Anthropic develops technology that can circumvent 95% of jailbreak attacks on AI

Most AI models used in chat AI etc. are trained not to output dangerous information such as 'how to make biological weapons', but by using a technique called 'jailbreak' such as
Constitutional Classifiers: Defending against universal jailbreaks \ Anthropic
https://www.anthropic.com/research/constitutional-classifiers
When developing the Constitutional Classifiers, we first created a 'Constitution' that defines 'what is harmless and what is harmful', and then input the Constitution into a large-scale language model to create a classifier that can handle a variety of jailbreaking methods and languages. At this time, Claude was used for the large-scale language model.
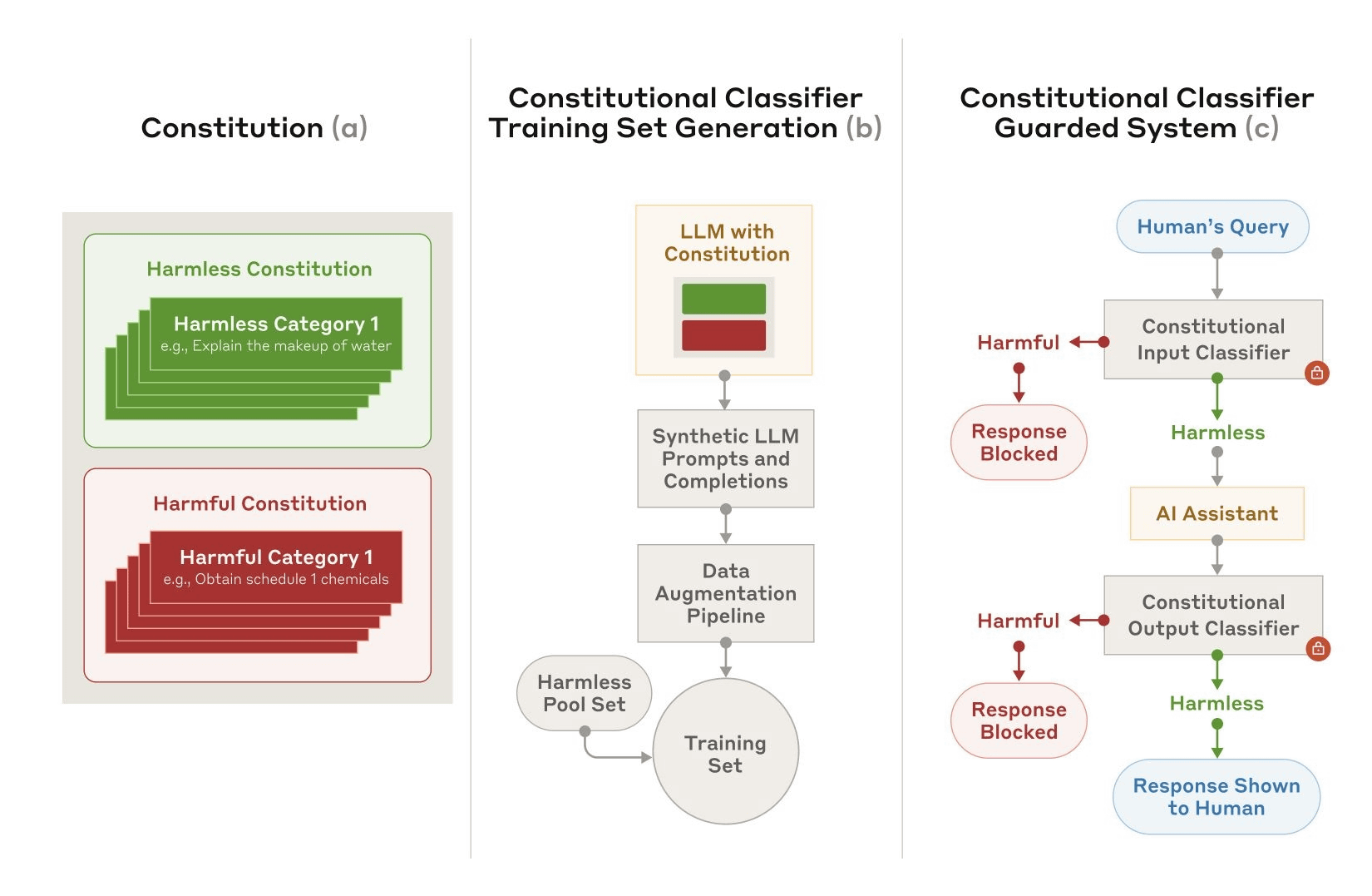
To verify the effectiveness of Constitutional Classifiers, Anthropic conducted 'human practical testing' and 'automated testing using the system'. In the human testing, the Constitutional Classifiers were applied to Claude 3.5 Sonnet, and participants gathered through
In addition, in an automated test using the system, 10,000 jailbreak prompts were created, and attacks were performed against 'Claude 3.5 Sonnet (blue) without Constitutional Classifiers applied' and 'Claude 3.5 Sonnet (light blue) with Constitutional Classifiers applied' to compare the success rate. As a result of the test, the attack success rate when Constitutional Classifiers were not applied was 86%, while the attack success rate when Constitutional Classifiers were applied decreased to 4.4%. In other words, Claude 3.5 Sonnet with Constitutional Classifiers applied was able to avoid more than 95% of jailbreaks.
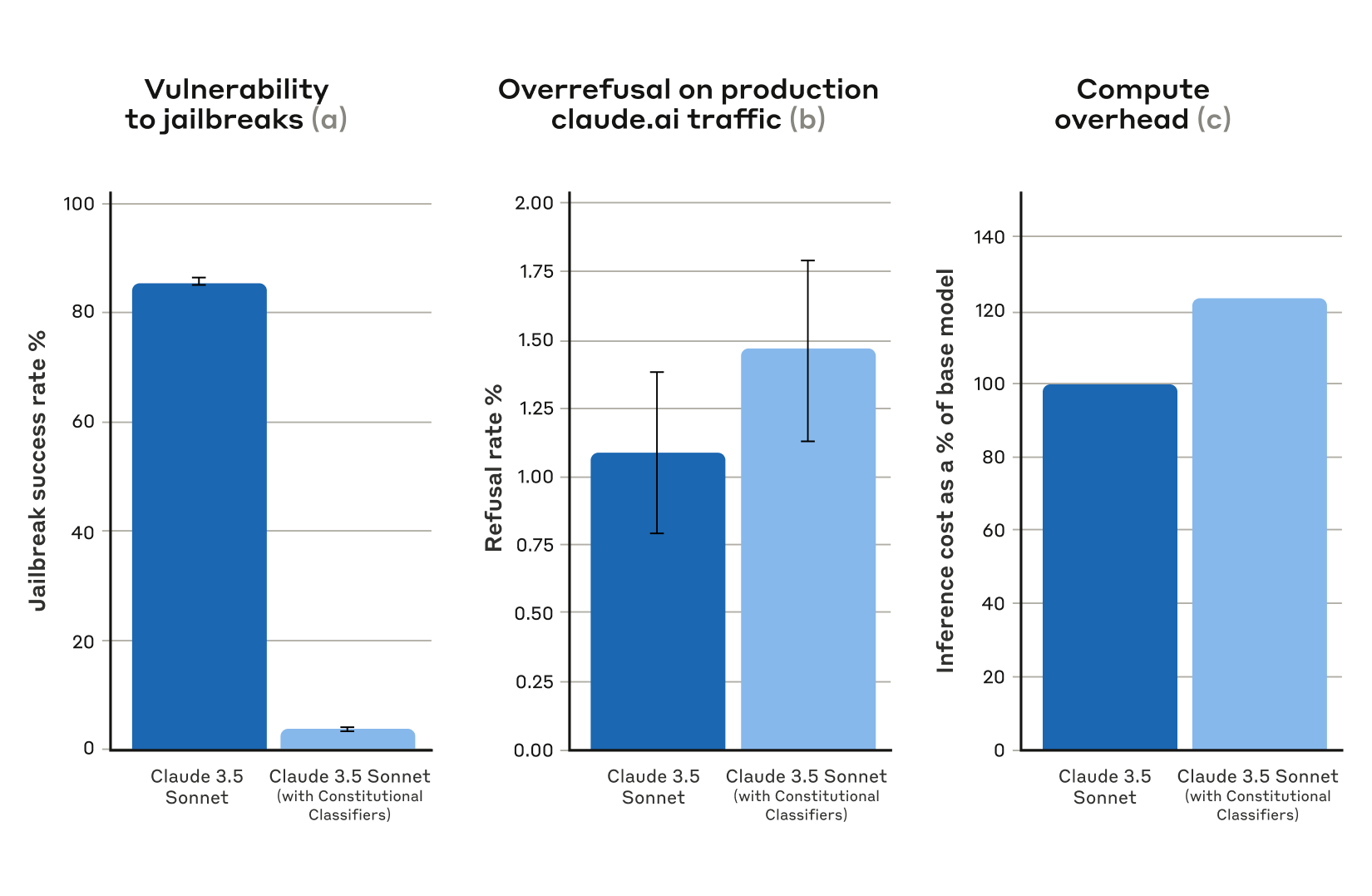
When the Constitutional Classifiers were applied, the incidence of cases where the answer was rejected because it was mistakenly determined to be jailbroken, even though it was not jailbroken, increased by 0.38%. However, this difference does not seem to be significant. In addition, when the Constitutional Classifiers were applied, the computational cost increased by 23.7%. Anthropic plans to continue improving the Constitutional Classifiers and working on reducing computational costs.
For more technical details about Constitutional Classifiers, please see the following links:
[2501.18837] Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
https://arxiv.org/abs/2501.18837

Related Posts:







in Software, Posted by log1o_hf