Internal documents about Google's search algorithm leaked, revealing Google's lies, such as using Chrome data for page ranking

A total of over 2,500 pages of internal documents, the ' Google API Content Warehouse ,' used to familiarize Google employees with data, APIs, and modules, have been leaked. This has revealed the actual situation of how Google was using search user information and Chrome data. SEO (search engine optimization) industry insiders who have examined the contents have stated that most of the information contained is quite new as of March 2024.
An Anonymous Source Shared Thousands of Leaked Google Search API Documents with Me; Everyone in SEO Should See Them - SparkToro
Secrets from the Algorithm: Google Search's Internal Engineering Documentation Has Leaked
HUGE Google Search document leak reveals inner workings of ranking algorithm
The leaked internal documents were shared with 'anonymous parties' by Rand Fishkin of SparkToro , a company that develops and provides website analytics tools. The contents were reviewed by Fishkin and Mike King, founder and CEO of iPullRank , an SEO company, and confirmed that although some of the information contained was outdated, most of it was up-to-date as of March 2024.
The 'anonymous person' who shared the information with Fishkin revealed that he is Erfan Azimi, CEO of EA Eagle Digital , a marketing agency that specializes in SEO.
Erfan Azimi: Leaked Google Ranking Factors (Public Statement) - Rand Fishkin, Mike King - YouTube
This internal document was posted to a public repository on GitHub by a bot named 'yoshi-code-bot' on March 13, 2024. It has been pointed out that this was due to a malfunction, and that rather than an 'intentional information leak,' it was 'accidentally discovered to be public.'
How search engines display search results and the order in which their algorithms work is very important for SEO. When the source code of Russia's largest search engine, Yandex, was leaked in 2023, it was said that the information could be used as a reference for Google's SEO because Yandex's search results have many similarities to Google.
Source code leak of Russia's largest search engine 'Yandex' reveals what determines search rankings - GIGAZINE
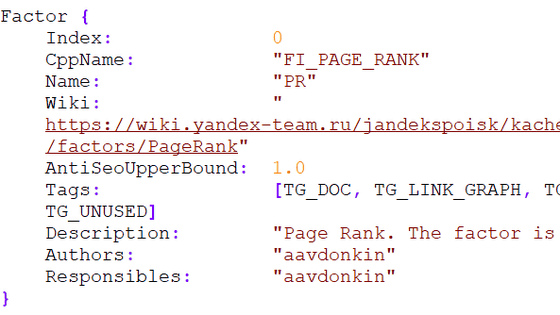
A summary of some of the extensive documents is as follows:
The document describes 2,596 modules and 14,014 attributes.
- There is a description of the factors that are taken into account in ranking the search results, but there is no specific description of how each factor is weighted.
Content can be downgraded for factors such as 'links that don't match the target,' 'users dissatisfied with the SERP (search results display),' 'product reviews,' 'location,' 'exact match domain,' and 'pornography.'
Google keeps track of all changes made to pages it has indexed, but when analyzing links it only looks at the last 20 changes.
'PageRank' still plays an important role in Google rankings
Google measures clicks using various metrics such as 'badClicks,' 'goodClicks,' 'lastLongestClicks,' and 'unsquashedClicks,' and the most important thing is the clicks that lead to results.
Longer pieces of content may be truncated, but shorter pieces of content are given a score from 0 to 512 based on originality.
- So-called 'YMYL (Your Money Your Life)' content, such as health and news, will also be given a score.
Brand is the most important factor in getting to the top of search rankings
Google stores information about content authors and tries to determine who is the author of a particular document.
- Uses 'siteAuthority,' a feature that was hinted at after the 2011 Panda update but was later denied
- There is a module called 'ChromeInTotal' that uses Chrome data for search rankings.
The presence of 'isElectionAuthority' and 'isCovidLocalAuthority' modules that indicate the whitelisting of specific domains related to elections and COVID-19.
There is a 'smallPersonalSite' module for small sites and blogs, but it is unclear how much weight it has in the rankings.
- The 'titlematchScore' feature is thought to measure how well the page title matches the content query.
Google has previously explained that it does not use Chrome data to rank pages, but in fact, as mentioned above, there is a module that uses Chrome data. King has criticized Google, saying, ''Lying' is a harsh word, but it's the only accurate word to use in this case.'
In addition, the news site Android Headlines, which covered this story, commented, 'Google has not yet commented, but I will likely do everything in its power to have the information removed, and I would not be surprised if this article is deleted within the next few days.'
Massive Google Leak: Internal Documents Reveal Hidden Truths About Search Algorithm
https://www.androidheadlines.com/2024/05/massive-google-leak-internal-documents-reveal-hidden-truths-about-search-algorithm.html
Continued
Google admits that over 2,500 pages of internal documents about its search algorithms are genuine - GIGAZINE

Related Posts:



in Web Service, Posted by logc_nt