




Microsoftが1.58ビットの大規模言語モデルをリリース、行列計算を足し算にできて計算コスト激減へ
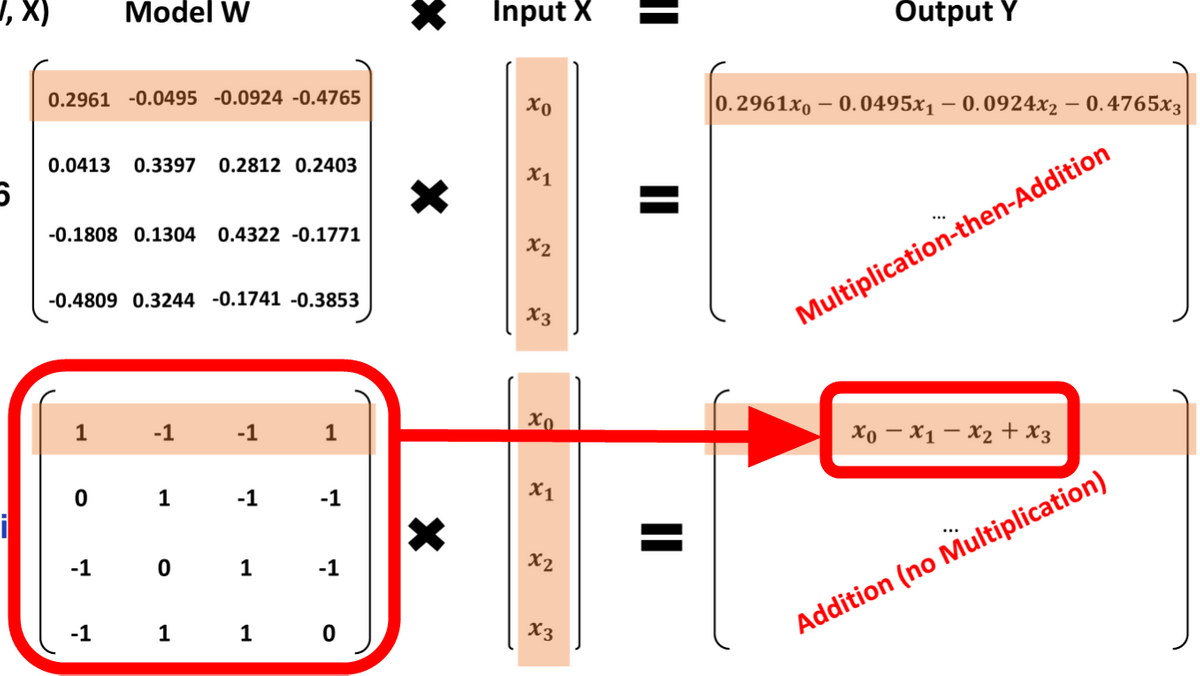
Microsoftの研究チームがモデルのウェイトを「-1」「0」「1」の3つの値のみにすることで大規模言語モデルの計算コストを激減させることに成功したと発表しました。
[2402.17764] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
https://arxiv.org/abs/2402.17764
従来のモデルであれば入力に対して「0.2961」などのウェイトをかけ算してから足し引きする必要がありましたが、「-1」「0」「1」の3値のみであればかけ算が不要になり、全ての計算を足し算で行えるようになります。
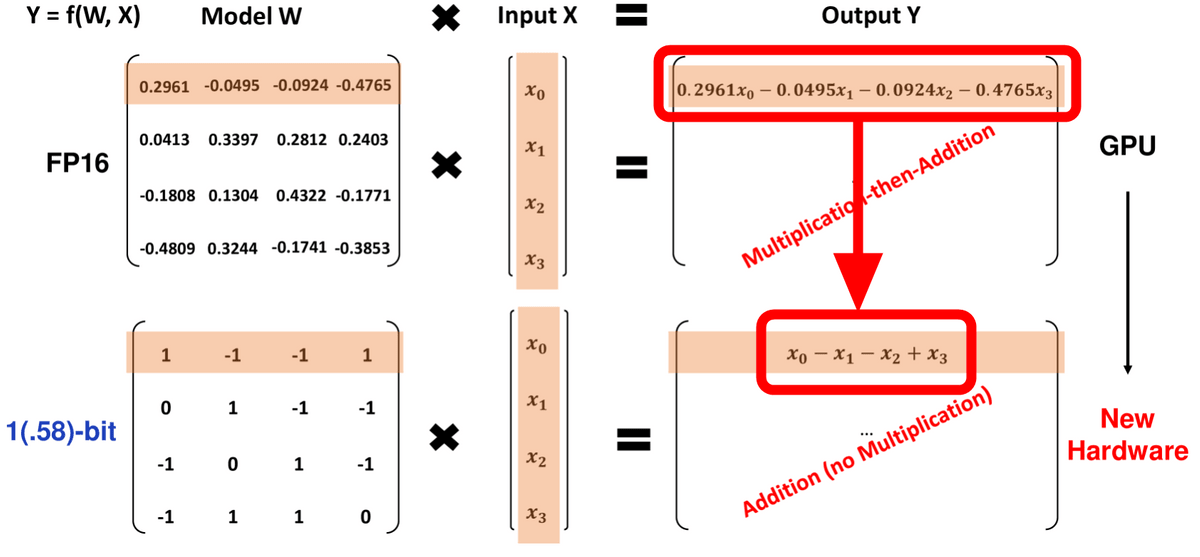
そのため、同じ性能を出すのに必要なコストが通常の大規模言語モデルに対して激減するとのこと。なお、それぞれのパラメーターが「-1」「0」「1」という3つの値を取るためlog[2](3)の値より「1.58ビットのモデル」と述べられています。
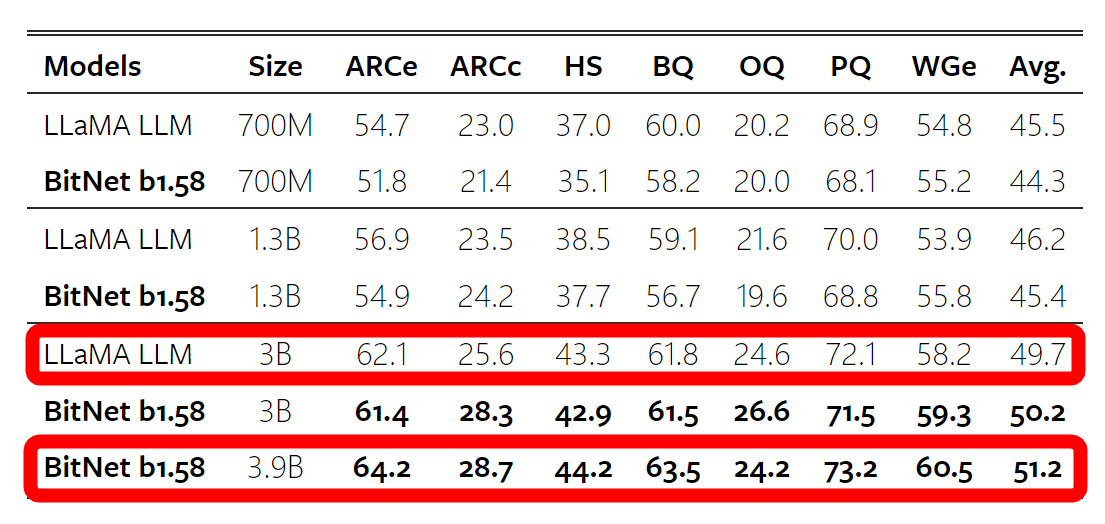
さまざまなベンチマークにおいて学習データに含まれないデータを処理させる、いわゆるゼロショットの性能をLLaMAと比較した結果は下図の通り。同じサイズのLLaMAに対してBitNetは性能面で同等以下となっていますが、LLaMAの3Bモデルに対しBitNetの3.9Bモデルはほとんどの指標で上回るなど、少しモデルサイズを大きくすることで従来の性能を維持できることが示唆されています。
性能面ではいい勝負と言えそうでしたが、必要なメモリの量やレイテンシにおいてはBitNetの圧勝となりました。LLaMAの3Bモデルに対し、BitNetの3.9Bモデルは必要メモリ量が3.32分の1、レイテンシは2.4分の1と大幅に減少しています。
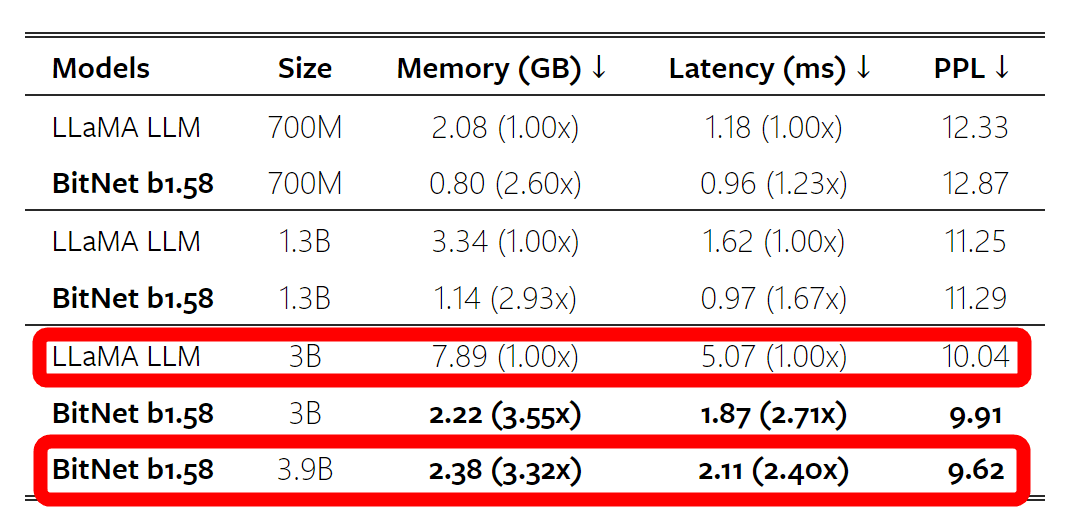
なお、レイテンシやメモリ消費量の差はモデルのサイズが大きくなるほど開いていき、70Bモデル同士の比較ではBitNetのレイテンシはLLaMAの4.1分の1でメモリ消費量は7.16分の1まで削減できるとのこと。
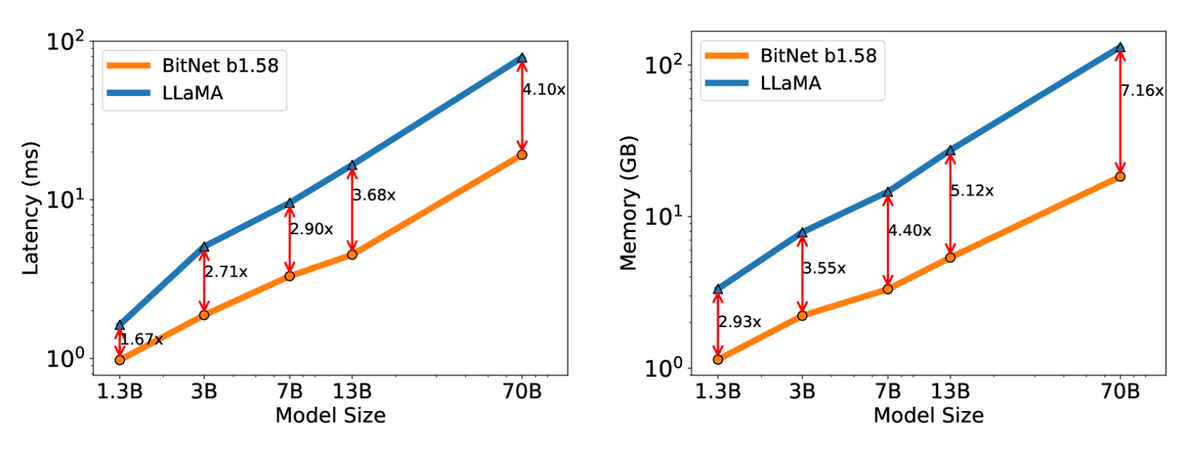
また、行列演算のコストが71.4分の1へと激減しているほか、BitNetはトータルのエネルギー消費量を70BモデルでLLaMAの41.2分の1へと削減することに成功しています。
バッチサイズは11倍、スループットは8.9倍に向上。

2兆トークンを使用したトレーニング後のベンチマークは下図の通りで、1.58ビットのモデルでも強力な一般化能力があることが確認されました。

今回の手法を利用することで行列演算に必要なかけ算の量を大幅に削減できるため、論文では「1bitの大規模言語モデル用の新たなハードウェア設計への扉を開く」と述べられています。
・関連記事
Googleがオープンかつ商用利用可能で軽量な大規模言語モデル「Gemma」を公開 - GIGAZINE
なぜ大規模言語モデル(LLM)はだまされやすいのか? - GIGAZINE
大規模言語モデルの開発者が知っておくと役立つさまざまな数字 - GIGAZINE
GPU非搭載ノートPCでもコマンド不要で各種言語モデルの性能を試せる実行環境「LM Studio」レビュー - GIGAZINE
ChatGPTなどの大規模言語モデルはどんな理論で成立したのか?重要論文24個まとめ - GIGAZINE
・関連コンテンツ








in ソフトウェア, Posted by log1d_ts
You can read the machine translated English article Microsoft releases a 1.58-bit large-scal….