Googleの検索アルゴリズムに関する内部文書が流出、Chromeのデータをページランク付けに利用するなどGoogleのウソが明らかに

Googleの社員がデータやAPI、モジュールの扱いに習熟するのに用いられているという、合計2500ページ超の内部文書「Google API Content Warehouse」が流出しました。これにより、Googleが検索ユーザーの情報やChromeのデータなどをどのようにして利用していたのかといった実態が明らかになりました。内容を精査したSEO(検索エンジン最適化)業界の関係者は、含まれている情報はほとんどが2024年3月時点のかなり新しいものであるとしています。
An Anonymous Source Shared Thousands of Leaked Google Search API Documents with Me; Everyone in SEO Should See Them - SparkToro
https://sparktoro.com/blog/an-anonymous-source-shared-thousands-of-leaked-google-search-api-documents-with-me-everyone-in-seo-should-see-them/
Secrets from the Algorithm: Google Search’s Internal Engineering Documentation Has Leaked
https://ipullrank.com/google-algo-leak
HUGE Google Search document leak reveals inner workings of ranking algorithm
https://searchengineland.com/google-search-document-leak-ranking-442617
今回流出した内部文書は、ウェブサイト解析ツールを開発・提供しているSparkToroのランド・フィッシュキン氏が、「匿名の関係者」と共有して公開したもの。内容はフィッシュキン氏や、SEO対策を行うiPullRankの創業者でCEOのマイク・キング氏らにより精査され、一部に古い情報が含まれるものの、ほとんどは2024年3月時点の最新情報であると確認されました。
フィッシュキン氏と情報を共有した「匿名関係者」は、マーケティング代理店でSEOに強いEA Eagle Digitalのエアファン・アーズィーミCEOであることが、自身の口から明かされています。
Erfan Azimi: Leaked Google Ranking Factors (Public Statement) - Rand Fishkin, Mike King - YouTube

この内部文書は、2024年3月13日にGitHubで「yoshi-code-bot」というボットにより公開リポジトリに投稿されたもの。誤動作によるもので、「意図的な情報漏洩(リーク)が起きた」というよりは「偶然公開されていた情報が発見された」のではないかという指摘があります。
検索エンジンが、検索結果をどういった順で表示しているのかというアルゴリズムがどのように機能しているのかはSEOにとっては非常に重要です。2023年にロシア最大の検索エンジン「Yandex」のソースコードが流出した際は、Yandexの検索結果にGoogleと類似する点が多々あることから、GoogleのSEOとしても参考になる情報だと話題になりました。
ロシア最大の検索エンジン「Yandex」のソースコード流出で検索ランキングの決定要因が明らかに - GIGAZINE
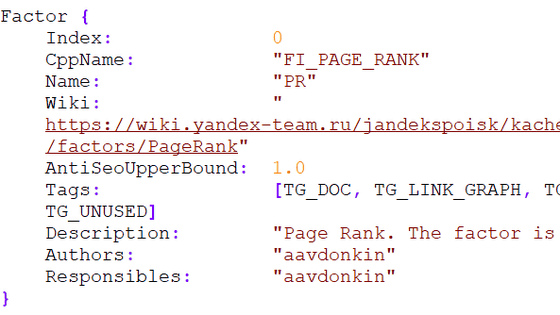
膨大な文書の一部をまとめると、以下のようになっているとのこと。
・文書には2596個のモジュール、1万4014個の属性についての記述がある
・検索結果表示に用いるランク付けで考慮される要素について記述があるが、どの要素がどのように重み付けされているかという具体的な記述はなし
・コンテンツは「リンク先がターゲットと一致しない」「SERP(検索結果表示)にユーザーが不満を示している」「製品レビュー」「ロケーション」「完全一致ドメイン」「ポルノ」のなどの要素でページランクを下げられる
・Googleは過去にインデックスしたページのすべての変更点を記録しているが、リンク分析時は直近20回の変更履歴しか参照しない
・「ページランク」はGoogleのランク付けの中でまだ重要な位置を占めている
・Googleは「badClicks」「goodClicks」「lastLongestClicks」「unsquashedClicks」などさまざまな測定値でクリックを測定しており、成果につながったクリックが重要
・長いコンテンツは切り捨てられることがあるが短いコンテンツには独創性に基づき0から512のスコアが与えられる
・健康やニュースといった、いわゆる「YMYL(Your Money Your Life)」コンテンツにもスコアが与えられる
・検索ランキングの上位にいくためにはブランドが何よりも重要
・Googleはコンテンツの作者に関する情報を保存しており、特定の文書の著者かどうかを判断しようとしている
・2011年のパンダアップデート後に存在を示唆しつつその後否定していた「siteAuthority」を利用している
・検索ランキングにChromeのデータを利用する「ChromeInTotal」というモジュールが存在する
・選挙と新型コロナウイルス感染症(COVID)に関する特定のドメインをホワイトリストに登録していることを示す「isElectionAuthority」「isCovidLocalAuthority」モジュールが存在する
・小規模なサイトやブログのための「smallPersonalSite」モジュールが存在するがランキングの重み付けの中でどれぐらいの位置づけにあるかは不明
・「titlematchScore」という機能でページタイトルと内容のクエリがどれぐらい一致しているか測定していると考えられる
Googleはこれまで「ページのランク付けにChromeのデータは利用していない」と説明してきましたが、実際は上述のようにChromeのデータを利用するモジュールが存在していたことから、キング氏は「『ウソをついた』というのは厳しい表現だが、この場合に使う唯一の正確な言葉だ」と、Googleに厳しい目を向けています。
なお、今回の話題を取り上げたニュースサイトのAndroid Headlinesは「Googleはまだコメントを発表していませんが、情報を削除させるために全力を尽くすはずで、数日中にこの記事が消されても私は驚きません」とコメントしています。
Massive Google Leak: Internal Documents Reveal Hidden Truths About Search Algorithm
https://www.androidheadlines.com/2024/05/massive-google-leak-internal-documents-reveal-hidden-truths-about-search-algorithm.html
・つづき
Google検索のアルゴリズムに関する2500ページ超の内部文書が本物であることをGoogleが認める - GIGAZINE

・関連記事
Google検索のアルゴリズム変更でトラフィックの90%超を失ったウェブサイトが窮状を訴える - GIGAZINE
Google創業者たちの2006年の予言「広告ベースのビジネスモデルが検索エンジンの品質低下をもたらす」 - GIGAZINE
Google創業者は最初から「広告を検索に入れると品質が悪化する」と言っていた - GIGAZINE
・関連コンテンツ