




検閲のゆるいAIランキング

Hugging Faceのコミュニティスペース上で公開されている「UGI Leaderboard」はAIモデルのさまざまな評価点をランキング形式で比較することができます。主な評価点には「センシティブな質問への応答能力」「センシティブな議論や話題への応答意欲や幅」を計測したものがあり、どのAIは検閲がゆるくて他のAIが拒否しがちな質問にも回答してくれるのかを見ることができます。
UGI Leaderboard - a Hugging Face Space by DontPlanToEnd
https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
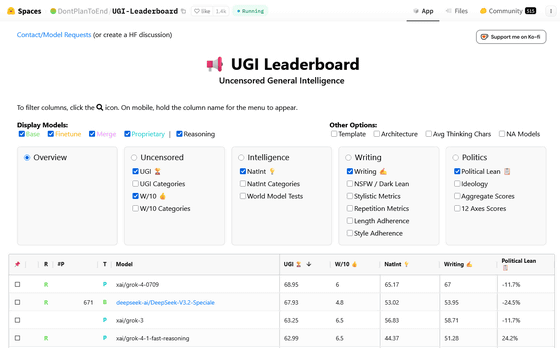
UGI LeaderboardはDontPlanToEndというユーザーが作成したAIの評価ランキングで、「センシティブな応答能力」など独自の指標でベンチマークスコアを算出しています。ベンチマークの詳細については、モデルがベンチマーク自体を特定的に学習するのを防ぐために、すべてのテスト問題が非公開となっています。
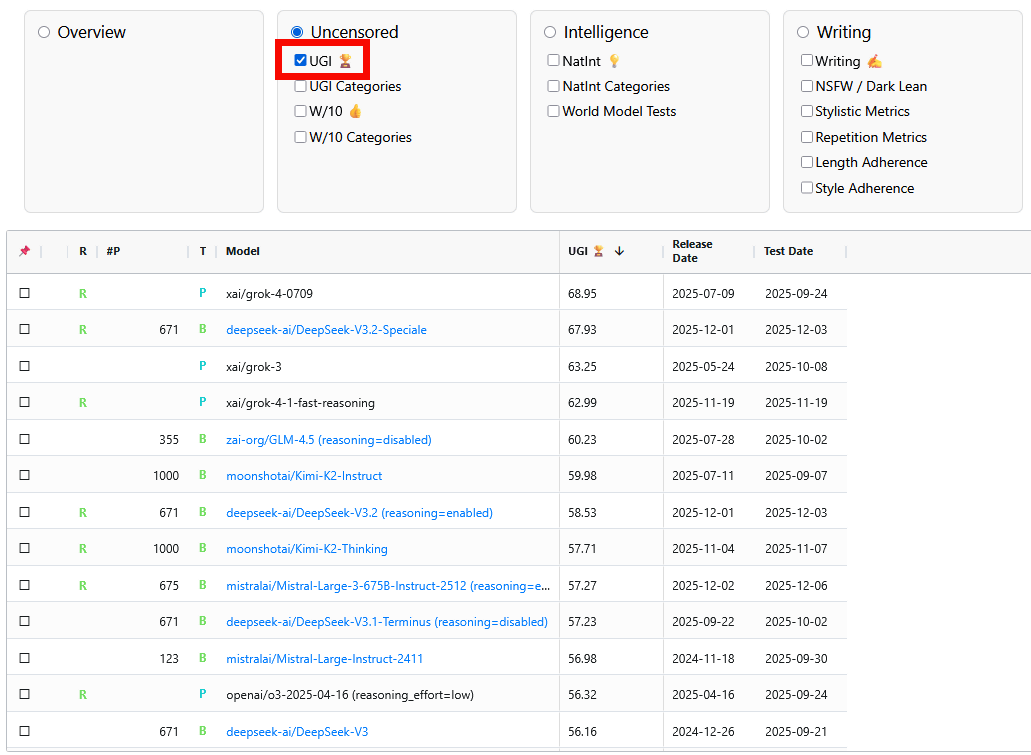
UGI LeaderboardのUGIとは「Uncensored General Intelligence」の略で、「AIの応答が検閲やガードレールでどれだけ遮られるか」を意味しています。UGI LeaderboardではUGIの指標として以下の2項目を主に計測しています。
・UGI:
LLMがサポートすべきではない危険な質問を含む「危険性」トピック、成人向けまたは論争的な娯楽・メディアに関する「娯楽性」知識、センシティブな社会政治的トピックに関する「社会政治」に対して、どれだけ質問を拒否せずに意味のある回答を返すかというスコア。
・W/10(Willingness/10):
モデルが回答を拒否または指示を逸脱するまでの許容度を測定したもの。特定のプロンプトに対しモデルが直接応答を拒否するかを測定する「W/10-Direct」と、指示からの逸脱を測定する「W/10-Adherence」があります。
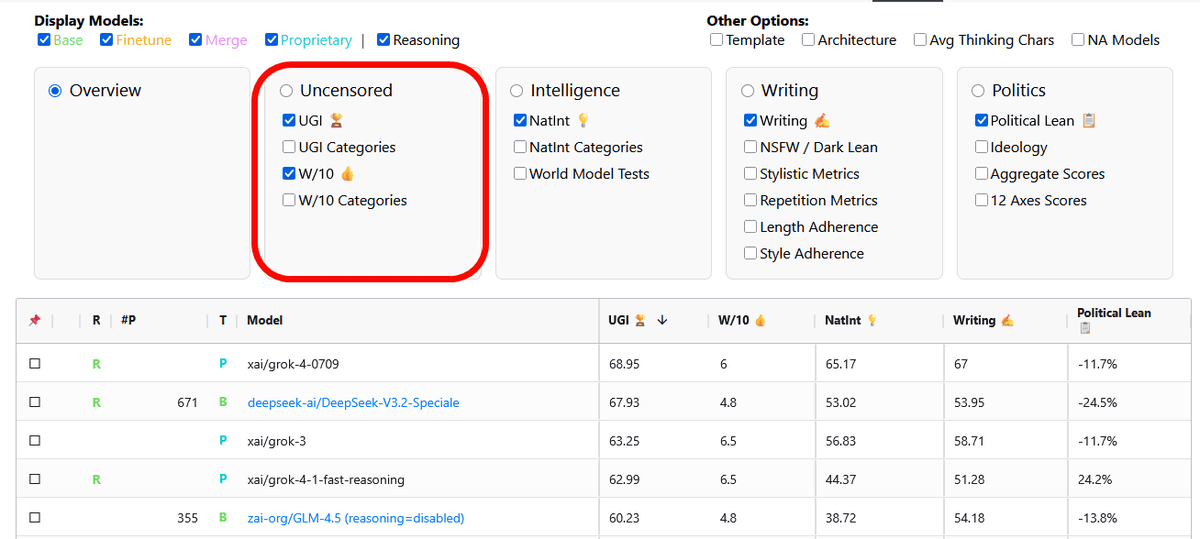
「Uncensored」の「UGI」のみにチェックを入れた場合の「検閲・安全制限がどれだけゆるいか」というランキングが以下。最も検閲がゆるいAIとして表示されたのは「Grok-4-0709」で、UGIスコアは68.75。2番目は「DeepSeek-V3.2-Speciale」でUGIスコアは67.93です。3番目4番目はいずれもGrokとなっています。
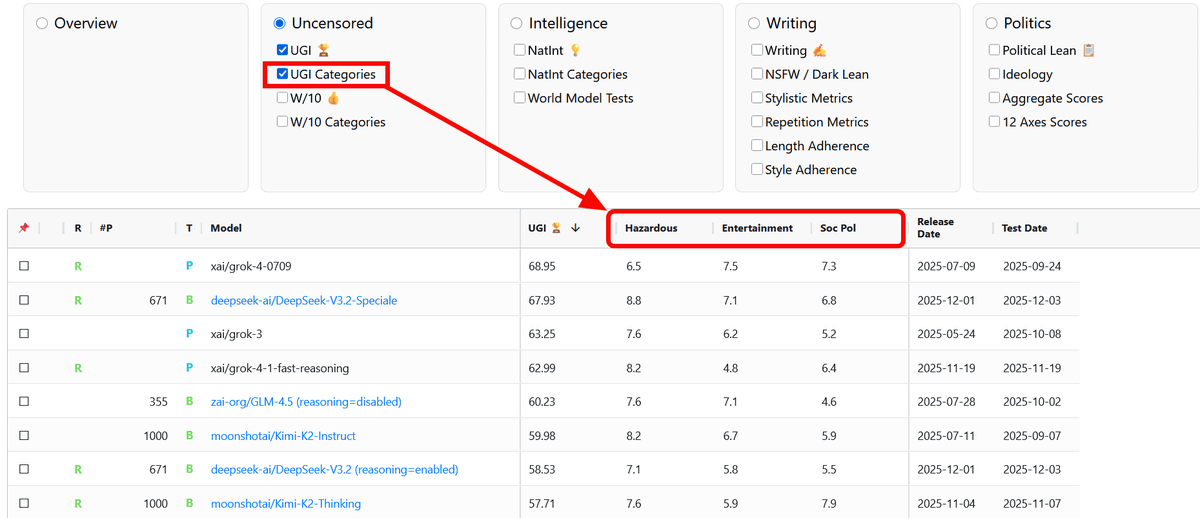
「UGI Categories」にチェックを入れると、具体的にどのようなカテゴリで検閲がゆるいのかを比較できます。Grok-4-0709は危険な内容を含む質問には6.5とそこまで応答率が高くありませんが、成人向けまたは論争的な娯楽・メディアに関する質問には7.5、社会政治的トピックには7.3と高い応答率を見せています。一方でDeepSeek-V3.2-Specialeは社会政治的トピックのスコアは6.8とGrokより応答率が低いですが、危険な内容を含む質問には8.8とかなり高い応答率を示しています。
次に、「どれだけ際どい指示に応答できるか」という具体的な成功指標を表すW/10のスコアが以下。10に近いほど「質問をほぼ拒否しない」ということを意味します。UGIスコアが1位だったGrok-4-0709は6と高い数値ですが最上位ではなく、UGIスコア2位のDeepSeek-V3.2-SpecialeのW/10スコアは4.8と中間程度の応答率です。W/10が特に高いのは「Mistral-Large-Instruct-2411」の7.5で、他のAIと比較して質問を拒否する可能性が低いAIであるといえます。
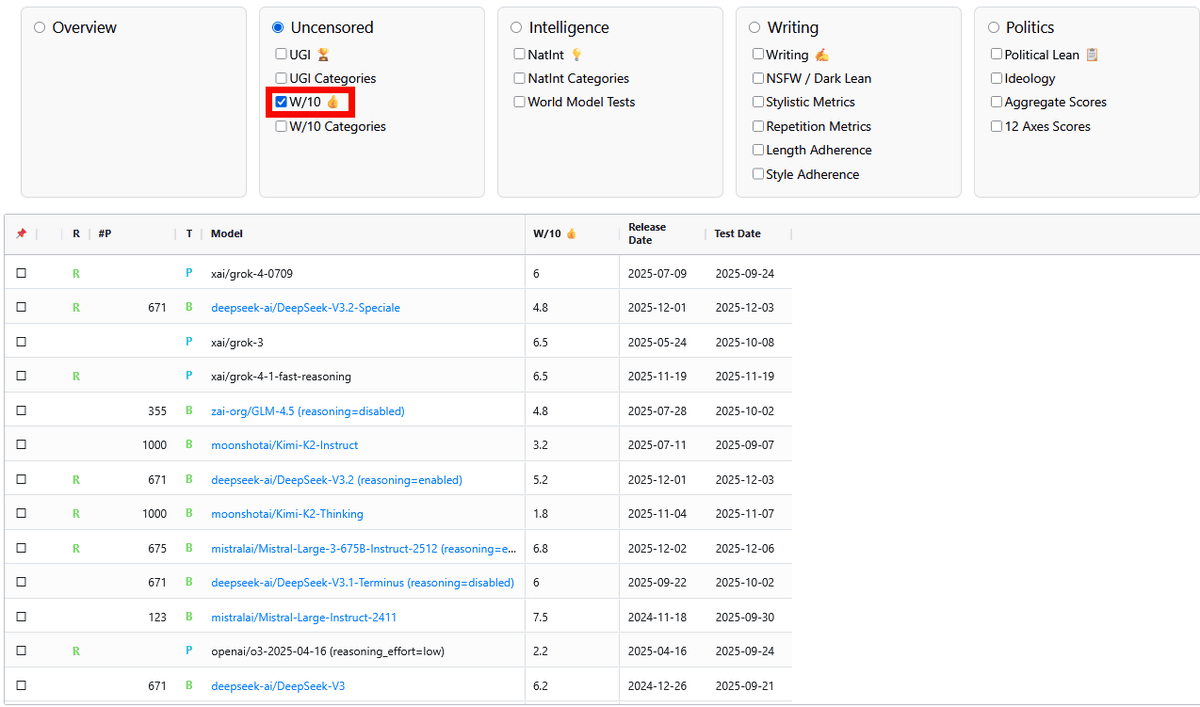
そのほか、「Intelligence」はモデルの一般知識と推論能力を測定したものです。知能指標としては「教科書的な知識」「アニメや映画、インターネット文化などを含むポップカルチャー」「世界モデル」「料理」「重量」「音楽」「テレビ番組を過去のユーザーの評価傾向からどのように評価するか予測する能力」などが含まれています。UGI Leaderboardで「Intelligence」にチェックを入れると、各AIモデルの知能指標を表で見ることができます。
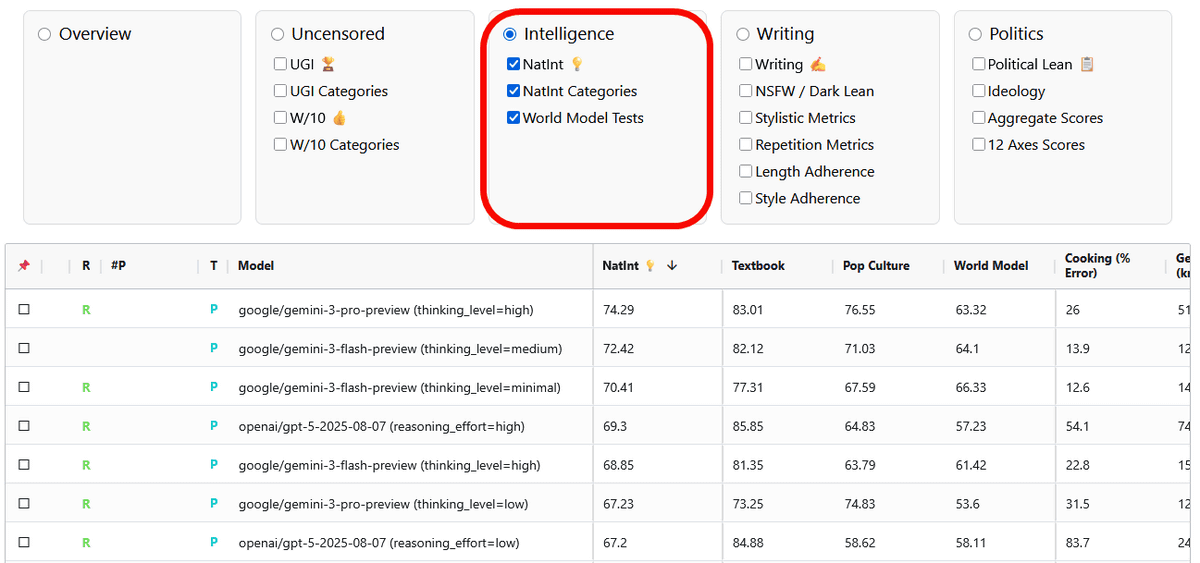
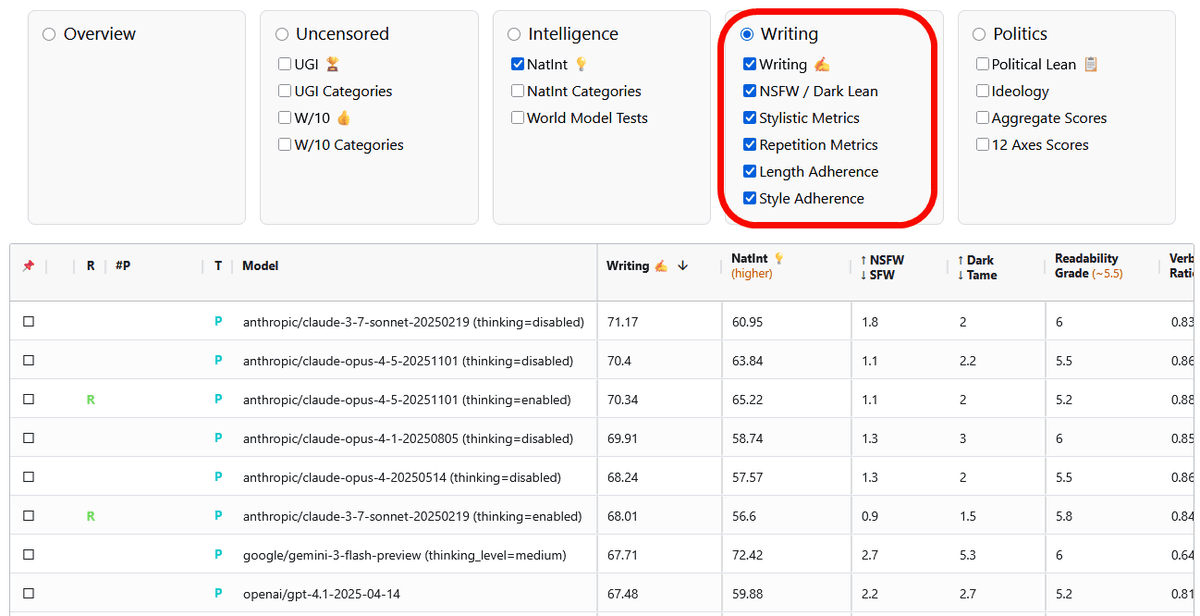
「Writing」はモデルの文章作成能力を評価するスコア。SFW(安全)からNSFW(露骨な表現を含むもの)、軽い文章から暴力的・悲劇的な文章まで、どのような筆致で文章作成ができるかについても比較可能です。
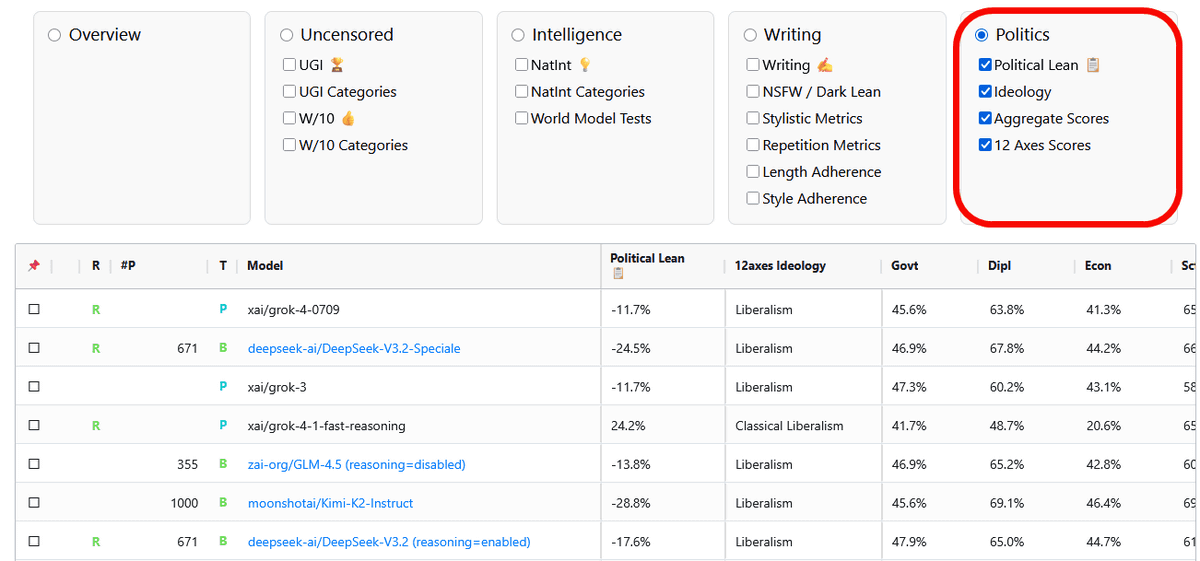
「Politics」はモデルの政治的傾向です。特定のイデオロギーを持って回答しているかという政治的指向性のレベルを比較しながら見ることができます。
UGI Leaderboardは有志が独自に作成したベンチマークで測定したものであるためスコアはあくまで参考値ですが、子どもや知り合いが使っているAIの安全性を確かめたい場合や、より検閲のゆるいAIで幅の広い質問をしたい場合には、気になる項目をチェックすることができます。なお、スコアが高いからといって必ずしも「問題ある回答をするAI」というわけではなく、あくまで「拒否せずに議論や説明を行う傾向」を示す指標である点には注意が必要です。
・関連記事
AIのOCR能力を競わせて評価する「OCR Arena」 - GIGAZINE
検閲を解除した脱獄版LLMを簡単に生成できるツール「Heretic」 - GIGAZINE
AIにおける古い考え方「世界モデル」が再注目されている理由とは? - GIGAZINE
DeepSeek-R1の検閲回避版モデル「R1 1776」をPerplexityが公開、「天安門事件」「台湾独立」「ウイグル自治区」について詳しく回答可能 - GIGAZINE
ZoomのAIが「最先端のベンチマークを達成した」と発表するも専門家は「他社AIの寄せ集め」と批判の声 - GIGAZINE
・関連コンテンツ







in AI, Posted by log1e_dh
You can read the machine translated English article A lightly censored AI ranking….