




Googleが開発した画像分類タスクが可能な機械学習モデル「Vision Transformers」の仕組みとは?

Googleの機械学習モデル「Transformer」は、データを時系列に処理しなくても、自然言語などのデータを翻訳やテキスト要約することが可能で、ChatGPTなどの自然な会話が可能なチャットAIのベースとなっています。また、Transformerの手法を画像分野に応用したモデルが「Vision Transformer」です。ソフトウェアエンジニアのデニス・タープ氏が、「Vision Transformer」のコンポーネントがどのように機能し、データはどのような流れをたどるのか、ビジュアル化して解説しています
A Visual Guide to Vision Transformers | MDTURP
https://blog.mdturp.ch/posts/2024-04-05-visual_guide_to_vision_transformer.html

0:はじめに
前提として、Transformerの仕組みと同様、Vision Transformerも教師ありトレーニングがなされています。つまり、モデルが画像とそれに対応するラベルのデータセットでトレーニングされているというわけです。

1:1つのデータに焦点を当てる
「パッチサイズ1」と呼ばれる単一のデータをピックアップします。

2:画像の分割
Vision Transformerで扱える画像にするために、画像を等しいサイズのパッチに分割します。

3:画像パッチのフラット化
パッチを「p'= p²*c」のベクトルに変換します。なお、ここでのpはパッチのサイズ、cは分割したパッチ数です。

4:パッチ埋め込みベクトルの作成
(PDFファイル)線形変換を利用して、ベクトルに変換した画像パッチをさらにパッチ埋め込みベクトルに変換します。
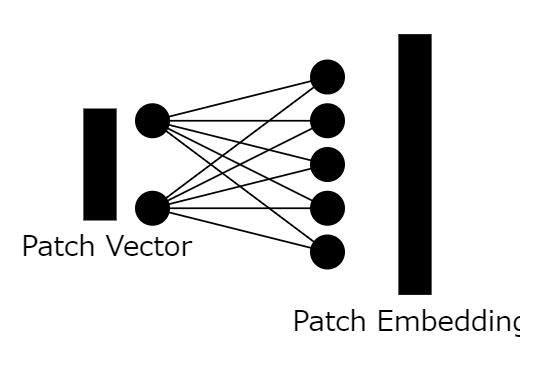
5:全パッチへの適用
全パッチをパッチ埋め込みベクトルに変換します。この結果、n×dで表される配列が出来上がりました。なお、nは画像パッチの数、dはパッチ埋め込みベクトルのサイズです。

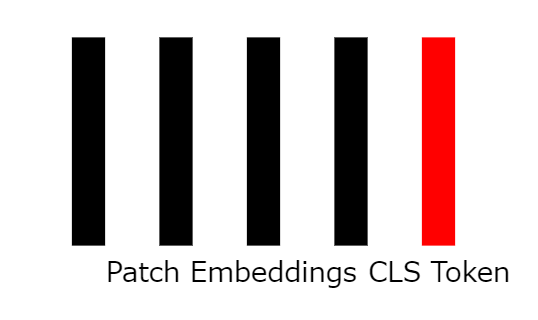
6:分類トークンの追加
モデルを効果的にトレーニングするために、分類トークン(clsトークン)と呼ばれるベクトルを追加します。このベクトルはネットワークの学習可能なパラメーターで、ランダムに初期化されるとのこと。
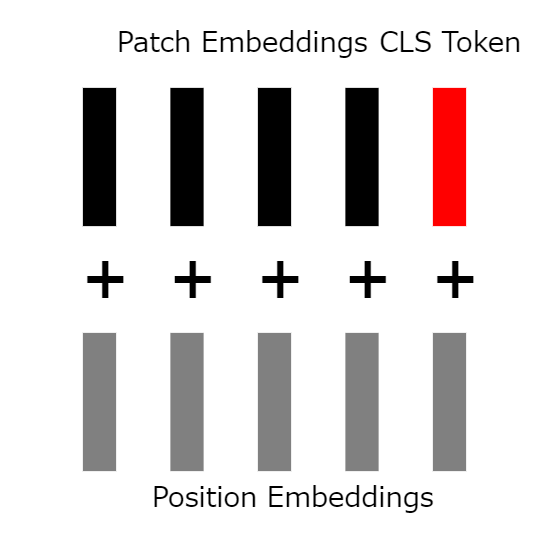
7:位置埋め込みベクトルの追加
これまでの手順では、ベクトルに位置情報が関連付けられていません。そこで、学習可能でランダムに初期化された「位置埋め込みベクトル」をclsトークンを含めた全てのベクトルに追加します。
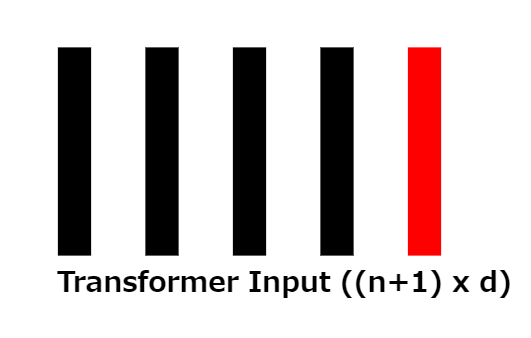
8:トランス入力
位置埋め込みベクトルが追加されると、サイズ(n+1) ×dの配列が残ることになり、これは変圧器への入力に対応します。
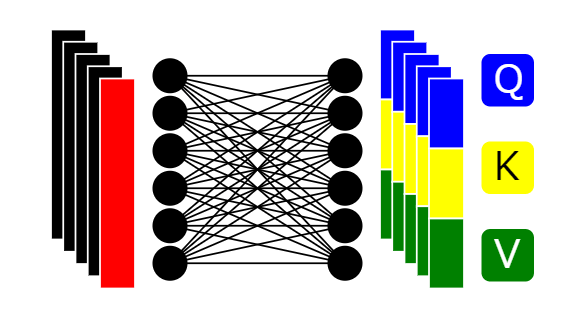
9:3種のベクトルへの振り分け
サイズ(n+1) ×dの配列をそれぞれQに該当する「クエリベクトル」、Kに該当する「キーベクトル」、Vに該当する「値ベクトル」に振り分けます。
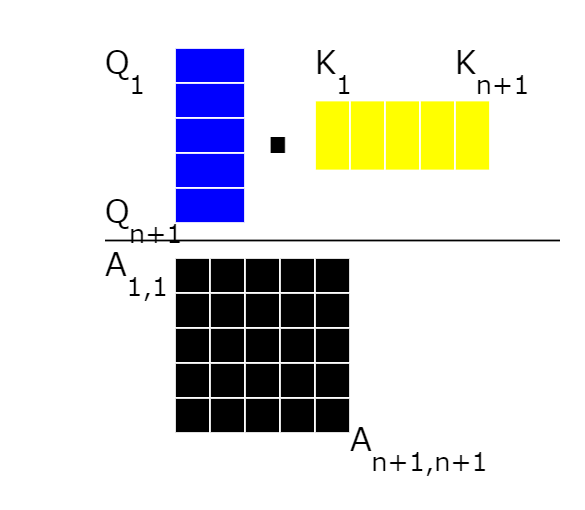
10:アテンションスコアの計算
注意スコアを計算するために、全てのクエリベクトルとキーベクトルを乗算します。
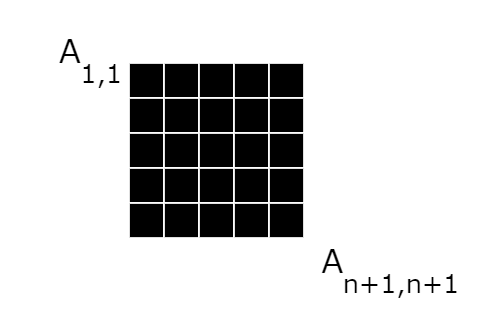
11:アテンションスコアマトリックス
計算によってアテンション行列が得られたので、全ての行の合計が1になるように「Softmax」関数を全ての行に適用します。
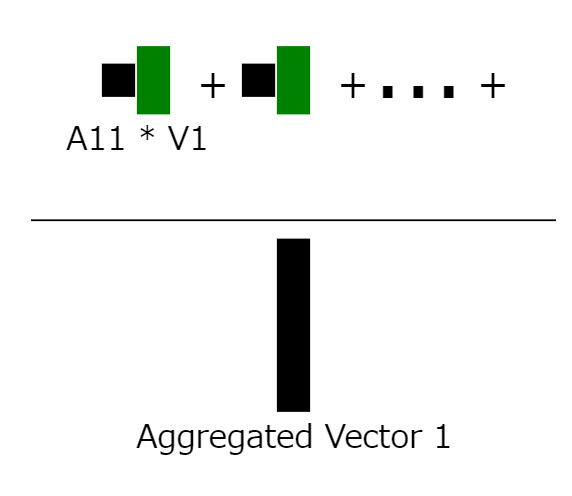
12:集約されたコンテキスト情報の計算
行列の最初の行に注目し、パッチ埋め込みベクトルの集約されたコンテキスト情報を計算します。その後、全体を値ベクトルの重みとして使用することで、最初のパッチ埋め込みベクトルの集約されたコンテキスト情報ベクトルが得られます。
13:全ての行への適用
アテンション行列全体にこの計算を適用します。この結果、N+1個の集約されたコンテキスト情報ベクトルを取得することになります。

14:プロセスの繰り返し
ここまでのプロセスを、ヘッド数に応じて何度も繰り返します。この結果、複数の集約されたコンテキスト情報ベクトルが出力されるというわけです。
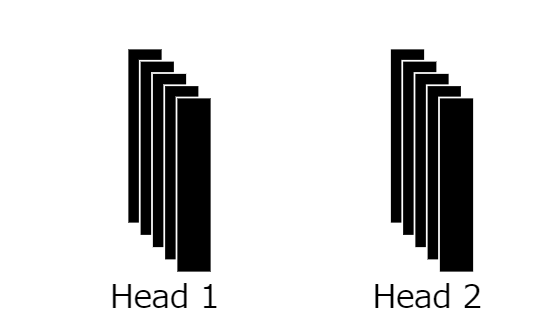
15:サイズdのベクトルへのマッピング
複数のヘッドを統合し、パッチ埋め込みベクトルと同じサイズdのベクトルにマッピングします。
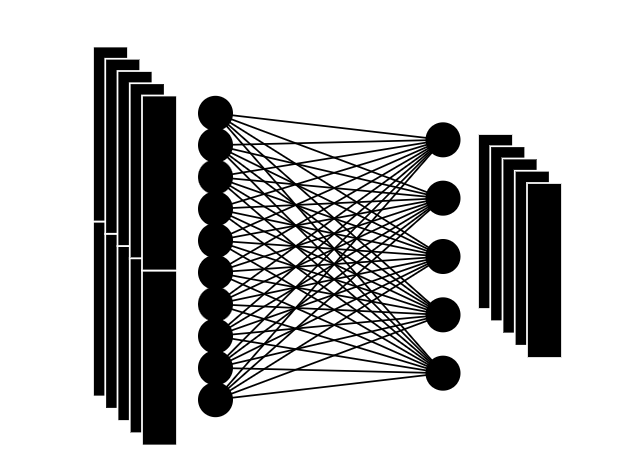
16:アテンションレイヤーの完成
ベクトルへのマッピングによって、入力に使った埋め込みベクトルとまったく同じサイズで同量の埋め込みが出来上がりました。
17:残留接続の適用
位置埋め込みベクトルを追加した層の入力をアテンションレイヤーの出力に追加します。
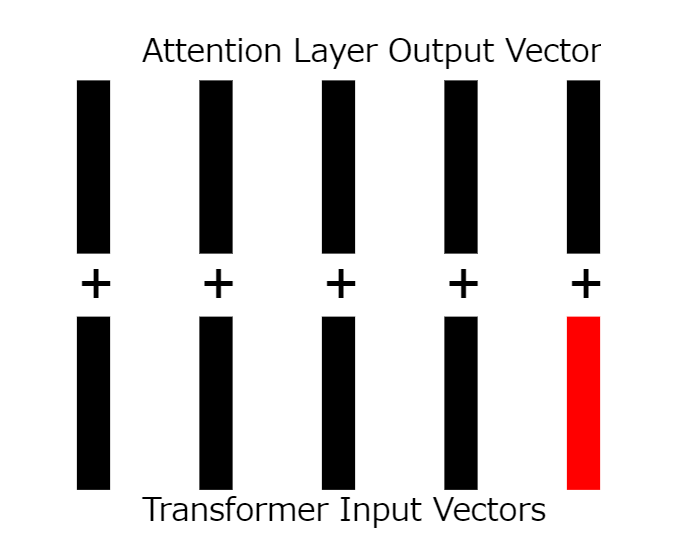
18:残留接続を計算
入力と出力をそれぞれ加算します。
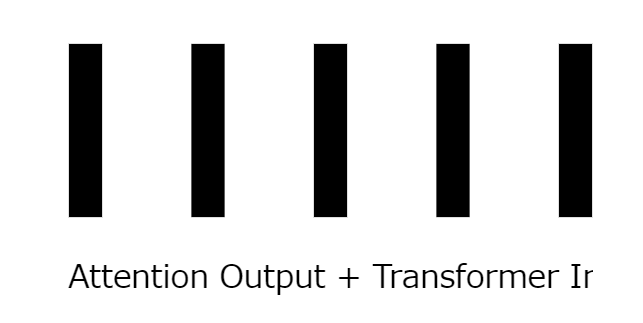
19:フィードフォワードネットワーク
ここまでに生まれた出力を、非線形活性化関数を備えたフィードフォワードネットワークを使ってフィードします。
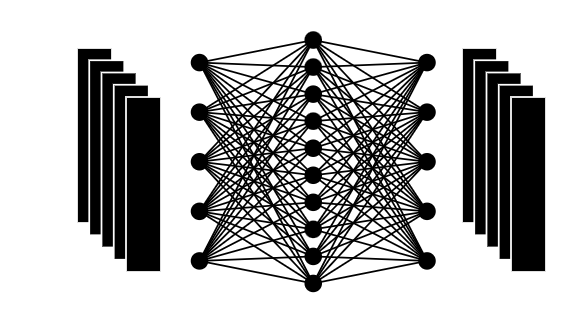
20:最終結果
複数の処理を実施することで、入力と同じサイズの出力が生成されました。
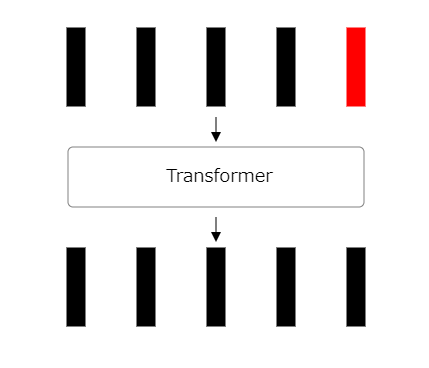
21:処理の繰り返し
ここまでのプロセスを複数回繰り返します。
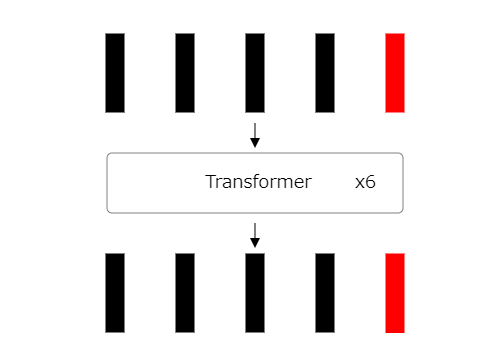
22:分類トークン出力の識別
Vision Transformerでの最後のステップとして、分類トークンの出力を特定します。
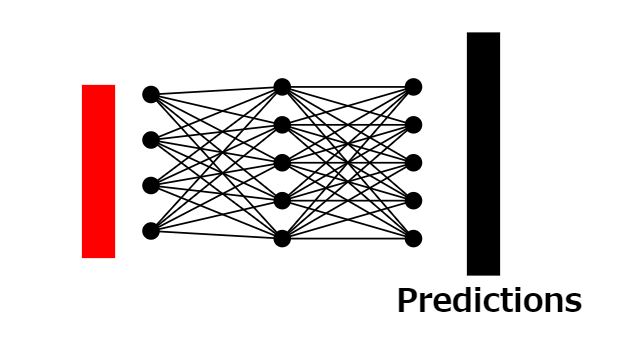
23:分類確率の予測
分類トークンの出力と完全に接続された別のニューラルネットワークを使用して、元となった画像の分類確率を予測します。
24:Vision Transformerのトレーニング
交差エントロピー誤差を使用してVision Transformerをトレーニングします。
・関連記事
GoogleやGoogle DeepMindが2023年のAIとコンピューティングについての研究成果を振り返る - GIGAZINE
ChatGPTにも使われる機械学習モデル「Transformer」が自然な文章を生成する仕組みとは? - GIGAZINE
より高い品質の翻訳を実現するGoogleの「Transformer」がRNNやCNNをしのぐレベルに - GIGAZINE
ChatGPTなどの大規模言語モデルはどんな理論で成立したのか?重要論文24個まとめ - GIGAZINE
ニューラルネットワークの中身を分割してAIの動作を分析・制御する試みが成功、ニューロン単位ではなく「特徴」単位にまとめるのがポイント - GIGAZINE
・関連コンテンツ






in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article What is the mechanism behind 'Vision Tra….