




ウェブ検索機能をオンにした状態で最も優れたAIですら約30%のケースで事実誤認の「ハルシネーション」を起こすと研究で判明

スイスのEPFL(スイス連邦工科大学ローザンヌ校)や欧州のAI研究組織であるELLISの研究チームがAIの事実誤認であるハルシネーション(幻覚)を測定するための新たなベンチマーク「HalluHard」を開発しました。この調査の結果、ウェブ検索機能を有効にした最新のフラッグシップモデルであっても、約30%の確率で誤った情報を生成することが明らかになりました。
HalluHard - Hallucination Benchmark Leaderboard
https://halluhard.com/
GitHub - epfml/halluhard: A Hard Multi-Turn Hallucination Benchmark
https://github.com/epfml/halluhard
[2602.01031] HalluHard: A Hard Multi-Turn Hallucination Benchmark
https://arxiv.org/abs/2602.01031
HalluHardは、従来の単発の質問形式とは異なり、現実的な3ターンのマルチターン会話形式で評価を行うことが特徴です。法的事例(250問)、研究上の質問(250問)、医学ガイドライン(250問)、プログラミング(200問)という、4つの機密性の高い専門ドメインにわたる合計950件の質問に基づき検証が行われます。各回答に対しては、PDF文書を含む引用文献の解析やウェブ検索を駆使した厳格な検証プロセスが適用されます。
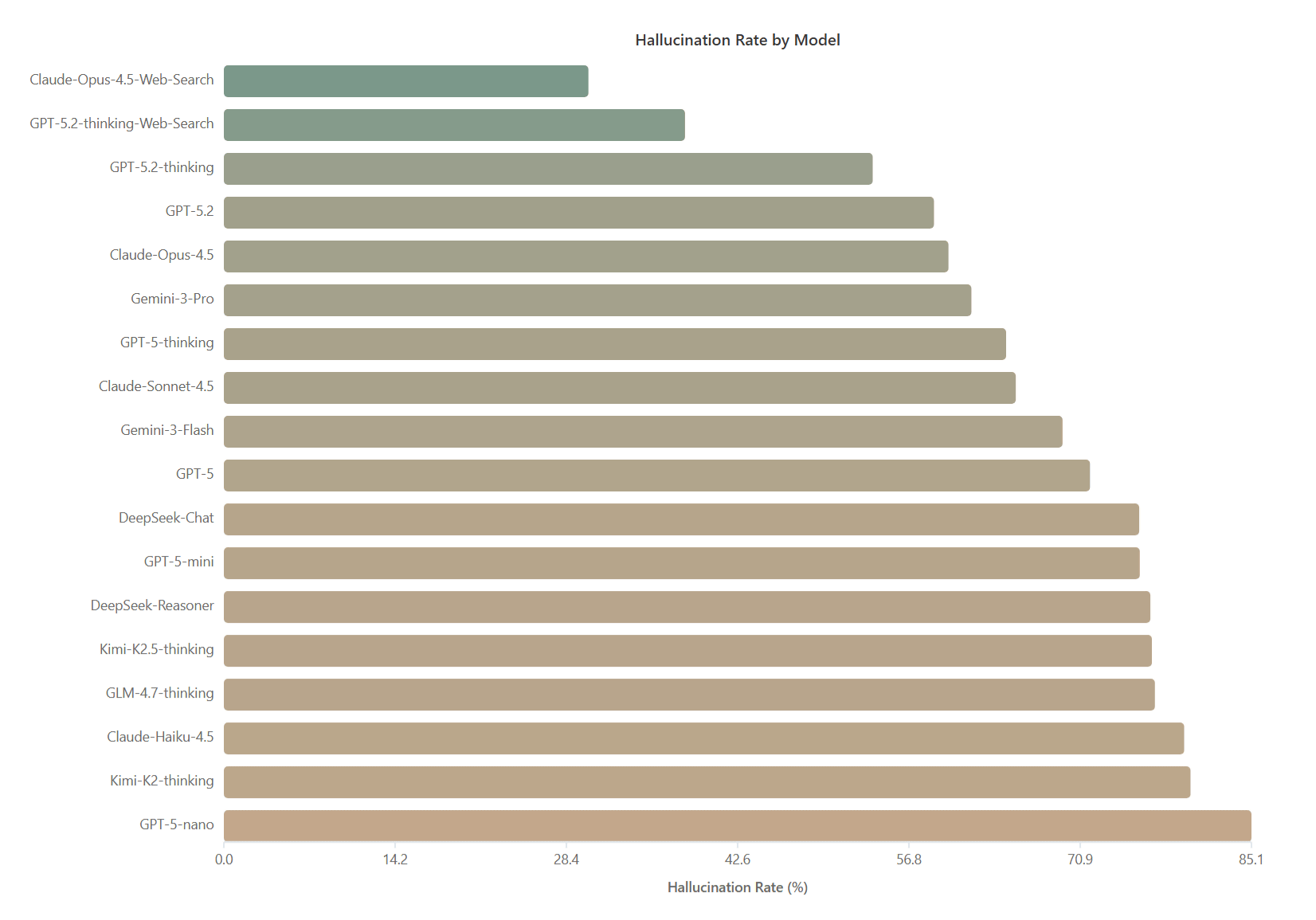
HalluHardをさまざまなAIに実施した結果、最もハルシネーション率が低かったのはウェブ検索を併用したClaude-Opus-4.5で、平均ハルシネーション率が30.2%でした。これに次いで、ウェブ検索を併用したGPT-5.2-thinkingが38.2%を記録。ウェブ検索を使わない場合のClaude-Opus-4.5のハルシネーション率は60.0%に達するため、検索機能は精度を向上させますが完全な解決策にはなっていないことが示されたと研究チームは論じています。
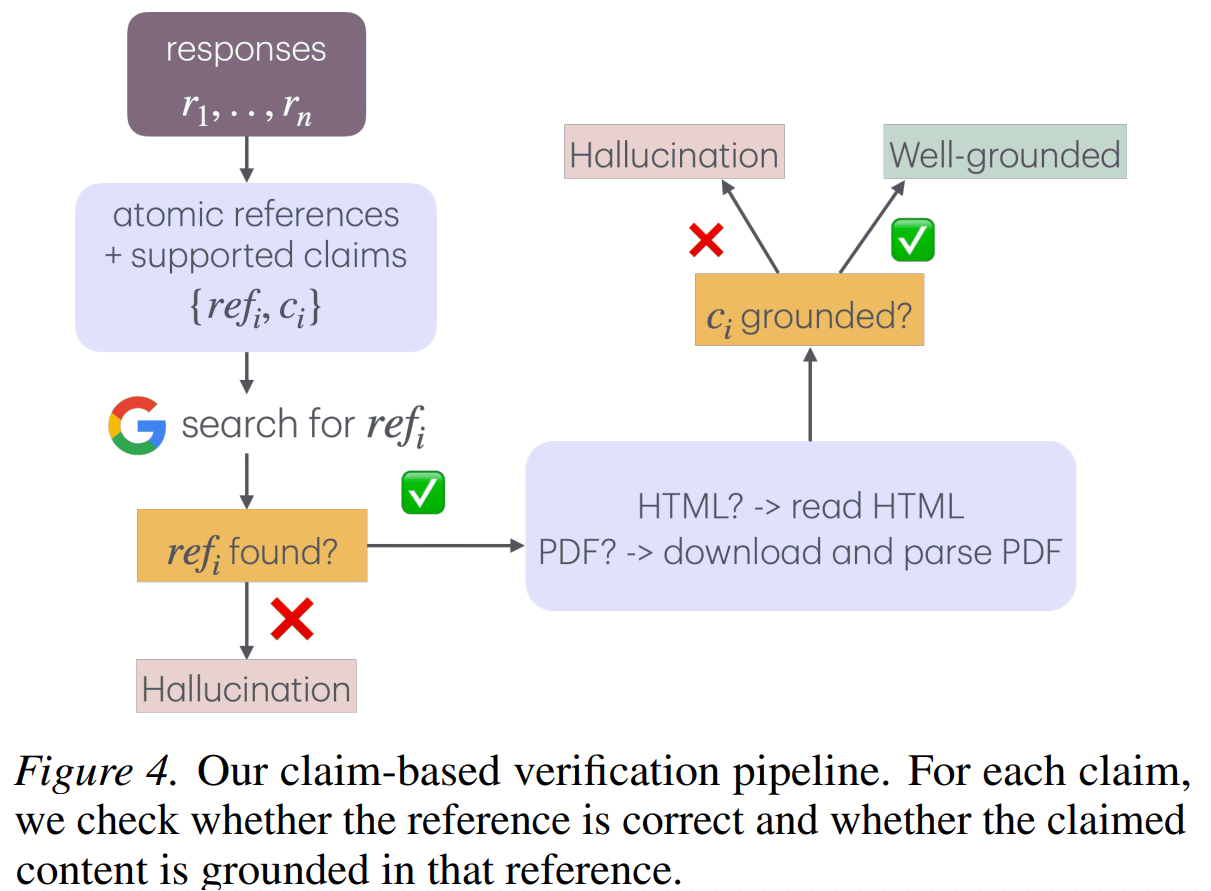
さらに研究チームはハルシネーションを、引用元が存在するかを確認する「リファレンス・グラウンディング」と、その引用元が実際に主張を裏付けているかを検証する「コンテント・グラウンディング」の2段階で評価しました。
その結果、ウェブ検索は実在する出典を引用する能力を高めますが、生成された内容が実際に出典に基づいているかを担保する能力は乏しいことが判明しました。たとえば、Claude-Opus-4.5ではウェブ検索により引用エラーは38.6%から7.0%へと大幅に減少しましたが、内容そのものの誤りは83.9%から29.5%への改善に留まっています。同様にGPT-5.2-thinkingも検索によって引用エラーは6.4%まで下がりますが、内容の誤りは51.6%という高い水準で残りました。
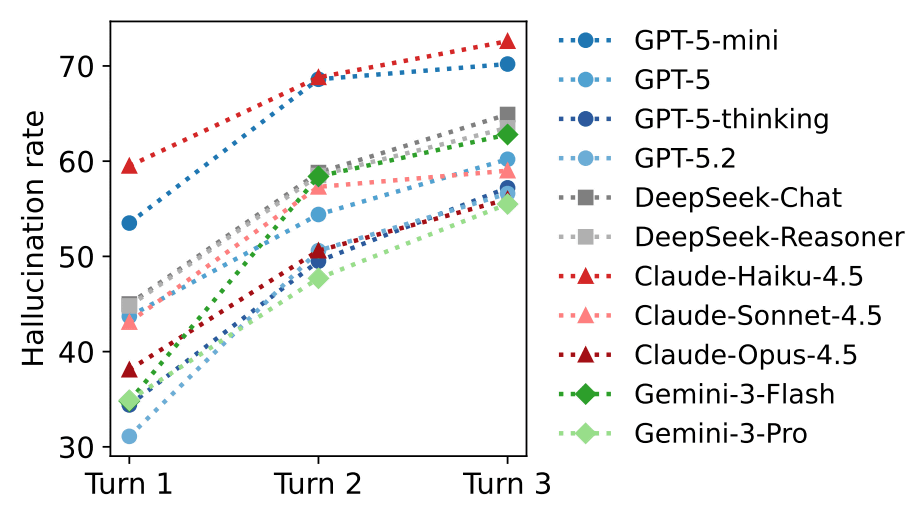
また、会話が長くなるほどハルシネーションが悪化する傾向も確認されました。モデルが自分自身の以前の誤りを文脈として参照し、その間違いを前提に回答を構築してしまう自己条件付け効果により、第1ターンでの誤った参照の3〜20%が後のターンで再登場することが示されています。ただし、プログラミング関連においては、会話が進むにつれてタスクが具体的かつ狭い範囲に絞り込まれるため、例外的にハルシネーション率が低下する傾向が見られました。
さらにモデルの規模が大きくなるほどハルシネーションは減少します。GPT-5ファミリーでは、nano(85.1%)からmini(75.9%)、標準のGPT-5(71.8%)、thinking(64.8%)、最新の5.2-thinking(53.8%)へと改善が見られます。Claudeも同様にHaiku(79.5%)、Sonnet(65.6%)、Opus(60.0%)と能力に比例します。思考プロセスを強化する推論能力はハルシネーションの抑制に役立ちますが、回答が長く詳細になる分、かえって誤りを含むリスクが高まるという逆説的な現象も報告されています。特にDeepSeek-Reasonerは、DeepSeek-Chatと比較してハルシネーション行動に有意な差が見られませんでした。
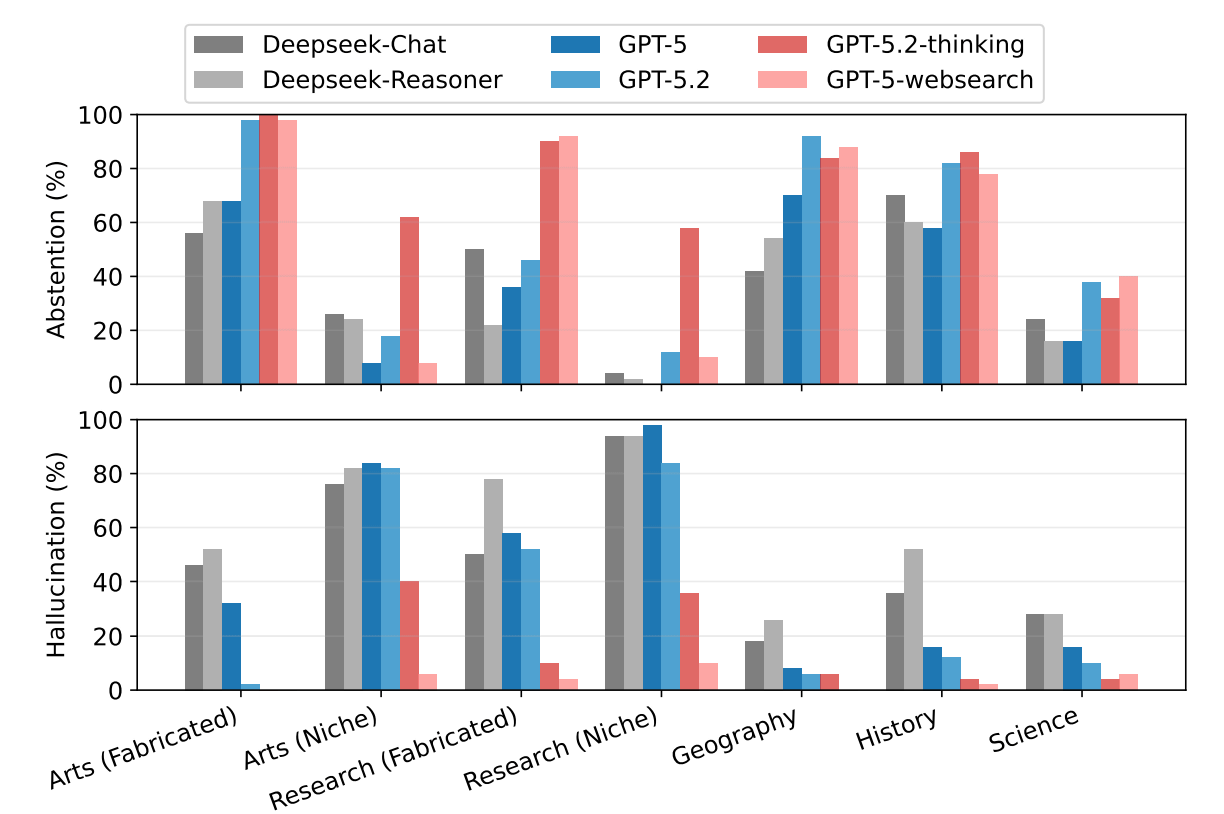
AIが情報を誤認する原因には、知識の知名度が深く関わっています。全くの作り話に対しては回答を拒否する傾向がありますが、実在はしても情報が少ない「ニッチな知識」については、学習データのわずかな記憶をもとに推測で答えてしまいます。これが「危険な中間地帯」と呼ばれる状態で、中途半端に知っていることが仇となり、不足した詳細を勝手に作り出すことで事実誤認が発生します。
こうしたAIの限界を測るHalluHardは、10件の回答を検証する検索費用が0.11ドル(約17.1円)と低コストでありながら、極めて高い精度での検証が可能だとのこと。既存の評価手法が飽和状態にある今、複雑な対話におけるAIの信頼性を担保し、不確実性を正しく認識させるための重要な基準となります。
研究チームは、既存のベンチマークが飽和しモデル間の差別化が困難になる中で、HalluHardのような難易度の高い検証環境がAIの信頼性向上に不可欠であると結論付けています。
・関連記事
GPTZeroがNeurIPS 2025採択論文から新たに100件のハルシネーション(幻覚)を検出 - GIGAZINE
AIに幻覚やハッキングを自白させて訓練する「告解」アプローチをOpenAIが開発 - GIGAZINE
GPT-5のような大規模言語モデルがなぜ幻覚を起こしてしまうのかをOpenAIの研究チームが論文で発表 - GIGAZINE
Anthropicが裁判の提出資料でAIが生成した「幻覚」の論文をソースにした疑惑、Anthropic側弁護士は「単なる引用ミス」と弁解 - GIGAZINE
OpenAIの「o3」と「o4-mini」は従来のAIよりも「幻覚」を起こしやすいことが判明 - GIGAZINE
生成AIの幻覚で指定される「架空のパッケージ」に悪用の危険性があるとセキュリティ研究者が警告 - GIGAZINE
・関連コンテンツ






in AI, Posted by log1i_yk
You can read the machine translated English article Research reveals that even the best AI w….