでは残差マッピングが二重確率行列の多様体に投影されます。よって「すべてのエントリが非負」かつ「各行と各列の合計が1になる」という制約が課されることになります。制約があることによって残差混合はストリーム全体にわたる情報の安定した再分配のといった振る舞いを見せるようになります。さらに、プリマッピングとポストマッピングも非負かつ有界であるように制約されているため、拡張された残差状態からの読み取り・書き込み時に相殺が発生するのを防ぎます。つまり大規模なモデルにとって重要なポイントは、mHCがハイパーコネクションの豊富な残差混合を維持しつつより安全にスケーリングできるように制約を追加したことにあります。
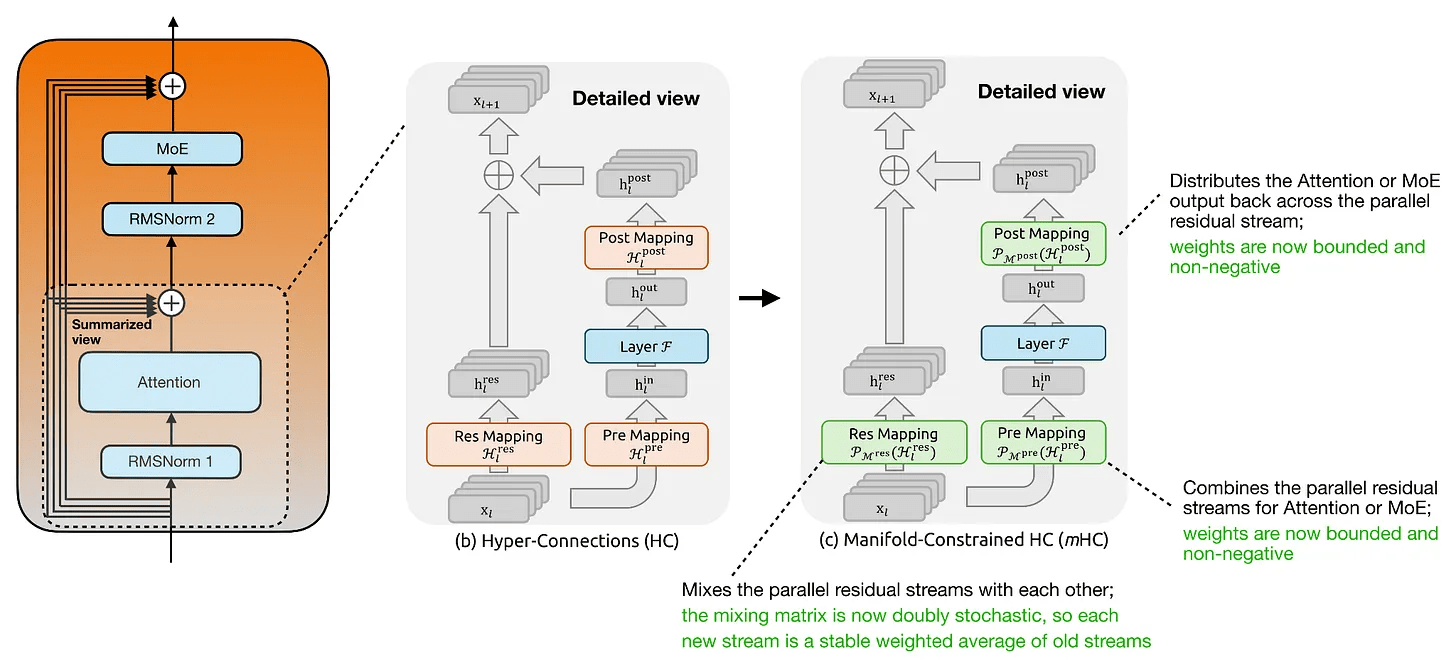
要約すると、mHCは計算オーバーヘッドを最小限に抑えながらレイヤー間での情報伝達方法を変更し安定性制約を適用しているということになります。さらに付け加えるとmHCはDeepSeek V4のアーキテクチャにおけるもう一つの大きな変更点である「CSA/HCA」のアテンション変更と相性がよいとのことです。
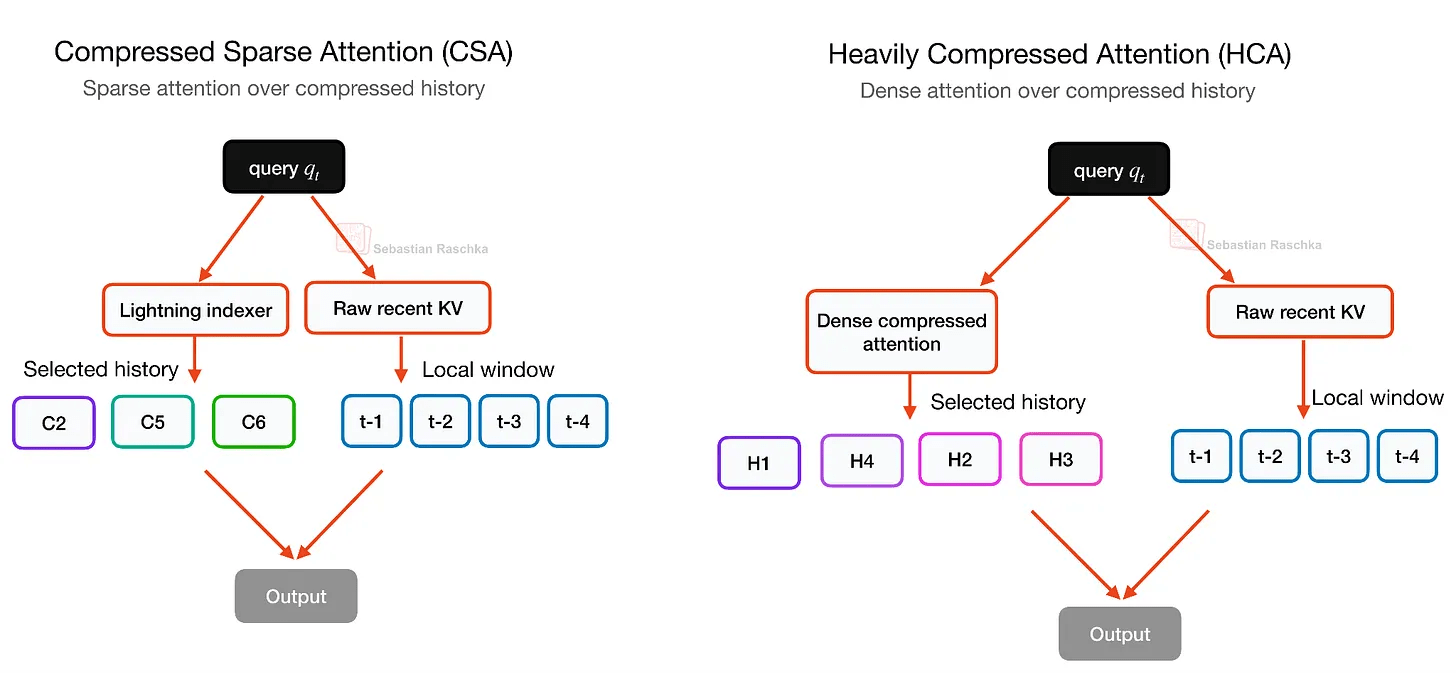
CSA/HCAはロングコンテキスト推論のコストを削減するための2つの圧縮アテンション機構「圧縮スパースアテンション(CSA)」と「高圧縮アテンション(HCA)」のハイブリッドです。DeepSeek V2/V3で使用されていた圧縮アテンション機構であるMLAは前述の通りトークンごとのKV表現を圧縮するもののトークンごとに1つの潜在エントリを保持しますが、CSAやHCAはシーケンス次元に沿って圧縮するためKVキャッシュサイズをより大幅に削減できます。
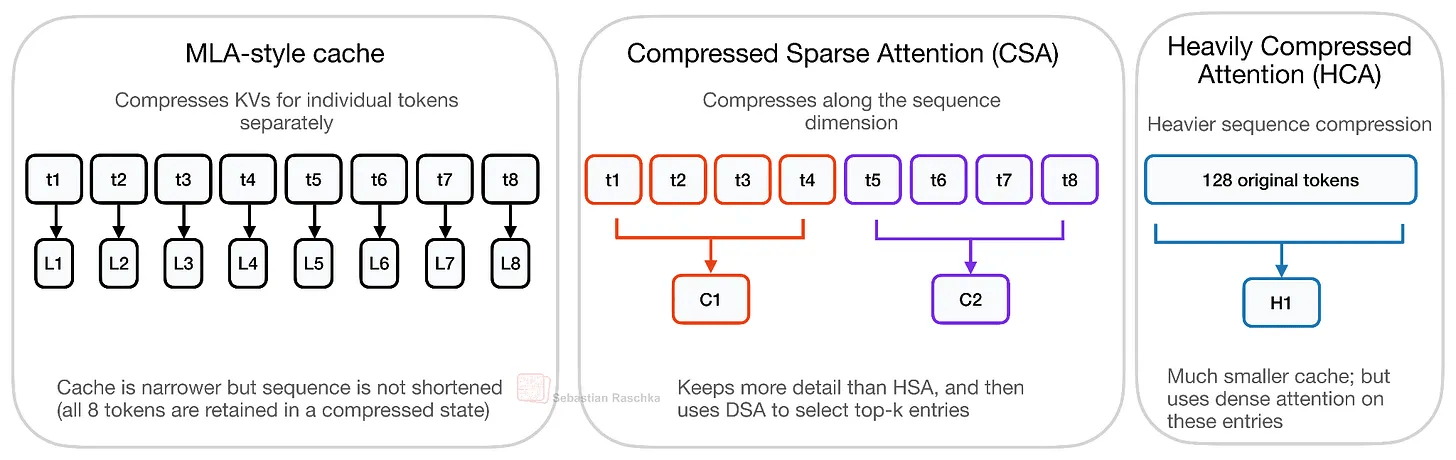
CSAは比較的緩やかな圧縮率を持つのに対してHCAはより強力な圧縮率を持ちます。圧縮が強すぎるとモデリングの品質を損なう可能性があることから、DeepSeek V4はCSAとHCAを交互に使用するハイブリッド方式を採用しモデリングの品質を維持しつつ効率性を高めています。
◆まとめ
近年のオープンウェイトLLMアーキテクチャの改良は、パラメータ数を単純に削減するのではなく長文コンテキストの推論コスト削減に焦点が当てられています。Gemma 4はKVキャッシュメモリを削減し、Laguna XS.2はアテンション能力配分を調整し、ZAYA1-8Bはアテンションを圧縮潜在空間に移動させ、DeepSeek V4は制約付き残差ストリーム混合と圧縮長文コンテキストアテンションを採用しています。LLMアーキテクチャはますます複雑さを増してはいるものの、目指す進化の方向性については明確であるといえます。
・関連記事
「AIが私のソフトウェアエンジニアとしてのキャリアを侵食しておりどうすればいいか分からない」という投稿が大きな反響を呼ぶ - GIGAZINE
長大コンテキストの処理でClaude Opusを超える性能を示す効率設計AIモデル「SubQ」が登場、1200万トークンの入力が可能でTransformerの限界を打ち破る - GIGAZINE
GPT・Llama・Grokなどさまざまな大規模言語モデルのアーキテクチャを図示した「LLM Architecture Gallery」 - GIGAZINE
軽量で高性能なコーディングエージェント「Qwen3-Coder-Next」が登場 - GIGAZINE
スイス独自の完全オープンソースLLM「Apertus」がリリースされる、1000言語以上にわたる15兆トークンで学習&透明性とデジタル主権を重視 - GIGAZINE
OpenAIがオープンウェイトのAI推論モデル「gpt-oss」を発表、軽量版はノートPCやスマートフォンでも動作可能 - GIGAZINE
世界最長のコンテキストウィンドウ100万トークン入力・8万トークン出力対応にもかかわらずたった7800万円でトレーニングされたAIモデル「MiniMax-M1」がオープンソースで公開され誰でもダウンロード可能に - GIGAZINE
MozillaがAIエージェントの比較やテストを容易にするライブラリ「Any-Agent」をリリース、MCPにも対応 - GIGAZINE
・関連コンテンツ








in AI, Posted by log1c_sh
You can read the machine translated English article What are the new AI LLM architecture tec….