OpenAI research results: 'The longer an AI model takes to infer, the more resistant it becomes to adversarial attacks'

OpenAI has announced research results showing that the longer the inference time, the more effective the defense against adversarial attacks that intentionally confuse AI.
Trading inference-time compute for adversarial robustness | OpenAI
AI developers have been researching defenses against adversarial attacks for years because if an AI model is vulnerable to them, it could be used in ways the developer did not intend.
New research published by OpenAI suggests that the longer an AI model's inference time -- that is, the more time and resources it spends 'thinking' -- the more robust it may be against a variety of attacks.
OpenAI used its own AI models o1-preview and o1-mini to launch attacks such as intentionally giving incorrect answers to mathematical problems, attacks using images to extract malicious answers, and 'many-shot jailbreaking' to confuse the AI by conveying a large amount of information at once. We investigated how the difference in inference time of each model affects the answer.
'Many-shot jailbreaking' is an attack method that exploits the vulnerability of AI's ethics by bombarding it with a large number of questions and asking a problematic question at the very end - GIGAZINE

As a result, it was found that for most attack methods, the probability of success of the attack decreases as the inference time increases. Below is a heat map for 'Many-Shot Jailbreaking' with the Y axis representing the attacker's resource amount and the X axis representing the inference time, and the color intensity represents the probability of attack success, ranging from 0 (green) to 1 (yellow). We can see that even if the attacker's resource amount increases, the attack is more likely to fail if the inference time is long.
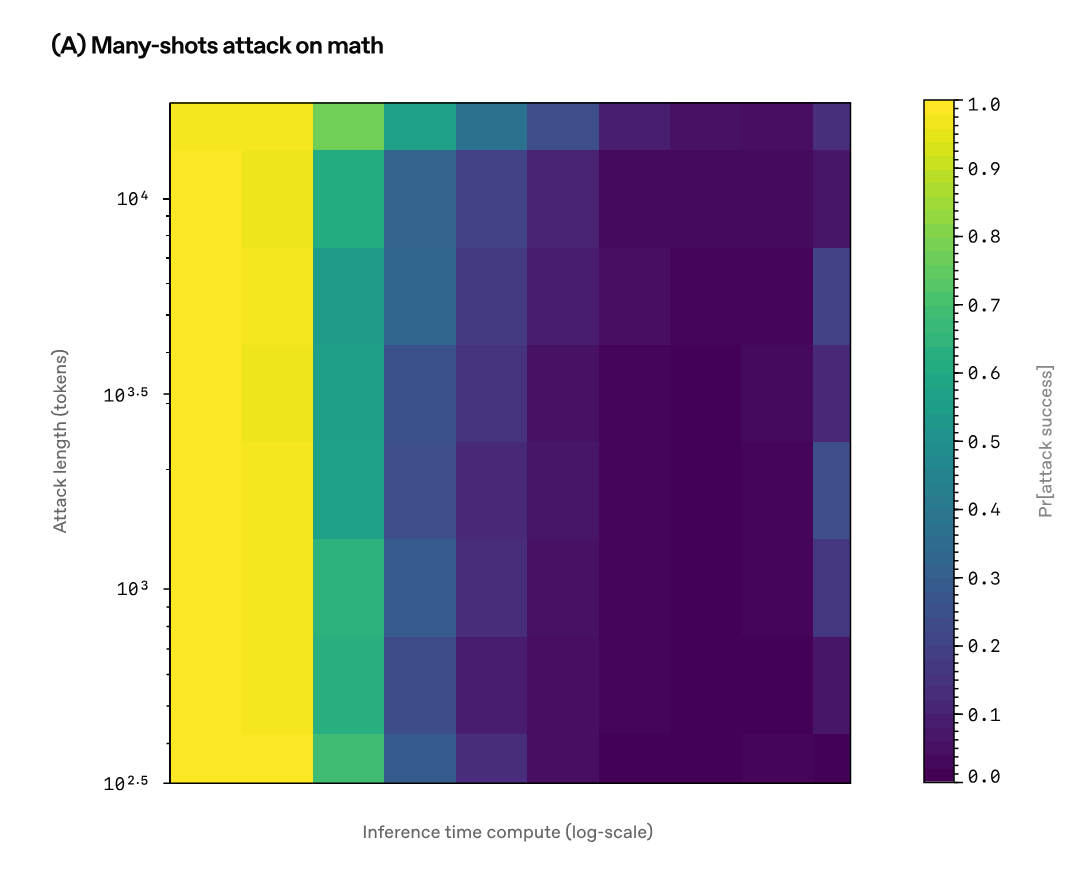
In this study, the AI model was not informed of the type of attack it was under, so OpenAI emphasized that 'we show that robustness is improved simply by adjusting the inference time.'
However, in an attack using a prompt created for the benchmark that asks users to answer harmful information, the success rate of the attack did not decrease even if the inference time increased. In addition, it has been shown that an attacker can deceive an AI model by making it think nothing or using its inference time for unproductive purposes.
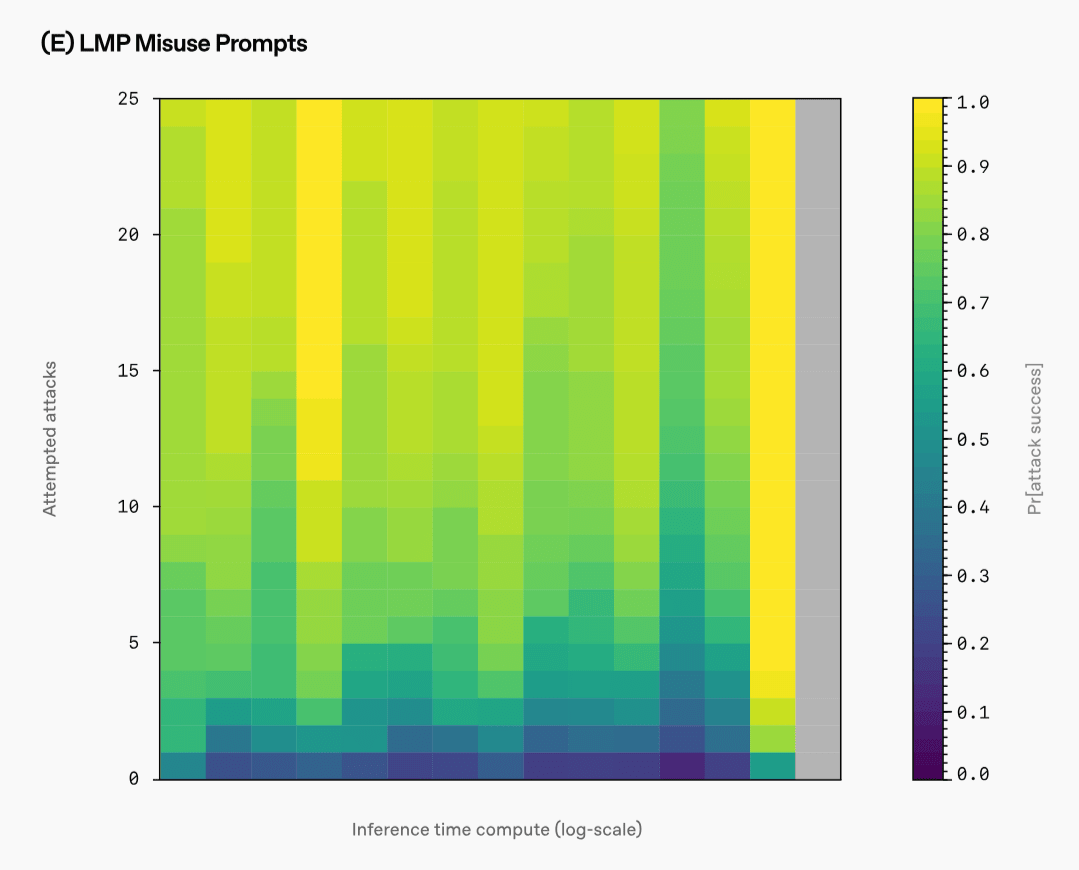
'Defending against adversarial attacks is becoming increasingly urgent as modern AI models are used in critical applications and act as agents to take action on behalf of users. Despite years of dedicated research, the problem of adversarial attacks is far from solved, but we believe this work is a promising sign of the power of inference time,' OpenAI said.
Related Posts:






