GIGAZINEで使っているWebサーバ「PowerEdge T310」障害の一部始終

GIGAZINEの中核になるWebサーバ PowerEdge T310がここ最近頻繁にKernel Panicを起こし、サーバダウンする事態が発生、複数台構成なので閲覧しているGIGAZINE読者には何も影響がないのですが、内部的にこのまま放置することもできず、DELLのメーカーサポートに問い合わせなどを行うもののなかなか原因が特定できず、謎の現象となっていたものの、ようやくその原因が特定され、やっとこさなんとか回復しました。
同様のことで悩んでいる場合には問題特定のために役立つかもしれない、意外に悪戦苦闘した一部始終の記録は以下から。
・2011年5月16日
GIGAZINEの3台存在するWebサーバのうち1台がが停止しているのを発見。画面上では「Kernel Panic」の文字が出て、動作不能状態に陥っていたため、強制的に再起動を行うことに。
コンソールに表示された「Kernel Panic」の文字
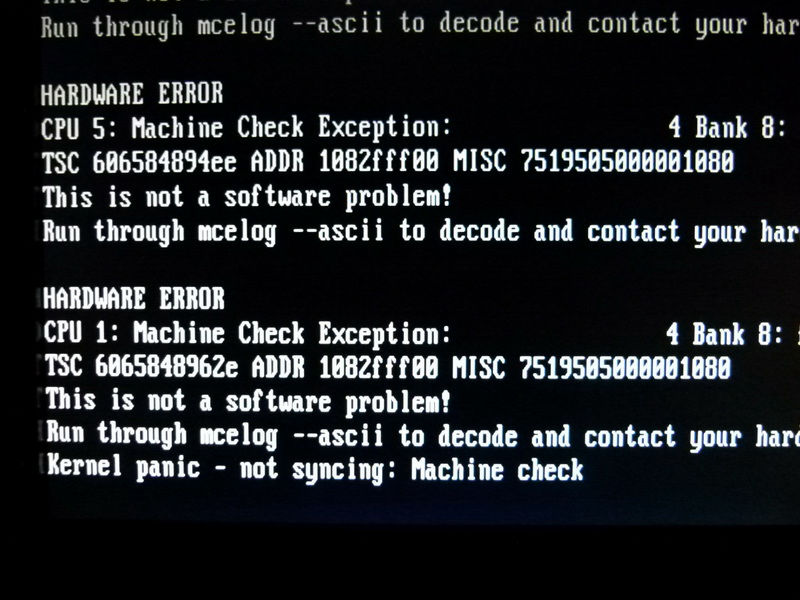
再起動後、/var/log/messagesログを確認すると、「Machine check events logged」の表示があったので、meclogを確認。meclogの中身を見ていると、以下のように「HARDWARE ERROR」ということで、ハードアウェアエラーである旨が表示され、中身としてはCPUのエラーが出ていることを確認したため、DELLテクニカルサポートへ連絡することに。
MCE 0
HARDWARE ERROR. This is *NOT* a software problem!
Please contact your hardware vendor
CPU 1 BANK 8 TSC 25fa59bc557218 [at 2926 Mhz 42 days 6:48:3 uptime (unreliable)]
MISC 8e02082000000186 ADDR 1082baf00
MCG status:
MCi status:
Error overflow
MCi_MISC register valid
MCi_ADDR register valid
MCA: MEMORY CONTROLLER RD_CHANNELunspecified_ERR
Transaction: Memory read error
STATUS cc0001800001009f MCGSTATUS 0
MCE 1
HARDWARE ERROR. This is *NOT* a software problem!
Please contact your hardware vendor
CPU 3 BANK 8 TSC 25fa59bc557420 [at 2926 Mhz 42 days 6:48:3 uptime (unreliable)]
MISC 8e02082000000186 ADDR 1082baf00
MCG status:
MCi status:
Error overflow
MCi_MISC register valid
MCi_ADDR register valid
MCA: MEMORY CONTROLLER RD_CHANNELunspecified_ERR
Transaction: Memory read error
STATUS cc0001800001009f MCGSTATUS 0
ハードウェア保守3年に入っているので、ここぞとばかりにDELLテクニカルサポートへの電話を決行。
Support.Jp.Dell.Com - テクニカルサポート(電話サポート)
正式な名称は「3年間翌営業日対応オンサイト保守サービス」という法人関係の保守サービス。いろいろな組み合わせができるような感じで、
・24時間365日電話サポート1
・3年間 DirectLine(ソフトウェア電話サポート) 1
・2-3年目翌営業日対応オンサイト保守サービス(出張修理) 1
・2-3年目パーツ保証1
・3年間翌営業日対応オンサイト保守サービス(6営業日9-17時)
が1つのくくりとして保守サービスに入っている形になっています。
説明用のPDFファイル
http://jpapp1.jp.dell.com/jp/downloads/pdf/catalog/ep_ss_hardware.pdf
DELLテクニカルサポートへ電話するとアナウンスが流れ、「エクスプレスサービスコードを入力して最後に#を押してください」とのこと。ガイダンスに従い、エクスプレスサービスコードを入力するも、何かをミスしているのか、同じガイダンスが何度も流れ続ける始末……。3回ほどエクスプレスサービスコードを入力したところで、ようやく次のアナウンスが流れ、保守サービス形態をガイダンス通りに入力するが、これも何度も何度もガイダンスが流れる状態に。3回ほど同じ入力を繰り返していると無音状態になったので、暫くそのまま放置。
-5分経過-
無音状態が続く
-10分経過-
さらに無音状態が続く
-15分経過-
……しびれを切らして電話を切る。編集部内の電話ではどうも正常にガイダンス通りの操作ができない様子なので、思い切って携帯電話からかけてみると、全て1回でオペレータまで繋がった。どうも、電話の機種で正常に操作できないことがあるらしい。
DELLテクニカルサポートに無事繋がったため状況を説明すると、BMCログを確認してほしいとのことなので、電話をそのままつなげたまま確認項目を誘導してもらうことに。BMCログを読み上げてDELLのオペレータに伝えたところ、エラーは検知されていない状態であるという事に。現状同様構成のサーバが3台あり、この1台だけで現在の現象が発生している事を伝え、他に確認する個所がないかどうかの確認を行うと、「Diagnostics診断ツール」でのログを取って解析してほしい、との回答。
そんなわけでDiagnostics診断ツールのダウンロード先と手順をメールで送付してもらい、ダウンロード。Diagnostics診断ツール作成プログラムをこのような画面に。
診断ツール起動メディアを作成する方法は以下の4つ。
1.フロッピーディスク
2.CD-Rなどでブート
3.USBメモリでのブート
4.PXEブート
ブランクCD-Rが手元になく、このサーバにはフロッピードライブは内蔵していない状態、PXEサーバもないことから、今回は「3.USBメモリでのブート」を選択。4GBのUSBメモリを接続して、診断ツール作成プログラムを実行。
ここでしっかりUSBメモリが認識しているかがわかるようになっている。4GBのUSBメモリ認識
OKボタンを押した瞬間、エラー画面に。
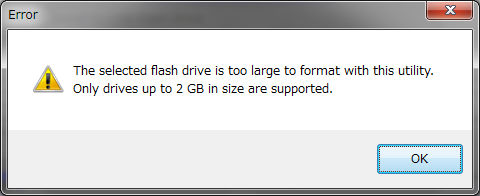
どうも、2GBまでのUSBメモリまでしか対応していないらしく、仕方ないので編集部内を探して、256MBのUSBメモリを発見。
さくっと接続して認識できていることを確認。
OKボタンを押すと、今度はインストール開始
10秒ほどで作成完了
今度はサーバに繋いでUSBメモリから起動すれば診断ツールログが採取できるはずなので、早速実施。しかし、なぜか起動しない……。ブート領域が正常に設定されていないからか、まったく起動してくれない状態。フォーマットして、ブートパーティションを作った状態で再作成をしても、まだ起動できない状態。時間も時間になってきたため、ブランクCD-Rを用意して翌日に作業を再開する予定とする。
・2011年5月17日
翌日、ブランクCD-Rを用意して診断ツールを作成。
ISOファイルを作成して、ブランクCD-Rへ書き込む方法と、そのまま直接CD-Rに書き込む方法が選択可能
今度こそ起動してくれ!という願いを込めてCD-Rを入れ、サーバを起動。CDブートの設定を行い、今度は正常に起動。
診断ツールのCDを起動した時のメニューはこんな感じ
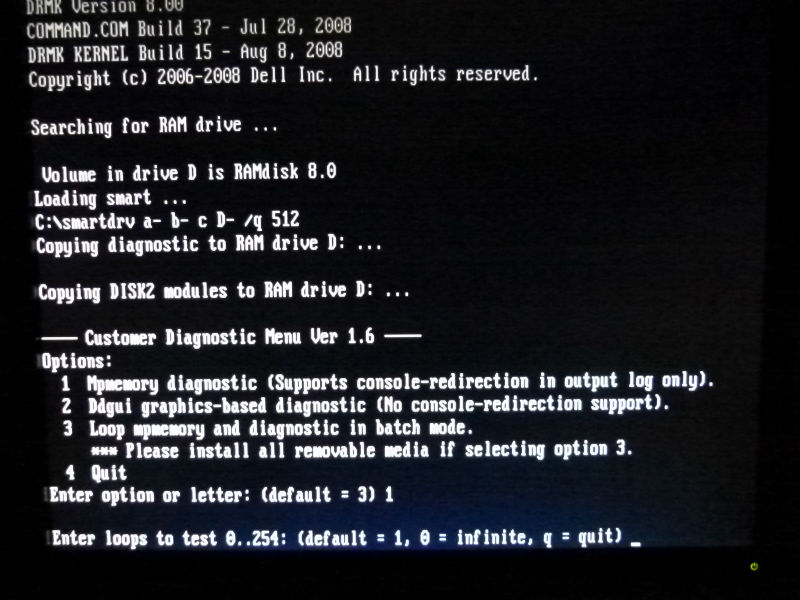
チェック手順に従いチェックツールを実行。これがCPUチェック実行画面。
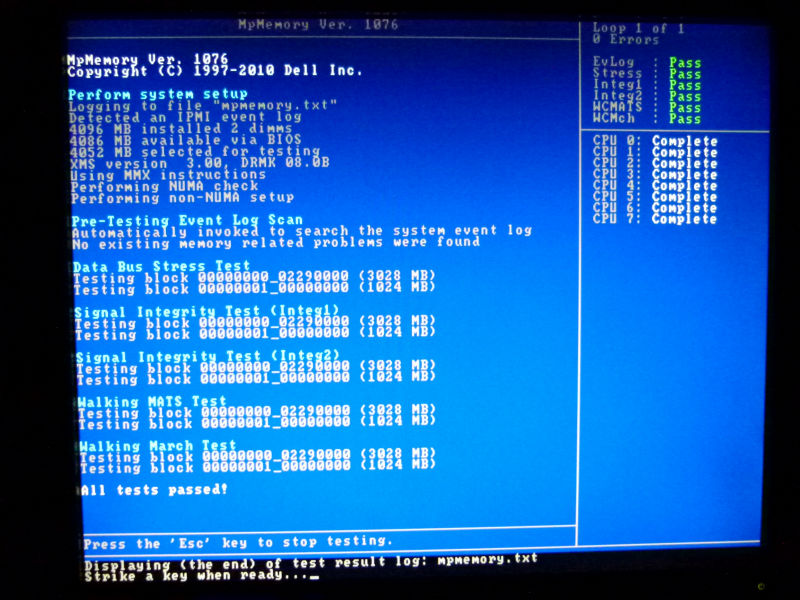
手順の通り、CPUのチェックを行うが、エラーもなく終了。ログを取得して送付したかったが、今度はログを保存するためのメディアが一切認識できないという状態に。というよりも、CDブートだとUSBメモリなどでの保存が一切きかないようなので、仕方なく画面を撮影してその画像をメールで送付。解析をしてもらうことに。その後、1時間以上たっても、連絡がなく、もう暫く待つものの、一向に連絡がない。再度、テクニカルサポートへ電話して状況の確認を行うと、エラーが無いので今の状態ではハードウェア交換などはできないとの回答。また、インストールしているOSがCentOS5のため、DELLのサーバではサポート外であること、さらにBIOSのバージョンが最新でないために最新のものにアップデートしてほしいとの注意もされる。さらに、メモリ側にエラーが無いかを確認して欲しいと言われ、メモリテスト手順を教えてもらい、再度チェックツールを実施。
同様の診断ツールにはハードウェア個々でチェックが行えるため、メモリチェックを行い、再度画面上での表示を撮影して送付しようと考えたが、画面上にでるログが多い割にログが表示される部分が少ないという状態だったため断念。USBメモリで保存できないかを確認するが、USBメモリを接続した状態で診断ツールを起動してもUSBメモリは認識しないという状況に陥り、他の手段を模索していたところ、USB接続のフロッピードライブを発見!!!
編集部内で発掘されたUSBフロッピードライブ(Logitec社製)

Windows 7 64Bitでもちゃんと認識しているので壊れていない模様
が、しかし、今度は肝心のフロッピーディスクが見当たらない。さらに探し回ることしばし、なんとかしてようやくフロッピーディスクを発見、今度はフロッピー版で診断ツールを作成。読み込み速度が足を引っ張るため、起動が段違いに遅いのはもう仕方ない状態。5分ほどしてから診断ツールがようやく起動。
診断ツールの画面はこんな感じ
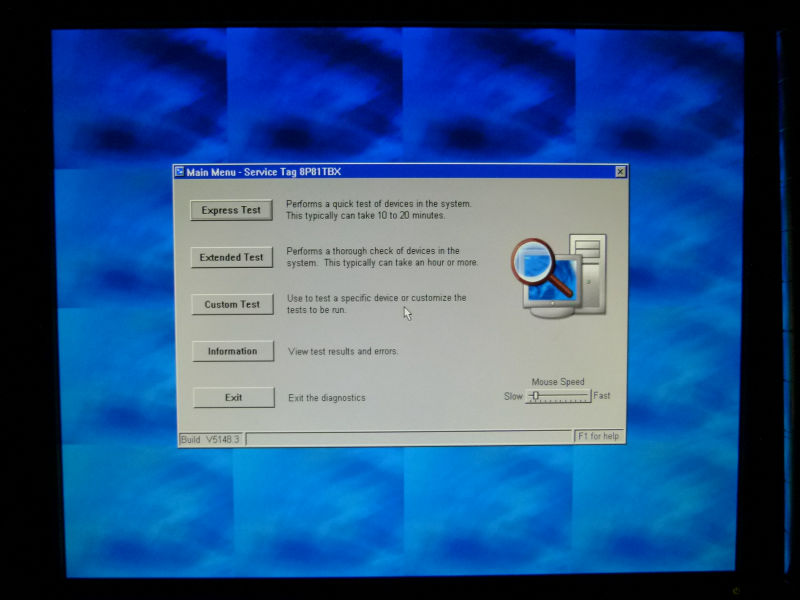
Custom Test画面
Custom Testを実行中の画面
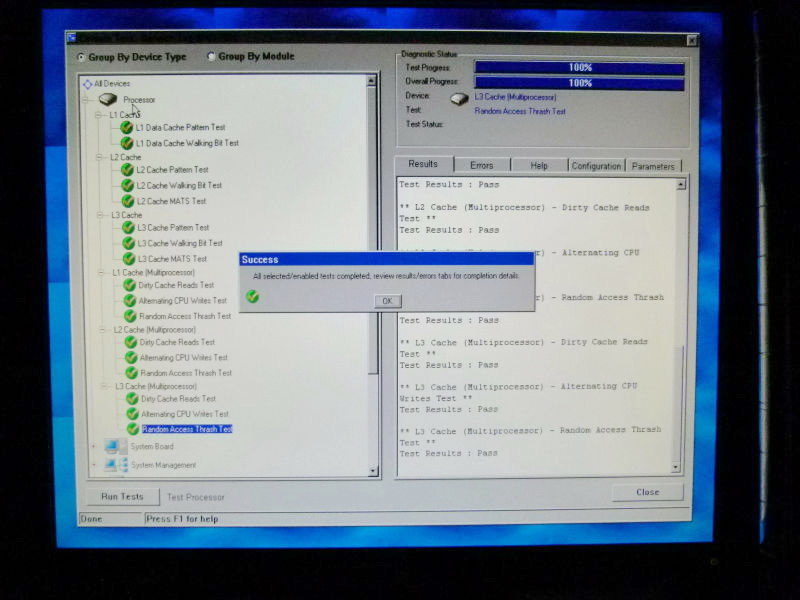
手順を実行し、ログの内容を一応確認するが、特にエラーらしきものはない。念のためログをそのままメールに添付して送付。
また、今回は最初から注意されていたが、インストールしているOSがCentOS5のため、DELLのサーバではサポート外であること、さらにBIOSのバージョンが最新でないために最新のものにアップデートしてほしいとの注意もあったため、そのための対処を検討に入れ始めることに。
・2011年5月30日
再度サーバダウン発生、今までと同様の現象でのサーバダウンであったため、とりあえず再起動を行い、サーバの各チェックを行うもエラーが無い状態。
・2011年6月13日
3度目のサーバダウン発生。この状態で同じサーバだけが3度も落ちるとは考えづらいため、DELLの診断ツールを使用せず、別視点でエラーチェックを行うことに。
●その1.stressを用いて、CPU・メモリ・I/Oなど個々と複合した状態のそれぞれで2~3時間負荷をかける。
使用した「stress」というのは以下のサイトにあるものを使用。
stress project page
http://weather.ou.edu/~apw/projects/stress/
ダウンロードとインストール手順、使い方などは以下を参照。
pclinuxtips @ ウィキ - Linux Stress Test
http://www46.atwiki.jp/pclinuxtips/pages/41.html
結果、頻繁に重くなるが、サーバダウンまで行かない状態。
●その2.通常起動してるだけでは落ちないが、Webサーバとして動作させると落ちる事から、abコマンドを使ってapacheプロセスを複数起動させた状態にする
結果、1時間半ほどずっと負荷をかけると、サーバダウンを起こし、同様のエラーが発生している事がわかる。
muninのApache Accessグラフも頻繁に落ちるが故にこんな状態になる
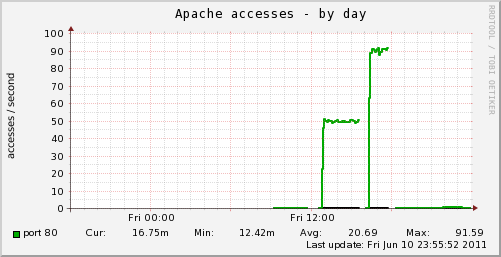
「その2」の状態を何度か試して、メモリ(vmstat)、CPU(mpstat)、I/O(iostat)、プロセスリスト(ps)のログを一定間隔でとっていると、CPU(mpstat)のログで違和感を感じる事に。
起動直後のmpstat
16時28分03秒 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
16時28分03秒 all 3.66 0.00 1.91 0.56 0.06 0.39 0.00 93.43 2874.36
16時28分03秒 0 3.61 0.00 1.99 0.94 0.00 0.11 0.00 93.35 1003.77
16時28分03秒 1 3.56 0.00 2.09 0.48 0.10 0.11 0.00 93.66 11.73
16時28分03秒 2 3.54 0.00 1.84 0.57 0.01 0.11 0.00 93.93 2.40
16時28分03秒 3 3.79 0.00 2.03 0.42 0.33 2.35 0.00 91.08 1852.12
16時28分03秒 4 3.50 0.00 1.85 0.56 0.00 0.09 0.00 93.99 0.00
16時28分03秒 5 3.50 0.00 1.88 0.48 0.00 0.11 0.00 94.04 0.79
16時28分03秒 6 3.53 0.00 1.84 0.50 0.00 0.12 0.00 94.01 1.21
16時28分03秒 7 4.22 0.00 1.75 0.52 0.01 0.09 0.00 93.41 2.34
負荷をかけた状態でサーバダウン直前のmpstat
17時49分03秒 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
17時49分03秒 all 12.28 0.01 5.99 2.13 0.13 1.02 0.00 78.45 6690.92
17時49分03秒 0 11.88 0.00 6.15 1.76 0.00 0.36 0.00 79.84 1001.06
17時49分03秒 1 12.00 0.00 6.07 1.63 0.08 0.31 0.00 79.91 11.88
17時49分03秒 2 11.95 0.08 6.00 5.38 0.05 0.35 0.00 76.19 10.55
17時49分03秒 3 12.51 0.00 6.13 1.41 0.89 5.78 0.00 73.29 5664.78
17時49分03秒 4 11.92 0.00 5.94 1.67 0.00 0.35 0.00 80.11 0.00
17時49分03秒 5 11.98 0.00 6.01 1.64 0.00 0.33 0.00 80.03 0.93
17時49分03秒 6 11.99 0.01 5.98 1.81 0.00 0.31 0.00 79.90 1.12
17時49分03秒 7 13.99 0.01 5.60 1.77 0.00 0.33 0.00 78.30 0.59
CPUの割り込み要求(Interrupt ReQuest、略してIRQ、上記では「irq」と表示されている部分)のCPU番号「3」に対して割り込み処理が多発して「0.89」という数値を示している状態に。
IRQよりも異常がよくわかる部分が、「intr/s(1秒間の平均処理割り込み数)」の項目で、サーバが起動したタイミングでも「1852.12」という通常でも高い値に対して、サーバダウン前はさらに高い「5664.78」という状態に。つまり、1つのCPUに対して処理割り込み要求が異常に多い状態が続いているので、本来マルチプロセッサとしての役割を果たしていないという状態であることが判明。
参考:mpstatコマンド - CPUの利用状況確認
http://www.syboos.jp/linux/doc/mpstat.html
他のWebサーバの場合、確かにintrの値が高いCPUは存在するのが、その場合、2~3CPUに分けられることによって平均して高いという状態に対して、今回のサーバは特定のCPUだけが高くなるという感じに。正常に動作している同型機サーバの場合、以下のような感じ。
16時43分04秒 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
16時43分04秒 all 8.05 0.00 0.74 0.29 0.08 0.96 0.00 89.88 1974.86
16時43分04秒 0 4.05 0.00 0.39 0.13 0.00 0.04 0.00 95.38 367.24
16時43分04秒 1 4.04 0.00 0.62 0.25 0.03 0.08 0.00 94.99 4.24
16時43分04秒 2 4.64 0.00 0.62 0.21 0.06 0.08 0.00 94.39 6.96
16時43分04秒 3 4.60 0.00 0.60 0.69 0.01 0.09 0.00 94.01 3.13
16時43分04秒 4 4.52 0.00 0.51 0.13 0.00 0.07 0.00 94.77 0.00
16時43分04秒 5 11.88 0.00 0.96 0.27 0.16 2.28 0.00 84.44 249.55
16時43分04秒 6 15.95 0.00 1.15 0.38 0.18 2.67 0.00 79.67 430.04
16時43分04秒 7 14.74 0.00 1.08 0.29 0.15 2.35 0.00 81.38 295.00
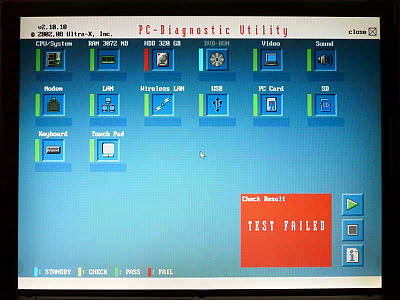
他のサーバなどを確認しても、同様の現象は発生せず、このサーバだけで発生する事象だったため、再度DELLの診断ツールを行おうとすると、そもそも診断ツール起動中にエラーが出ることがわかった。
診断ツール起動エラー
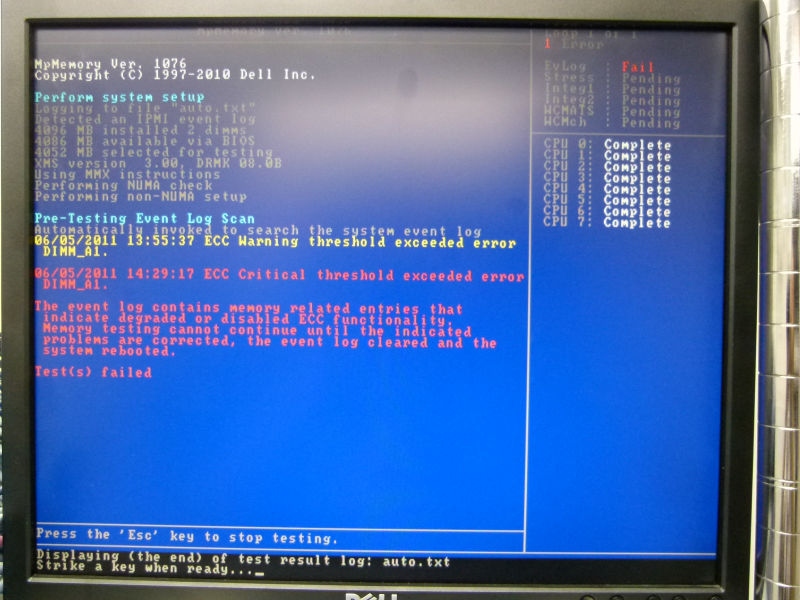
ここで再度DELLテクニカルサポートに電話するが、「技術問題のためおつなぎできません、時間をおいてもう一度……」とアナウンスが流れる。「技術問題……?」とは思ったが、30分ほどしてから再度電話を入れるとすんなり繋がったので、経緯と現状を説明。エラー情報を送ってほしいと言われたので、メールで送付をして1時間ほどしてコールバック、DELLによるとCPUのエラーではなくメモリエラーのため、情報採取用のツールを送るので、それで情報採取を行って再度メールしてほしいとのこと。
前回の診断ツールとは違い、今回はBMCから直接ログを採取する方法なのでサーバ側の設定と、クライアントとなるPCでプログラムを実行するだけでよいものとのことで、前回のような手順は踏まずに済むらしい。
送られてきたZIPファイルを解凍、そのままCドライブ直下にexeファイルを置いて手順通りコマンドプロンプトからコマンドの実行。
IPMIログ採取ツールの実行画面
念のため内容を確認すると、以下のエラーが出ていることがわかる。
Severity : critical
Date and Time : Mon Jun 13 04:02:16 2011
Description : ECC Uncorr Err: memory sensor, uncorrectable ECC ( Memory Board J DIMM1 ) was asserted
そのままの情報をメールで送信して再度テクニカルサポートへ連絡。内容を確認してもらうと、「メモリが1本認識してないため、今のような状態になっています。メモリ交換の手配をとりますので……」ということで、ようやくハードウェア交換の手配がとれ、メモリと作業員が来ることに。
この際に以下の注意事項を言い渡される。
1.メモリ交換のためサーバのシャットダウンが必要になるのでバックアップしておいてほしい
2.メモリ交換を行っても、前面パネルのアラートは消えないので、メモリ交換時に作業員がアラートの解除作業を行う
3.サポート外のOSの為、今回のメモリ交換作業・アラート解除を行っても、正常に動作しない可能性があるので、その際はOSの入替を検討してほしい
注意事項に関しては、内容確認のみにして翌日の交換作業に備えた状態にする。
・2011年6月14日
メモリ交換作業日、午前9時過ぎにDELLからメモリが届き、後は手配しているDELLの作業員が来るのを待つばかり。9時50分頃に作業員が到着、スーツをびしっと着た作業員だったため、少し驚くがサーバ室に案内して現状の確認を作業員と行う。
送られてきた交換用メモリ(作業員渡しのため梱包のまま)

なお、6月13日に電話でやりとりしたのが11時頃、DELLのサポートから「メモリ障害のため交換の手配します」となったのが同日15時頃、そして部品が手配されたのは以下の写真右側にあるシールでわかるように、17:04にDESPATCH(大至急で発送)されているので、しっかり障害個所が確定してから手配されたというのがわかります。

その後15分ほどで、メモリ交換作業完了。さすがにあっけないものでした。
その後、稼働確認のために、作業員がサーバを起動、BMCログを確認してもエラーがないため、問題無く交換作業が終わった状態。
あとはこちら側の稼働確認をとり、サーバ起動時のエラーなどがないことや、以前に出ているmcelog上のエラーがないこと、また内部的にGigazineが閲覧できることを確認してすべて完了。そして今現在、GIGAZINEのWebサーバは元気に稼働している状態です。
今回の教訓:フロッピーディスクはまだ活躍できるかもしれない。
・関連記事
「TeraStation」のHDDが故障したので新しいHDDと交換してみました
GIGAZINEサーバ電気工事の裏側を公開、本日午前9時から午後6時までの一時停電を乗り越えろ!
「RAIDを過信してはいけない」、データのバックアップやRAID復旧についてHDDのプロに聞いてみた
・関連コンテンツ