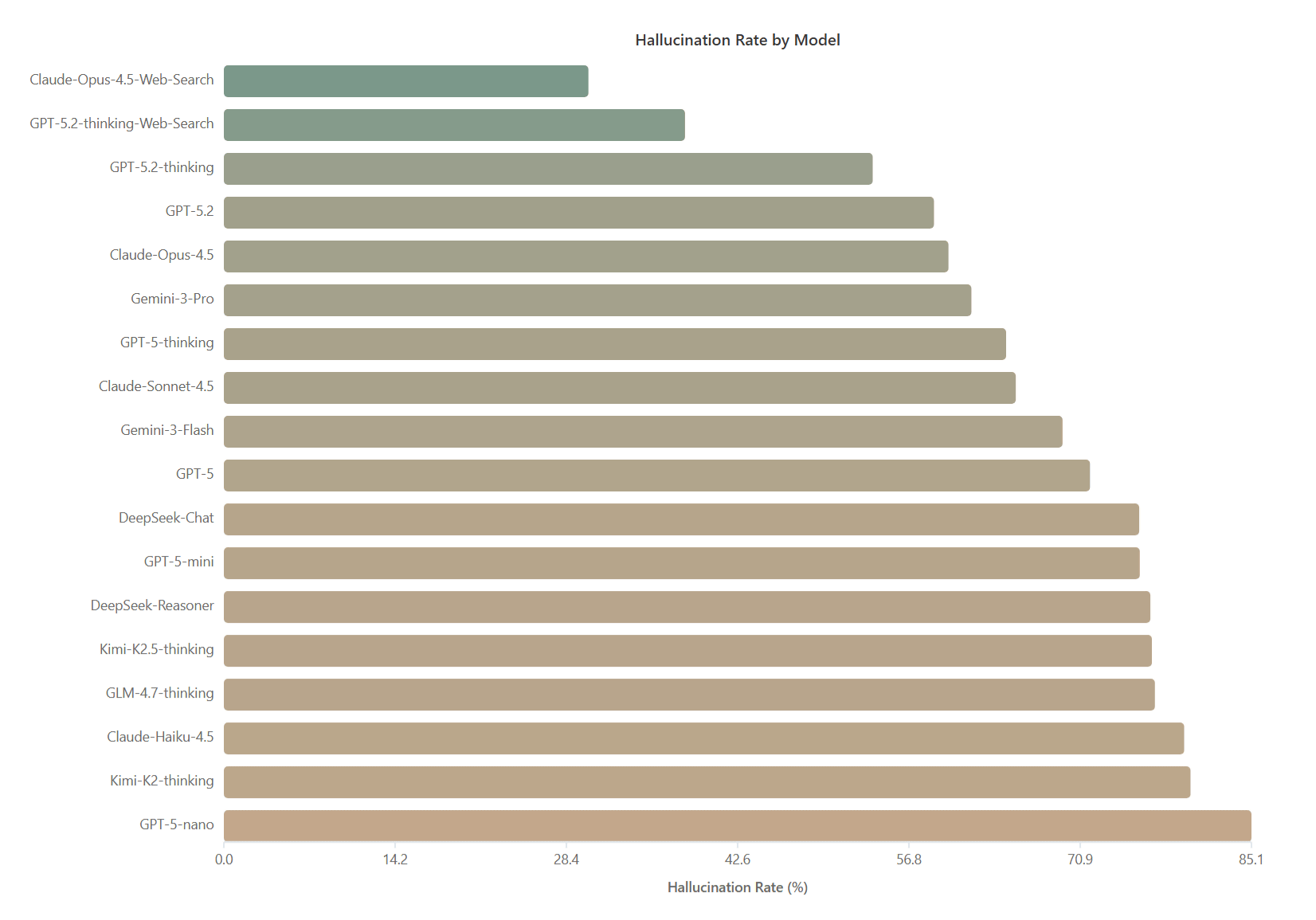
Research reveals that even the best AI with web search turned on experiences false beliefs in about 30% of cases

A research team from the Swiss Federal Institute of Technology in Lausanne (EPFL) and the European AI research organization
HalluHard - Hallucination Benchmark Leaderboard
https://halluhard.com/
GitHub - epfml/halluhard: A Hard Multi-Turn Hallucination Benchmark
https://github.com/epfml/halluhard
[2602.01031] HalluHard: A Hard Multi-Turn Hallucination Benchmark
https://arxiv.org/abs/2602.01031
Unlike traditional single-question assessments, HalluHard uses a realistic, multi-turn, three-turn conversation format. Responses are assessed based on a total of 950 questions across four highly sensitive domains: legal cases (250 questions), research questions (250 questions), medical guidelines (250 questions), and programming (200 questions). Each response undergoes a rigorous validation process, including analysis of citations, including PDF documents, and web searches.
When HalluHard was applied to various AIs, the lowest hallucination rate was found to be Claude-Opus-4.5, which used web search, with an average hallucination rate of 30.2%. This was followed by GPT-5.2-thinking, which used web search, with a hallucination rate of 38.2%. The hallucination rate for Claude-Opus-4.5 without web search reached 60.0%, indicating that search functionality improves accuracy but is not a complete solution, the research team argues.
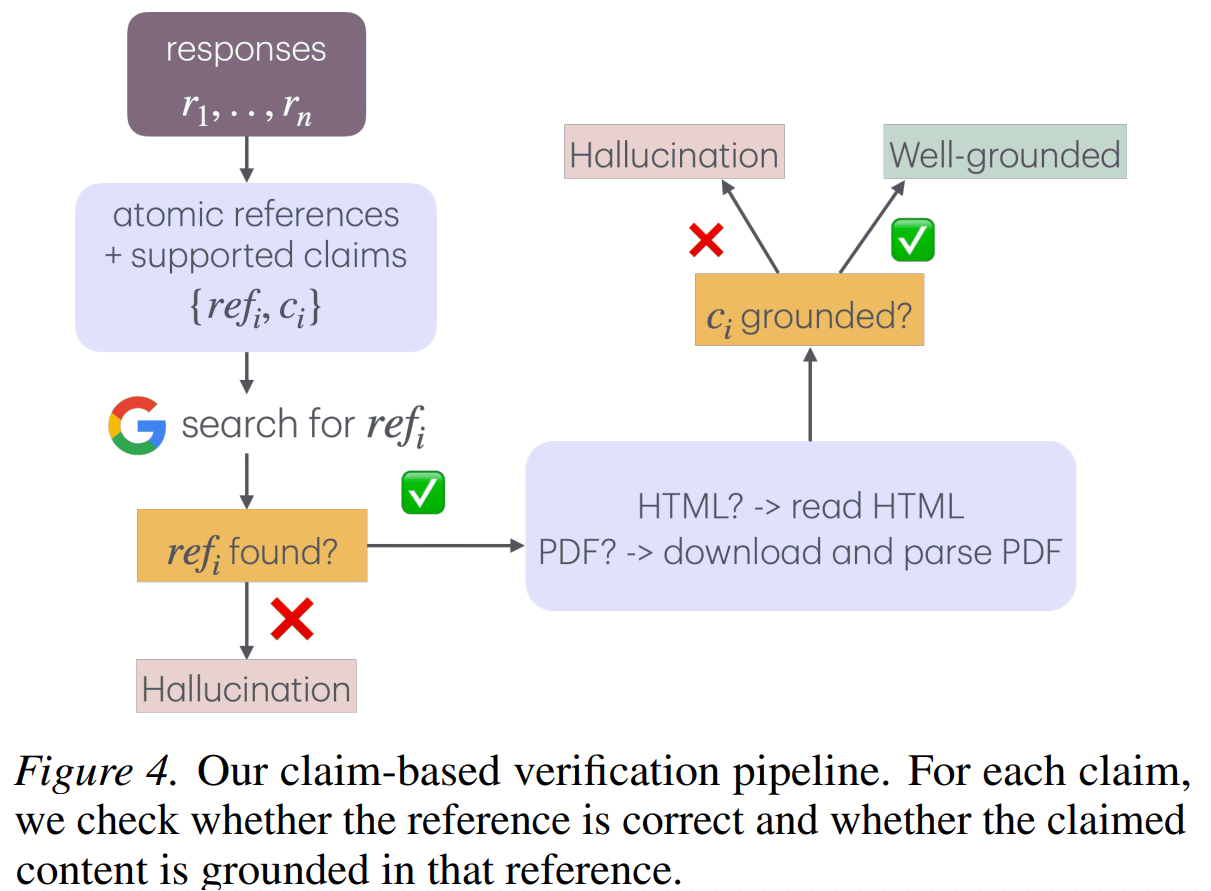
The research team then assessed hallucination in two stages: 'reference grounding,' which checks whether a source exists, and 'content grounding,' which verifies whether the source actually supports the claim.
We found that web search improves the ability to cite real sources, but does little to ensure that generated content is actually based on those sources. For example, in Claude-Opus-4.5, web search significantly reduced citation errors from 38.6% to 7.0%, but only improved content errors from 83.9% to 29.5%. Similarly, in GPT-5.2-thinking, web search reduced citation errors to 6.4%, but content errors remained high at 51.6%.
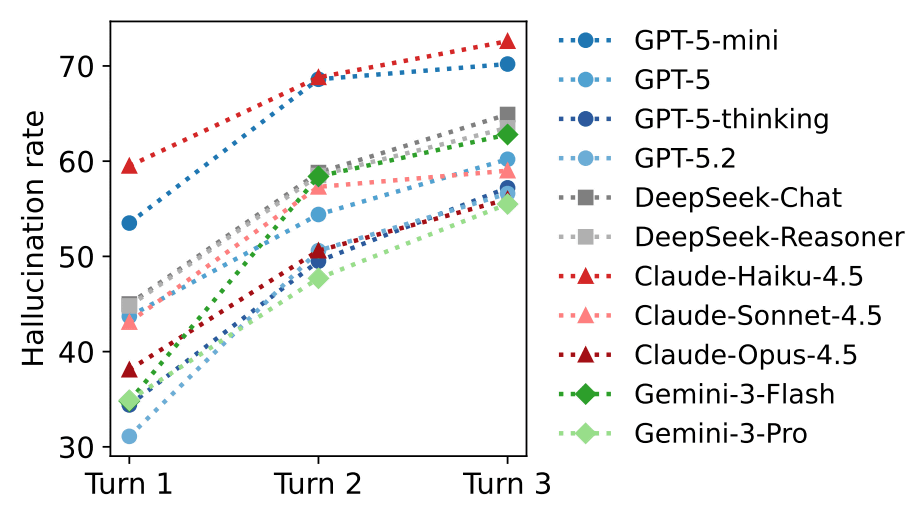
We also observed a tendency for hallucination to worsen as the conversation continued. Due to a self-conditioning effect, where the model references its own previous errors as context and constructs answers based on those errors, 3-20% of incorrect references in the first turn reappear in later turns. However, in programming-related tasks, the hallucination rate tended to decrease exceptionally as the conversation progressed, as the task became more specific and narrower in scope.
Furthermore, hallucination decreases as the model size increases. In the GPT-5 family, improvements are seen from nano (85.1%) to mini (75.9%), standard GPT-5 (71.8%), thinking (64.8%), and the latest 5.2-thinking (53.8%). Claude's performance also increases with ability, from Haiku (79.5%) to Sonnet (65.6%) and Opus (60.0%). While reasoning ability, which enhances thought processes, helps reduce hallucination, a paradoxical phenomenon has also been reported: longer and more detailed answers increase the risk of errors. In particular, DeepSeek-Reasoner showed no significant difference in hallucination behavior compared to DeepSeek-Chat.
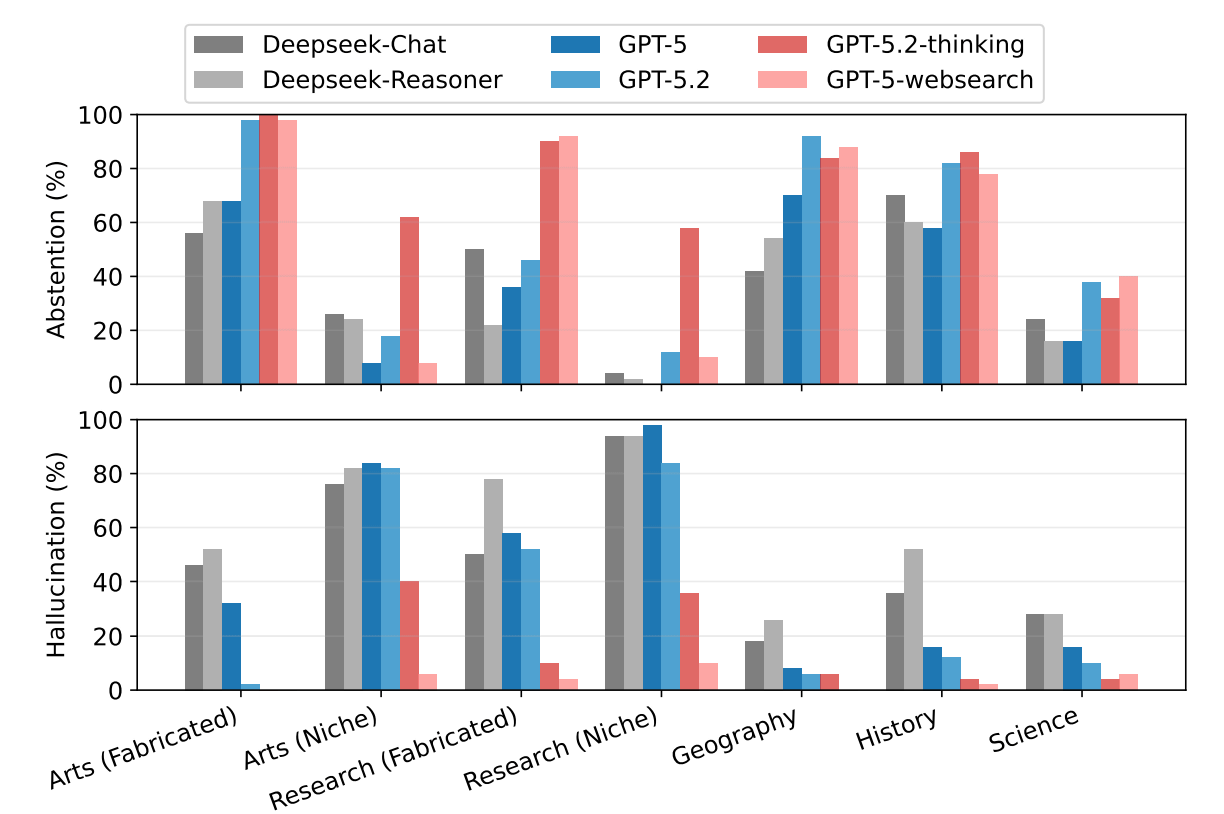
The reason why AI misinterprets information is closely related to the level of knowledge it has. It tends to refuse to respond to completely fabricated stories, but when it comes to 'niche knowledge' that exists but has little information, it will make guesses based on the limited memory of training data. This is known as the 'dangerous middle ground,' where partial knowledge can be detrimental, and the AI will invent missing details, leading to factual errors.
HalluHard, which measures the limits of AI, is said to be extremely accurate despite the low cost of testing 10 answers (just $0.11). With existing evaluation methods reaching saturation, this will be an important benchmark for ensuring the reliability of AI in complex dialogues and for correctly recognizing uncertainty.
The research team concludes that as existing benchmarks become saturated and it becomes difficult to differentiate between models, a challenging verification environment like HalluHard is essential to improving the reliability of AI.
Related Posts:







in AI, Posted by log1i_yk