




スタンフォード大学の研究グループがGPUを高速に動作させるAI用のドメイン固有言語「ThunderKittens」をリリース

スタンフォード大学のクリストファー・レ教授率いる研究チームがGPUを最大限に活用して一定時間当たりの演算量を最大化するためのドメイン固有言語(DSL)「ThunderKittens」をリリースしました。
ThunderKittens: A Simple Embedded DSL for AI kernels · Hazy Research
https://hazyresearch.stanford.edu/blog/2024-05-12-quick-tk
GPUs Go Brrr · Hazy Research
https://hazyresearch.stanford.edu/blog/2024-05-12-tk
研究チームはNVIDIA H100を使用し、GPU使用率の最大化に取り組みました。H100はTensorコアを使用する半精度行列乗算計算の性能が989TFLOPSであり、その他の計算能力すべての合計である約60TFLOPSを大きく上回っています。つまり、H100のGPU使用率はほとんどTensorコアの使用率に依存しています。
研究チームは全てのGPUサイクルにおいてTensorコアが仕事をできるように「WGMMA命令」「アドレス生成」「共有メモリ」「占有率」という4つの部分を集中的に改善したとのこと。
・WGMMA命令
H100には「warp group matrix multiply accumulate(WGMMA)」と呼ばれる新たな命令セットが追加されています。WGMMA命令を使用すると、ストリーミングマルチプロセッサ(SM)の128個のスレッドが協調的に同期し、共有メモリから直接行列演算を行います。研究チームのマイクロベンチマークによるとWGMMA命令を使用しなければGPU使用率は約63%で頭打ちになってしまうとのこと。
ただしWGMMA命令を使用する際に共有メモリにどのようにデータを配置するべきかという問題は非常に複雑で、NVIDIAのドキュメントが間違っていたこともあって適切にデータを配置できるようになるまで研究チームは非常に苦労したと述べられています。とはいえ、WGMMA命令を使用しなければGPU使用率の37%が失われてしまうためどうしても避けては通れない問題でした。
・アドレス生成
H100はTensorコアとメモリの両方が非常に高速に動作するため、データをフェッチするためのメモリアドレスを生成するだけでもチップのリソースをかなり消費します。NVIDIAが用意しているTensor Memory Accelerator(TMA)という命令を使用することでグローバルメモリや共有メモリで多次元テンソルレイアウトを指定し、そのテンソルの一部を非同期でフェッチすることが可能です。TMAを使用することでアドレス生成コストを大きくカットすることが可能です。
・共有メモリ
共有メモリの単一アクセスのレイテンシーは約30サイクルと比較的小さく、これまでは他の部分がボトルネックだったため見過ごされていたものの、今回のような「最大限の最適化」に取り組む場合にはこうした小さなレイテンシーにも気を配る必要がありました。
研究チームはレジスタと共有メモリ間のデータの移動を可能な限り減らしつつ、データを移動する必要がある場合にはWGMMA命令やTMA命令を使用し、非同期で共有メモリとレジスタ間のデータを移動させました。
・占有率
占有率とはGPUが実行できる最大のWarpの数に比べて実際に実行したWarpの数がどれくらいなのかという数値です。H100ではチップの非同期機能が強化されていてメモリのフェッチや行列乗算の実行、共有メモリの削減の実行、レジスタでの演算の同時実行などハードウェアをビジー状態に保つ方法があるため、それ以前の世代のハードウェアよりも占有率が低くてもパフォーマンスを高めることが可能とのこと。
とはいえ、占有率が高い方がハードウェアの実際のパフォーマンスが向上しやすいことは間違いありません。また、A100やRTX 4090などのハードウェアではH100と比べて同期命令ディスパッチへの依存度が高いため占有率の向上が大切になっています。
上述の要素を改善するために研究チームはCUDA内に埋め込むためのドメイン固有言語(DSL)として「ThunderKittens」を設計・リリースしました。
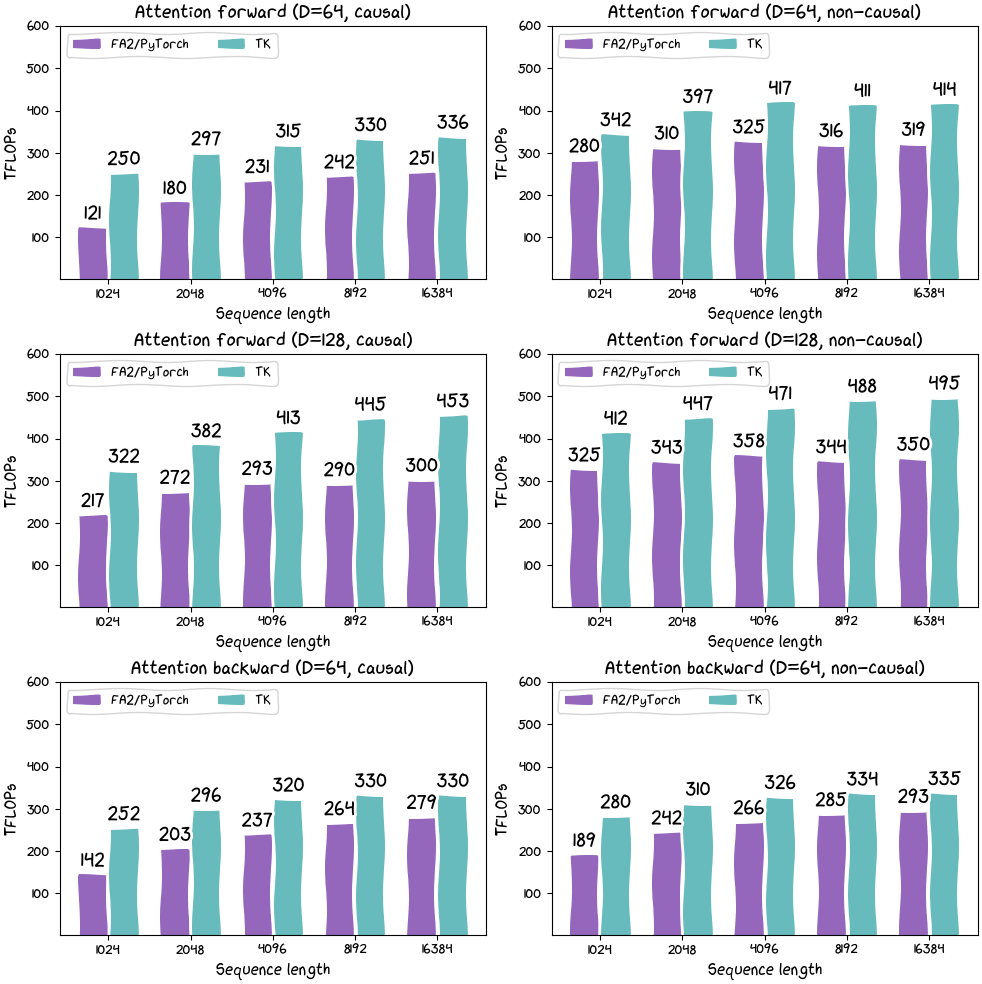
実際にPyTorchのFA2を使用した場合とThunderKittens(TK)を使用した場合でFlash Attentionの計算能力がどれほど異なるのかを計測した結果は下図の通り。紫色がPyTorchのFA2で、水色がThunderKittensの計算能力を示しています。平均するとThunderKittensは約30%のパフォーマンス向上に成功しています。
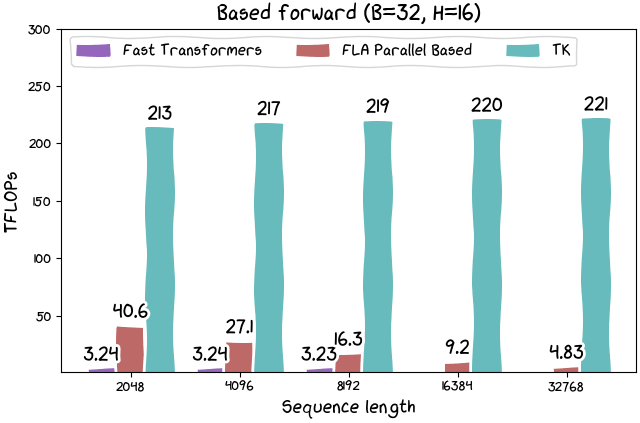
また、Linear Attentionの計算においてはThunderKittensは約215TFLOPSで計算を実行でき、従来の方法に比べて「大幅」な高速化が達成できたとのこと。
ThunderKittensのコードはGitHub上でオープンソースライセンスで公開されています。気になる人は確認してみてください。
・関連記事
「CPU」「GPU」「NPU」「TPU」の違いを分かりやすく説明するとこうなる - GIGAZINE
GPU・CUDAを活用して数値計算やAIのトレーニングを高速化するのに必要な基礎知識のコード例付きまとめ - GIGAZINE
画像生成AI「Stable Diffusion」を最速で実行できるGPUはどれなのか? - GIGAZINE
グラボ向け高速メモリ規格「GDDR7」の仕様が確定、通信速度はGDDR6の2倍 - GIGAZINE
グラボを買い替えずとも画像生成AIの実行速度を高速化できる「Stable Diffusion WebUI Forge」を実際にインストールして生成速度を比較してみた - GIGAZINE
IntelがAIアクセラレータ「Gaudi 3」を発表、NVIDIAのH100より高速かつ低消費電力で一部テストではH200にも勝利 - GIGAZINE
NVIDIAが「消費電力1000Wの爆熱GPU」を開発中か - GIGAZINE
・関連コンテンツ







in ハードウェア, ソフトウェア, Posted by log1d_ts
You can read the machine translated English article Stanford University research group relea….