




AIに対するジェイルブレイク攻撃を95%回避できる技術をAnthropicが開発

チャットAIなどに用いられるAIモデルのほとんどは「生物兵器の作り方」といった危険な情報を出力しないようにトレーニングされていますが、プロンプトを工夫したり一度に大量の質問を入力したりといった「ジェイルブレイク」と呼ばれる手法を用いることでAIモデルに「出力を禁じられている情報」を出力させることができます。新たに、チャットAI「Claude」の開発で知られるAI開発企業のAnthropicがAIのジェイルブレイク耐性を大幅に高める技術「Constitutional Classifiers(憲法分類子)」を発表しました。
Constitutional Classifiers: Defending against universal jailbreaks \ Anthropic
https://www.anthropic.com/research/constitutional-classifiers
Constitutional Classifiersの開発時には、最初に「何が無害で何が有害か」を定義する「Constitution(憲法)」を作成し、Constitutionを大規模言語モデルに入力することで多様なジェイルブレイク手法や言語に対応できる分類子を編み出しました。このとき、大規模言語モデルにはClaudeを活用したそうです。
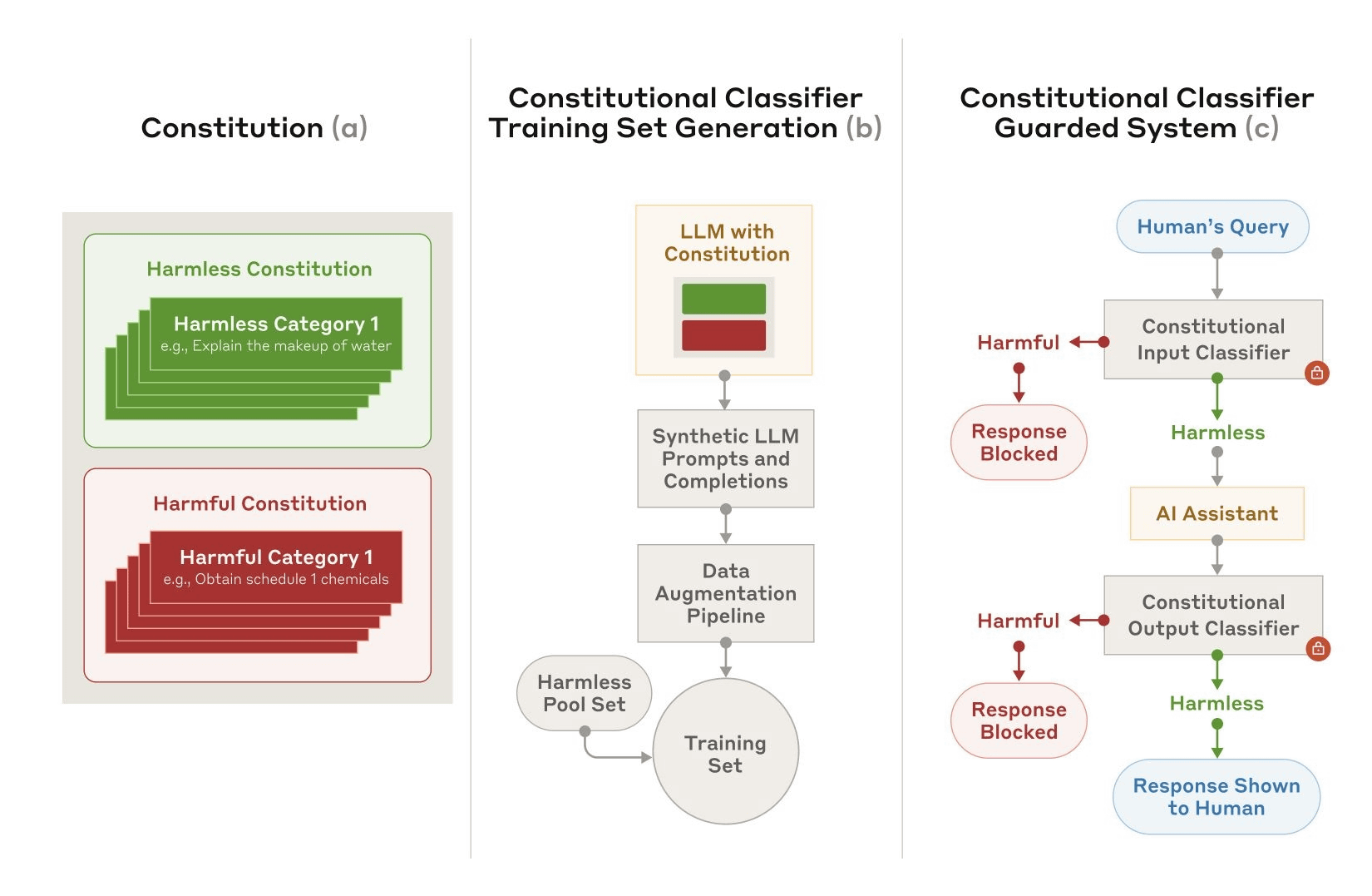
AnthropicはConstitutional Classifiersの効果を検証するべく「人間による実践的なテスト」と「システムを用いた自動テスト」を実施しました。人間によるテストではClaude 3.5 SonnetにConstitutional Classifiersを適用し、バグバウンティプログラムを介して集まった参加者に対して「Claude 3.5 Sonnetの『10種類の禁止された出力』をすべて出力させられる普遍的なジェイルブレイク手法を確立する」というタスクを与えました。普遍的なジェイルブレイク手法を発見した参加者には最大1万5000ドル(約230万円)の報奨金が約束されていましたが、2カ月間の実験期間を通して普遍的なジェイルブレイク手法が見つかることはありませんでした。
さらに、システムを用いた自動テストでは1万個のジェイルブレイクプロンプトを作成し、「Constitutional Classifiersを適用していないClaude 3.5 Sonnet(青)」と「Constitutional Classifiersを適用したClaude 3.5 Sonnet(水色)」に対して攻撃を実行して成功率を比べました。テストの結果、Constitutional Classifiersを適用していない場合の攻撃成功率が86%だったのに対して、適用した場合の攻撃成功率は4.4%にまで減少しました。つまり、Constitutional Classifiersを適用したClaude 3.5 Sonnetはジェイルブレイクの95%以上を回避できたというわけです。
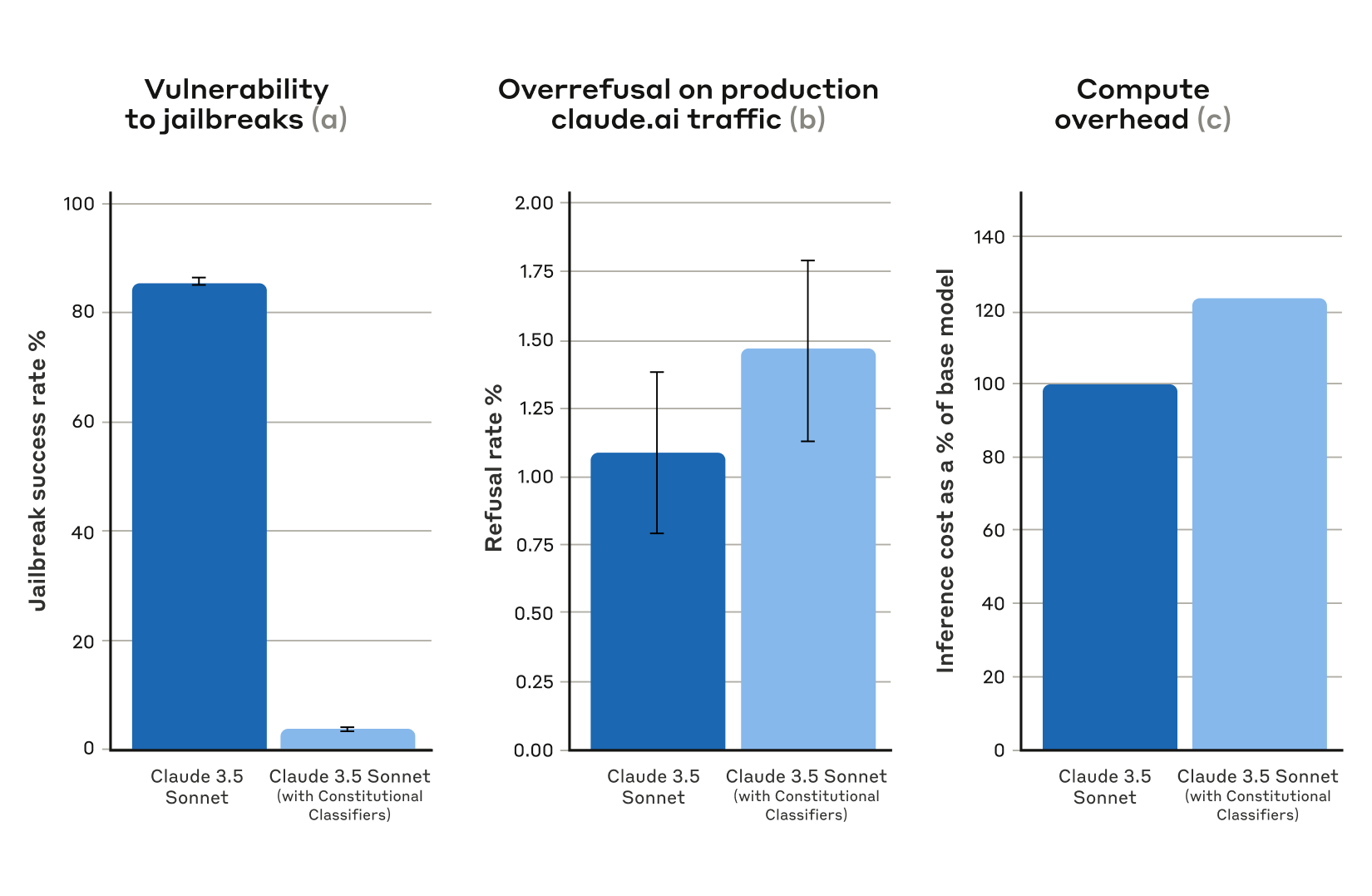
Constitutional Classifiersを適用した場合、「ジェイルブレイクではないのに、誤ってジェイルブレイクと判断して回答を拒否するケース」の発生率が0.38%上昇したとのこと。ただし、この差は有意なものではないそうです。また、Constitutional Classifiersを適用した場合は計算コストが23.7%上昇しました。Anthropicは今後もConstitutional Classifiersを改良して計算コストの削減などに取り組むそうです。
なお、Constitutional Classifiersに関する技術的な詳細は以下のリンク先で確認できます。
[2501.18837] Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
https://arxiv.org/abs/2501.18837

・関連記事
「AIモデルは推論時間が長くなるほど敵対的攻撃に強くなる」というOpenAIの研究結果 - GIGAZINE
大量の質問をぶつけて最後の最後に問題のある質問をするとAIの倫理観が壊れるという脆弱性を突いた攻撃手法「メニーショット・ジェイルブレイキング」が発見される - GIGAZINE
AIの思考を少しずつずらしてAIに催眠をかけるように「ジェイルブレイク」した具体例 - GIGAZINE
AIチャットボットが生成できない回答を「アスキーアート」で答えさせることができるという報告 - GIGAZINE
なぜ大規模言語モデル(LLM)はだまされやすいのか? - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by log1o_hf
You can read the machine translated English article Anthropic develops technology that can c….