




PostgreSQLには「中途半端なサイズ」のデータを格納しないほうがいい

ウェブサイトやアプリケーションには、ユーザー名やメールアドレスといった小さなサイズのものからブログ本文といった大きなサイズのものまで多種多様なサイズのテキストが使われています。一般的にはテキストサイズによってデータベースを使い分けることはありませんが、データベースのPostgreSQLでは「中途半端なサイズ」のテキストデータを格納するとパフォーマンスの低下につながるという調査結果とその仕組みを、ソフトウェアエンジニアのHaki Benita氏が説明しています。
The Surprising Impact of Medium-Size Texts on PostgreSQL Performance | Haki Benita
https://hakibenita.com/sql-medium-text-performance
PostgreSQLの場合、データベースのインデックスとテーブルは「ページ」単位にまとめられています。ページのサイズは一律であり、複数のページにまたがってデータを記録することはできません。サイズの小さい値をテーブルに挿入する場合は、そのまま値がテーブルに収まるので問題ありませんが、サイズの大きい値を格納する場合には工夫が必要になります。
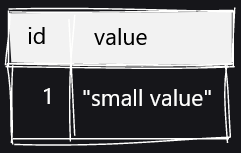
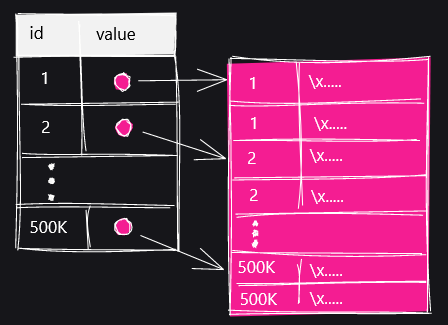
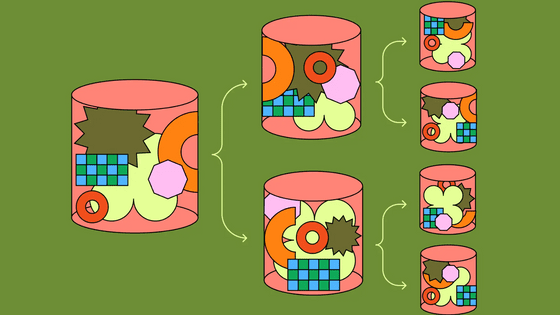
その工夫が「TOAST」と呼ばれるデータ分割の仕組みです。TOASTに対応した列にサイズの大きい値を格納する場合、ピンク色で描かれているTOASTテーブルを新たに作成し、データを複数行に分割して格納していくとのこと。
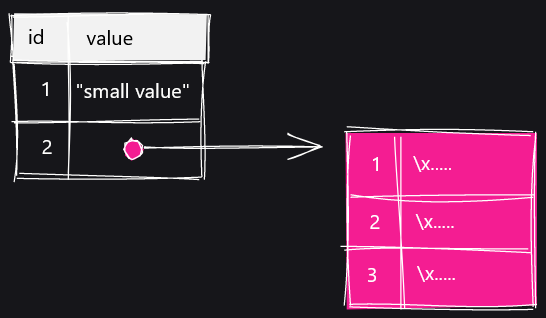
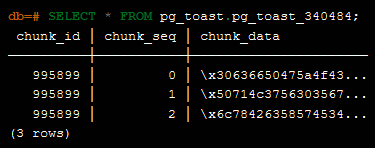
SELECT文でTOASTテーブルを表示するとこんな感じ。「chunk_id」「chund_seq」「chunk_data」という3つの列が存在します。
Benita氏は以下の3種類のテーブルを用意し、それぞれのテーブルから特定のレコードを読み出す速度を測定しました。
・toast_test_small:そのままテーブルに格納できるサイズのテキストを50万行格納したテーブル
・toast_test_medium:そのままテーブルに格納できる「限界」サイズのテキストを50万行格納したテーブル
・toast_test_large:TOAST処理が行われるサイズのテキストを50万行格納したテーブル
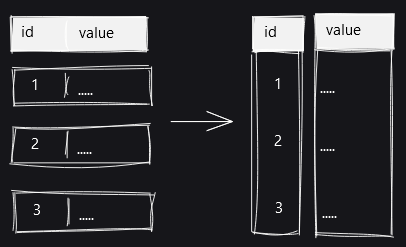
それぞれのテーブルを図で可視化するとこんな感じ。toast_test_smallテーブルは、値がそのままテーブルに収まっています。
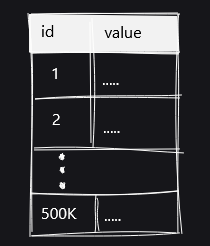
toast_test_mediumテーブルは、サイズの大きいテキストがTOAST処理されずギリギリもとのテーブルに格納されている状態。

テキストのサイズが大きく、TOAST処理が行われているのがtoast_test_largeテーブルとなります。
これらの3つのテーブルについて、特定のIDを持つレコードの読み出しを行う以下のSQL文の実行速度を測定。感覚的には、全体のデータサイズが最も大きいtoast_test_largeテーブルの読み出し速度が最も遅いと思えますが……
SELECT * FROM toast_test_medium WHERE id = 6000;
測定の結果、最も読み出しに時間がかかったのはなんとtoast_test_mediumテーブルだったとのこと。

それぞれのテーブルサイズとTOASTテーブルサイズなどをまとめた表が以下。PostgreSQLでは特定のレコードをテーブルから取得する際、テーブル全体のスキャンが行われます。toast_test_smallテーブルとtoast_test_largeテーブルはもとのテーブルのサイズが小さいため短時間でスキャンが可能ですが、toast_test_mediumテーブルはもとのテーブルのサイズが大きくなってしまっているため、レコードの読み出しに時間がかかってしまうとBenita氏は説明しています。

先ほどのSQL文はもとのテーブルに存在するIDを検索していましたが、TOASTテーブルに存在する値をひとつづつ検証する必要がある以下のようなSQL文を実行した場合は……
SELECT * FROM toast_test_large WHERE value LIKE 'foo%';
テキストのサイズ順に読み出し速度が並びます。

インデックスを作成した場合は特定のレコード読み出しにおけるパフォーマンスはほぼ変わりませんでしたが、「WHERE id BETWEEN 0 AND 250000」と指定して大量のレコードを取得した場合は、以下のようにtoast_test_mediumテーブルのパフォーマンスが最も悪い結果に。インデックスはテータベースがアクセスしなければならないページ数を減らすのには役立ちますが、SQL文そのものがテーブルの大部分に対する読み書き要求する場合は効果が低くなるとのこと。

toast_test_mediumテーブルのように「中途半端」なサイズのテキストを格納することが多い場合は、「toast_tuple_target」パラメータを変更してTOASTが行われるデータサイズの下限値を小さくしたり、テーブルそのものを分割したりすればよいとのこと。また、オンライントランザクション処理を行わないデータウェアハウスなどでは、行単位ではなく列単位でデータを保存することで、特定の列に対するスキャンのパフォーマンスを上げることもあるそうです。
・関連記事
データベースの中身がほぼ削除されてネコの鳴き声だけが書き残される謎の「ニャー攻撃」が活発化 - GIGAZINE
無料で「実践ハイパフォーマンスMySQL 第3版」第8章が全文公開中 - GIGAZINE
GitHubっぽくデータベースのバージョン管理やホスティングができる「DoltHub」 - GIGAZINE
簡単操作でウェブ上にデータベースを作成して視覚的に操作もできる「Airtable」を使ってみた - GIGAZINE
・関連コンテンツ





in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article PostgreSQL should not store 'half-sized'….