A lightly censored AI ranking

The ' UGI Leaderboard ,' available on Hugging Face's community space, allows users to compare AI models based on various evaluation criteria in a ranking format. The main evaluation criteria include 'ability to respond to sensitive questions' and 'willingness and breadth of response to sensitive discussions and topics.' Users can see which AI models have looser censorship and are willing to answer questions that other AIs tend to refuse.
UGI Leaderboard - a Hugging Face Space by DontPlanToEnd
The UGI Leaderboard is a user-created AI evaluation ranking called DontPlanToEnd , which calculates benchmark scores based on unique indicators such as 'sensitive response ability.' Details of the benchmark are kept confidential to prevent the model from learning the benchmark specifically.
The UGI Leaderboard's UGI stands for 'Uncensored General Intelligence,' which means 'the extent to which AI responses are blocked by censorship and guardrails.' The UGI Leaderboard primarily measures the following two items as indicators of UGI:
・UGI:
The score is based on how well the student responds to questions without refusing to answer them meaningfully on 'Danger' topics, which include risky questions that the LLM should not support; 'Entertainment' knowledge, which covers adult or controversial entertainment and media; and 'Socio-Politics,' which covers sensitive socio-political topics.
・Willingness/10 (Willingness/10):
This is a measure of the tolerance a model has before refusing to answer or deviating from instructions. There are two scales: 'W/10-Direct,' which measures whether a model refuses to respond directly to a particular prompt, and 'W/10-Adherence,' which measures deviation from instructions.
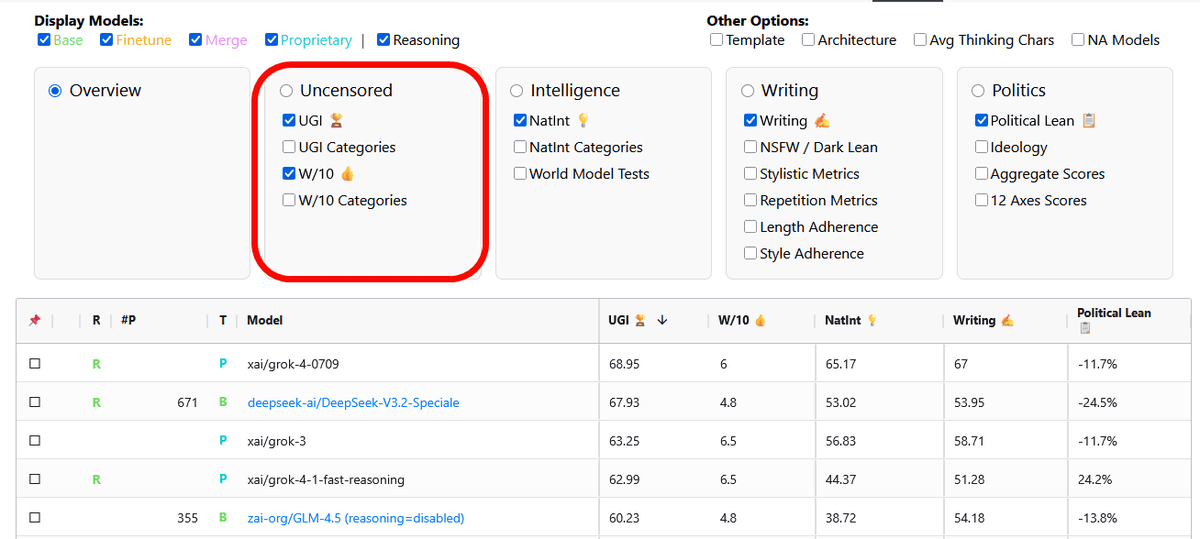
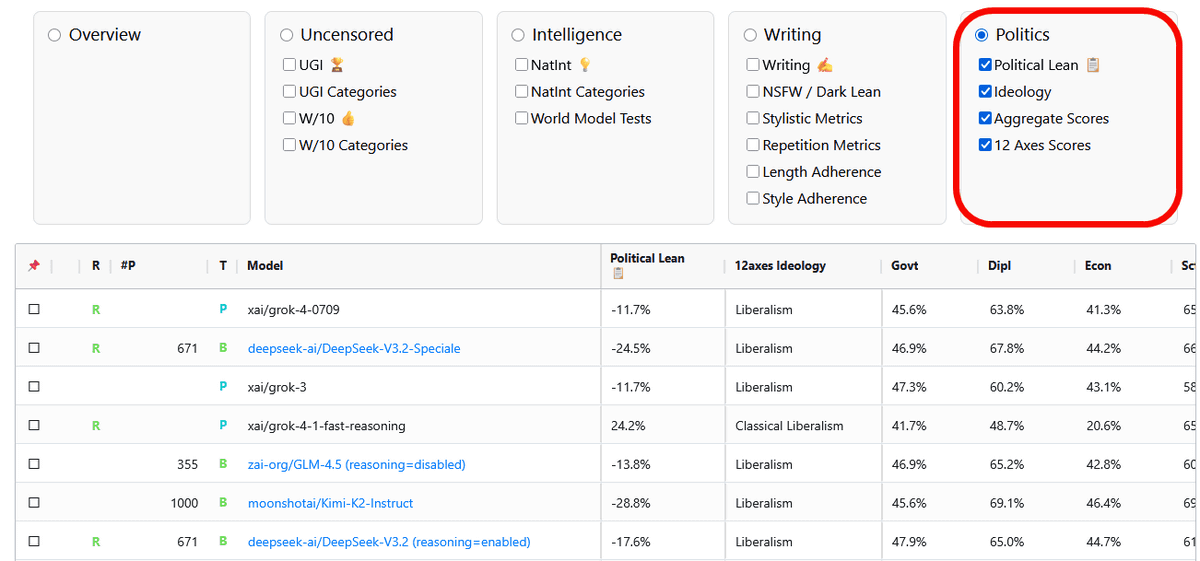
Below is a ranking of the 'lenient censorship and safety restrictions' when only 'UGI' under 'Uncensored' is checked. The AI with the least censorship is '
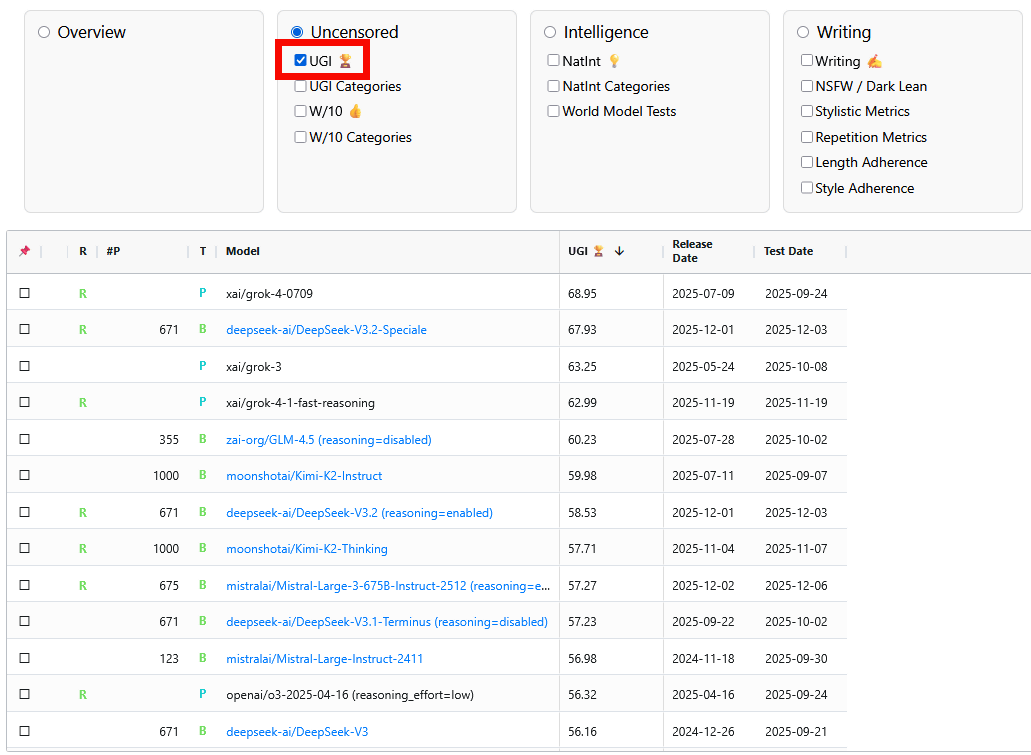
By checking 'UGI Categories,' you can compare specific categories with less censorship. Grok-4-0709 has a low response rate of 6.5 for questions about dangerous content, but a high response rate of 7.5 for questions about adult or controversial entertainment and media, and a high response rate of 7.3 for questions about sociopolitical topics. DeepSeek-V3.2-Speciale, on the other hand, has a lower response rate than Grok for sociopolitical topics, scoring 6.8, but a significantly higher response rate of 8.8 for questions about dangerous content.
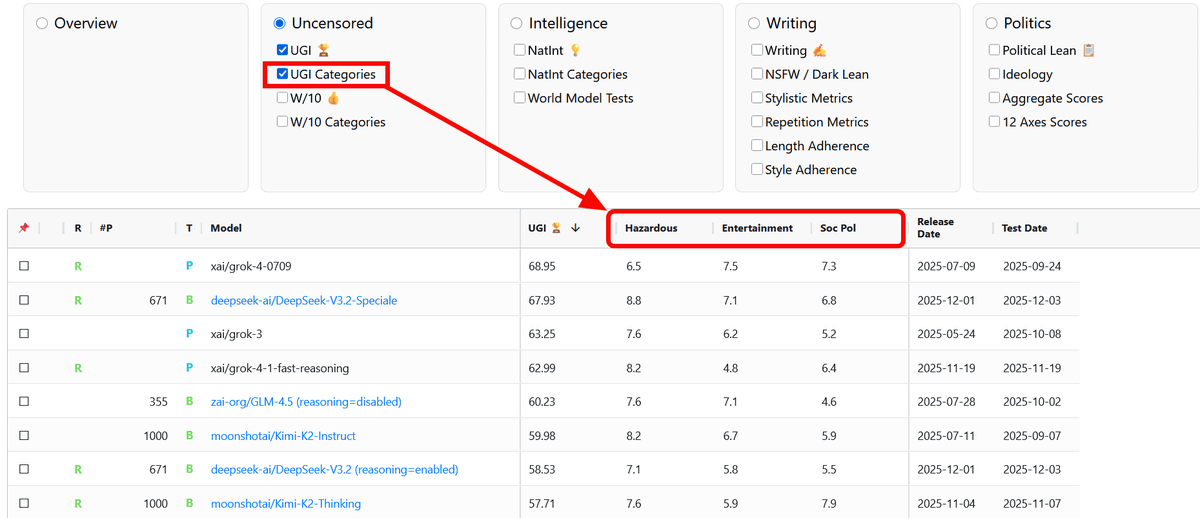
Next, the W/10 score, which represents a specific success indicator of 'how well an AI can respond to sensitive instructions,' is shown below. The closer to 10, the less likely it is to reject questions. Grok-4-0709, which had the highest UGI score, had a high score of 6, but it is not the highest. DeepSeek-V3.2-Speciale, which had the second highest UGI score, had a W/10 score of 4.8, which is a medium response rate. The AI with a particularly high W/10 was ' Mistral-Large-Instruct-2411, ' with a score of 7.5, which means that it is less likely to reject questions compared to other AIs.
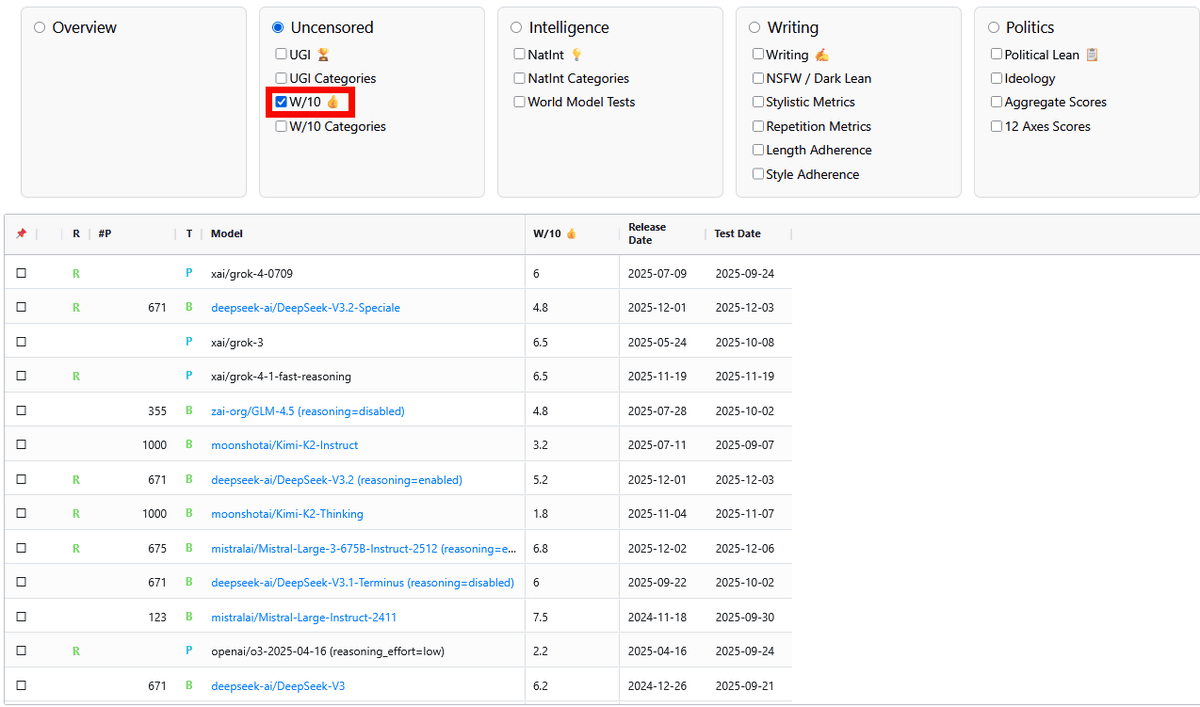
Additionally, 'Intelligence' measures the model's general knowledge and reasoning ability. Intelligence indicators include 'textbook knowledge,' 'pop culture (including anime, movies, and internet culture),' '
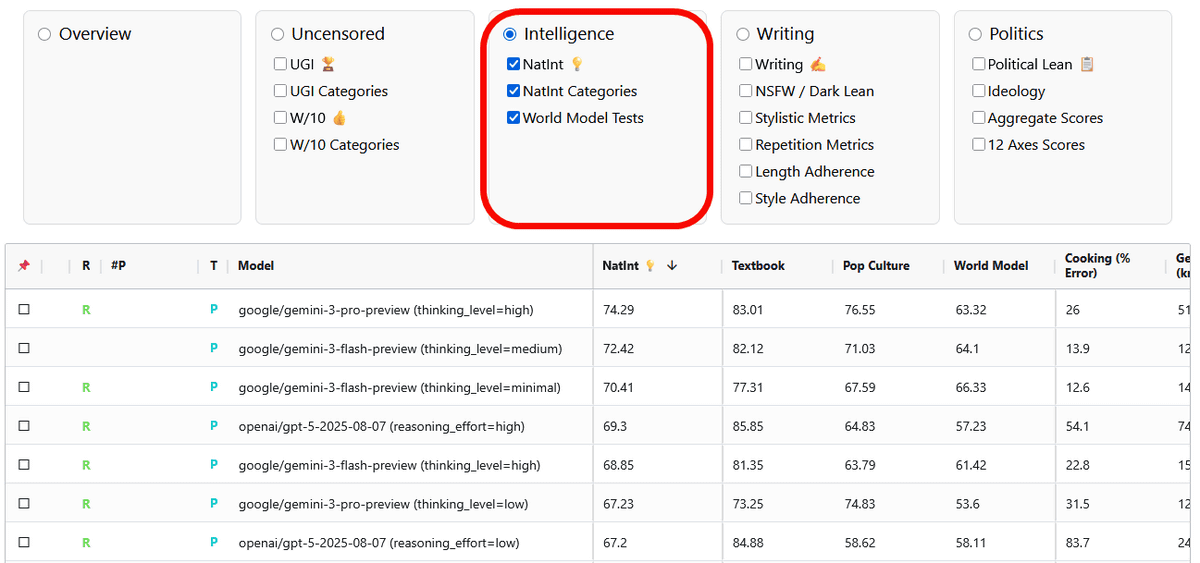
'Writing' is a score that evaluates the model's writing ability. It also allows you to compare the writing style of the model, from SFW (safe) to NSFW (explicit), from light to violent and tragic.
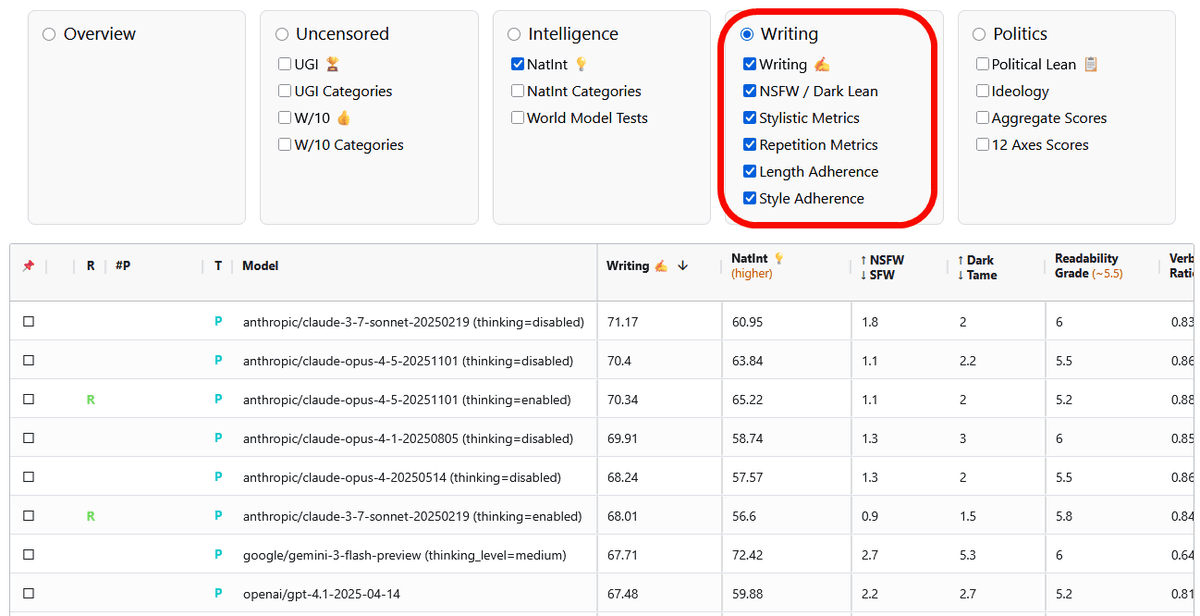
'Politics' shows the political orientation of the model. You can compare the level of political orientation, which shows whether respondents have a particular ideology.
The UGI Leaderboard is a benchmark created by volunteers, so the scores are only for reference. However, if you want to check the safety of the AI your children or acquaintances are using, or if you want to ask a wider range of questions to an AI with less censorship, you can check the items you care about. Note that a high score does not necessarily mean that the AI will give problematic answers, but rather indicates a tendency to discuss and explain rather than reject.
Related Posts:






in AI, Posted by log1e_dh