




「AIモデルは推論時間が長くなるほど敵対的攻撃に強くなる」というOpenAIの研究結果

AIを意図的に混乱させようとする敵対的攻撃に対する防衛策として、推論時間が長ければ長いほど効果的とする研究結果をOpenAIが発表しました。
Trading inference-time compute for adversarial robustness | OpenAI
https://openai.com/index/trading-inference-time-compute-for-adversarial-robustness/
AIモデルが敵対的攻撃に対して脆弱(ぜいじゃく)だと、モデルが開発者の意図しない方法で利用されることになりかねないため、開発者らは敵対的攻撃に対する防衛策を長年にわたり研究しています。
OpenAIが発表した新たな研究では、AIモデルの推論時間が長くなるにつれて、つまりAIが「考えること」に時間とリソースを費やせば費やすほど、さまざまな攻撃に対して強固になる可能性が示されました。
OpenAIは自社AIモデルのo1-previewとo1-miniを用い、数学の問題を意図的に誤答させる攻撃や、画像を用いて悪意のある回答を引き出す攻撃、大量の情報を一度に伝えることでAIを混乱させる「メニーショット・ジェイルブレイキング」などをAIモデルに仕掛け、各モデルの推論時間の違いが回答にどう影響するのかを調べました。
大量の質問をぶつけて最後の最後に問題のある質問をするとAIの倫理観が壊れるという脆弱性を突いた攻撃手法「メニーショット・ジェイルブレイキング」が発見される - GIGAZINE

その結果、ほとんどの攻撃手法において、推論時間が増加するにつれて攻撃の成功確率が低下することが判明しました。以下は「メニーショット・ジェイルブレイキング」においてY軸を攻撃者のリソース量、X軸を推論時間としたヒートマップで、色の濃さは攻撃の成功確率を表し、0(緑)から1(黄色)の範囲で示されています。攻撃者のリソース量が増えたとしても、推論時間が多ければ攻撃は失敗しやすいということがわかります。
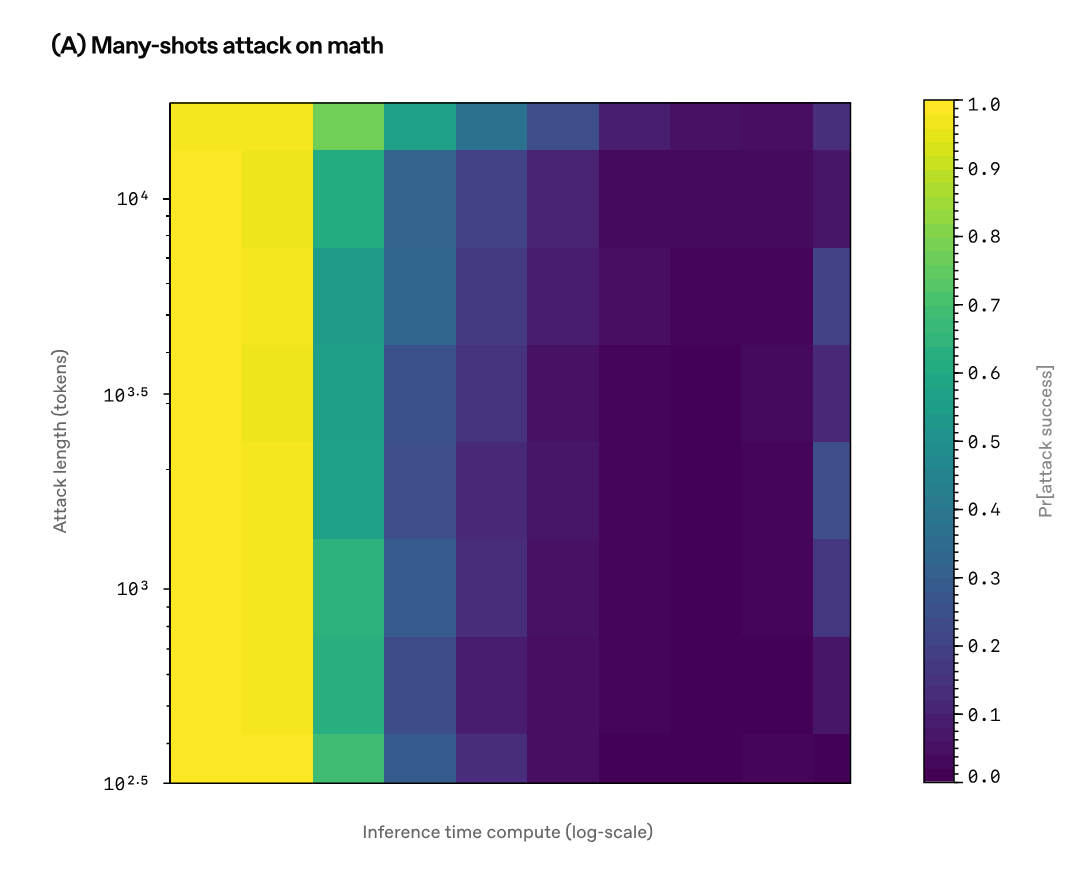
この研究においてAIモデルは自分がどのような攻撃を受けているのかを伝えられていなかったため、OpenAIは「推論時間の調整だけで頑健性が向上していることを示しています」と強調しました。
ただし、ベンチマークのために作られた、有害な情報を回答するよう命じるプロンプトを用いた攻撃では、推論時間が増えても攻撃の成功確率が下がらないことがあったそうです。加えて、攻撃者がAIモデルに何も考えさせなかったり、推論時間を非生産的なことに使わせたりすることで、モデルを欺く可能性があることも示されています。
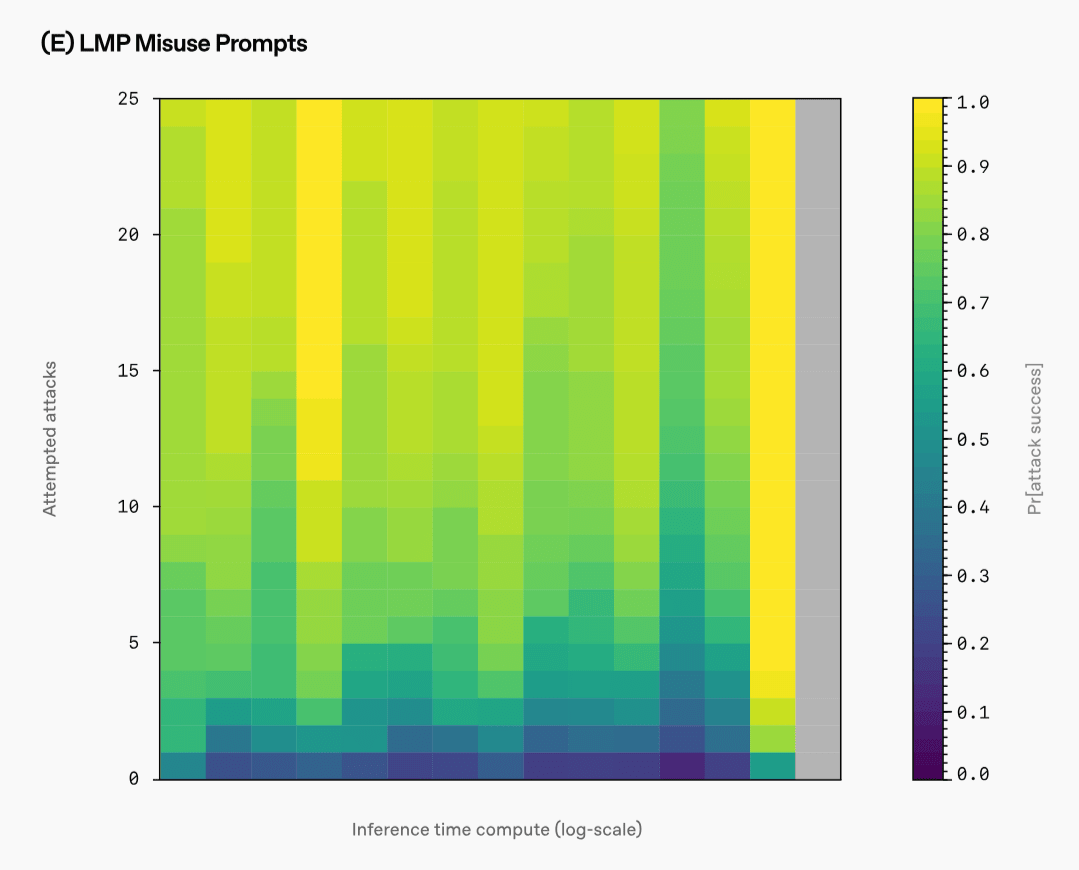
OpenAIは「敵対的攻撃に対する防衛策は、昨今のAIモデルが重要なアプリケーションに使用されたり、ユーザーの代わりに行動を起こすエージェントとして機能するようになったりするにつれて、緊急性を増しています。長年にわたる熱心な研究にもかかわらず、敵対的攻撃に対する問題は解決には程遠いと言えますが、今回の研究は推論時間の威力を示す有望な兆候であると考えています」と述べました。
・関連記事
OpenAIが新モデル「o1-preview」の思考内容を出力させようとしたユーザーに警告 - GIGAZINE
AIの思考を少しずつずらしてAIに催眠をかけるように「ジェイルブレイク」した具体例 - GIGAZINE
なぜ大規模言語モデル(LLM)はだまされやすいのか? - GIGAZINE
ランダムな文字列で質問し続けるとAIから有害な回答を引き出せるという攻撃手法「Best-of-N Jailbreaking」が開発される、GPT-4oを89%の確率で突破可能 - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by log1p_kr
You can read the machine translated English article OpenAI research results: 'The longer….