「声で指示するだけで指示したとおりのプログラムが生成・実行される」ツールをAmiVoiceとOpen Interpreterでサクッと自作してみた
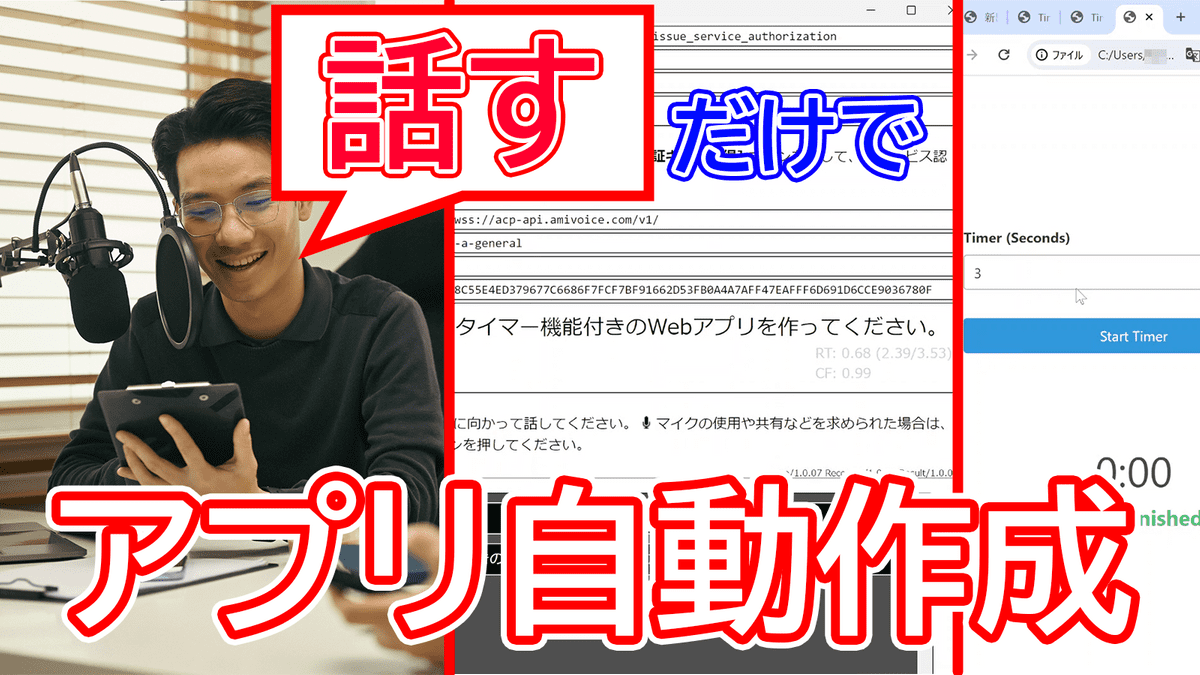
プログラミングを行う事でさまざまな作業をコンピューターに任せることが可能ですが、プログラムの作成はなかなか面倒くさいものです。今回はそうした面倒な作業をAIに任せるべく、音声認識エンジンの「AmiVoice」とプログラムの自動作成・実行支援ツールの「Open Interpreter」を使用して「声で指示するだけで指示したとおりのプログラムが生成・実行される」というツールを作成してみました。
AI音声認識のAPI・SDKなら-AmiVoice Cloud Platform(アミボイス)
https://acp.amivoice.com/
AmiVoice API 利用申し込み
https://acp.amivoice.com/amivoice_api/regist/
open-interpreter/docs/README_JA.md at main · KillianLucas/open-interpreter
https://github.com/KillianLucas/open-interpreter/blob/main/docs/README_JA.md
Open Interpreterは下記の記事でレビューしている通り、自然言語で指示したとおりにプログラミングを行ってくれるツールです。今回はまずOpen Interpreterを実行できるようにセットアップ後、AmiVoiceを利用して音声でOpen Interpreterに指示できるようにしていきます。
チャット形式でプログラミングが可能なローカルで動作するオープンソースなAIツール「Open Interpreter」を使ってみた - GIGAZINE
・目次
◆環境構築1:Python
◆環境構築2:Node.js
◆環境構築3:Git
◆Open Interpreterのセットアップ
◆Electerpreterのセットアップ
◆AmiVoiceのセットアップ
◆AmiVoiceとElecterpreterを合体する
◆音声でAIに指示してコードを生成・実行させる
◆環境構築1:Python
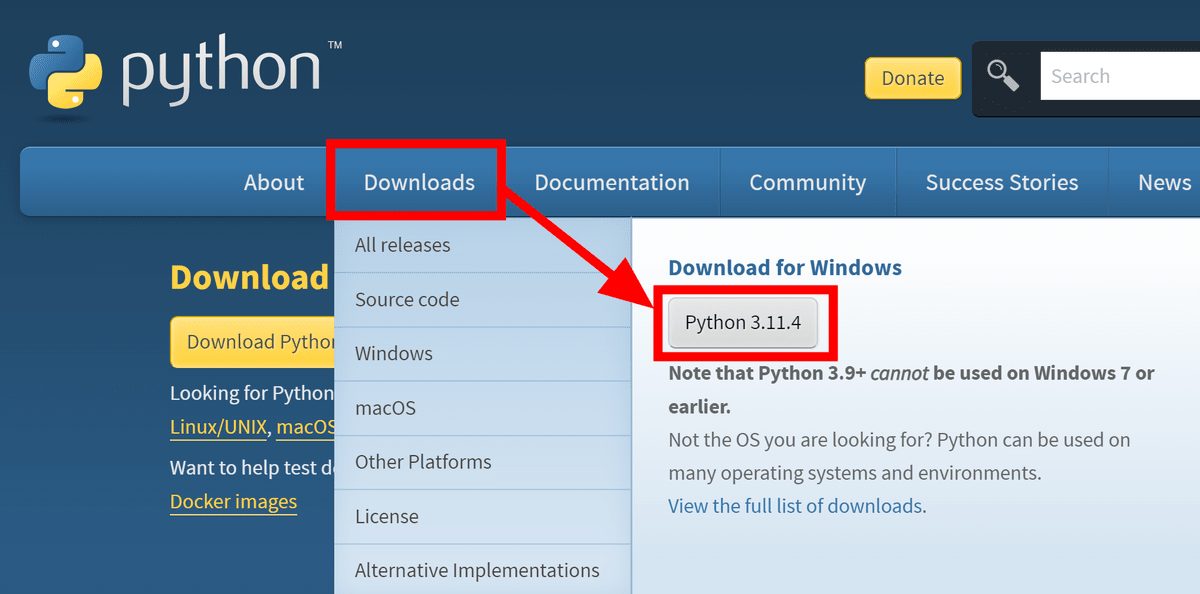
Open Interpreterを実行するにはPythonが必要なので、まずPythonの公式サイトへ行き、「Downloads」にカーソルをのせると出てくる「Python 3.XX.X」というボタンをクリックします。
インストーラーがダウンロードされるので、ダブルクリックして実行。

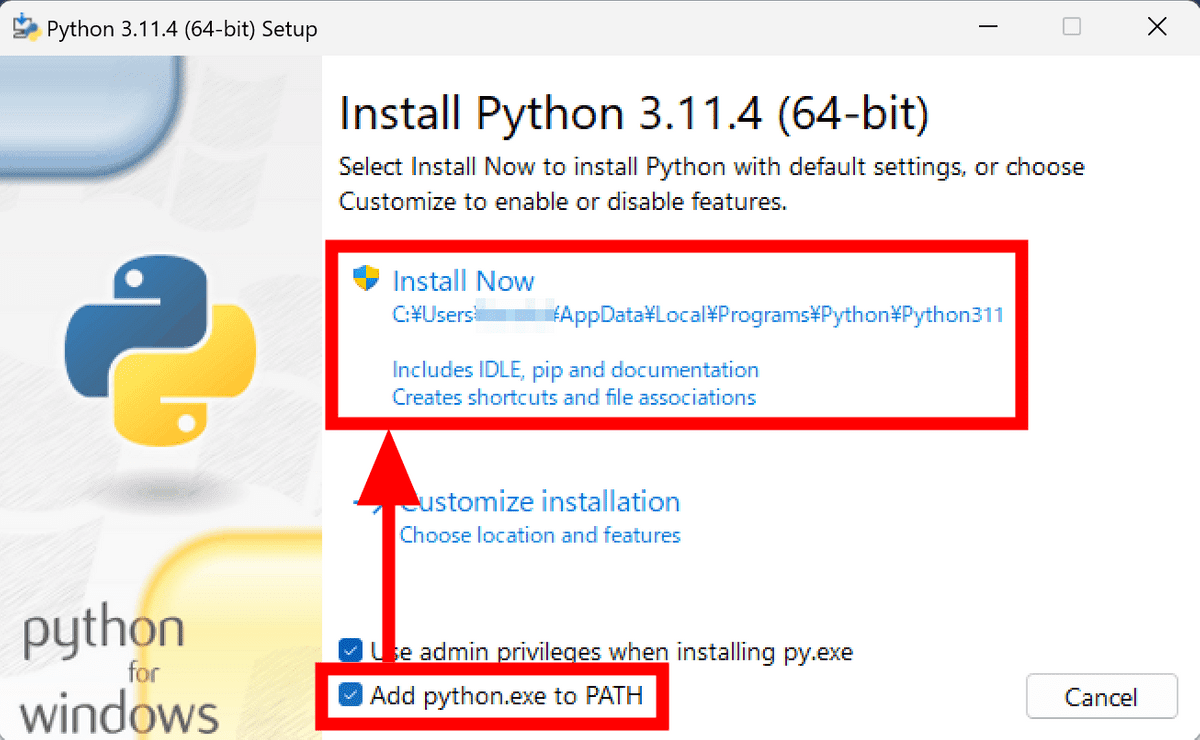
「Add python.exe to PATH」にチェックを入れて「Install Now」をクリックします。
インストールが始まるのでしばらく待機。完了したら「Close」をクリックしてインストーラーを終了します。
◆環境構築2:Node.js
Node.jsの公式サイトへ行き、「LTS」と書かれたバージョンのボタンをクリックします。

実行ファイルがダウンロードされるので、ダブルクリックして実行。
セットアップウィザードが起動します。「Next」をクリック。
「I accept the terms in the License Agreement(ライセンスに同意する)」にチェックマークを付けて「Next」をクリックします。
「Next」をクリック。
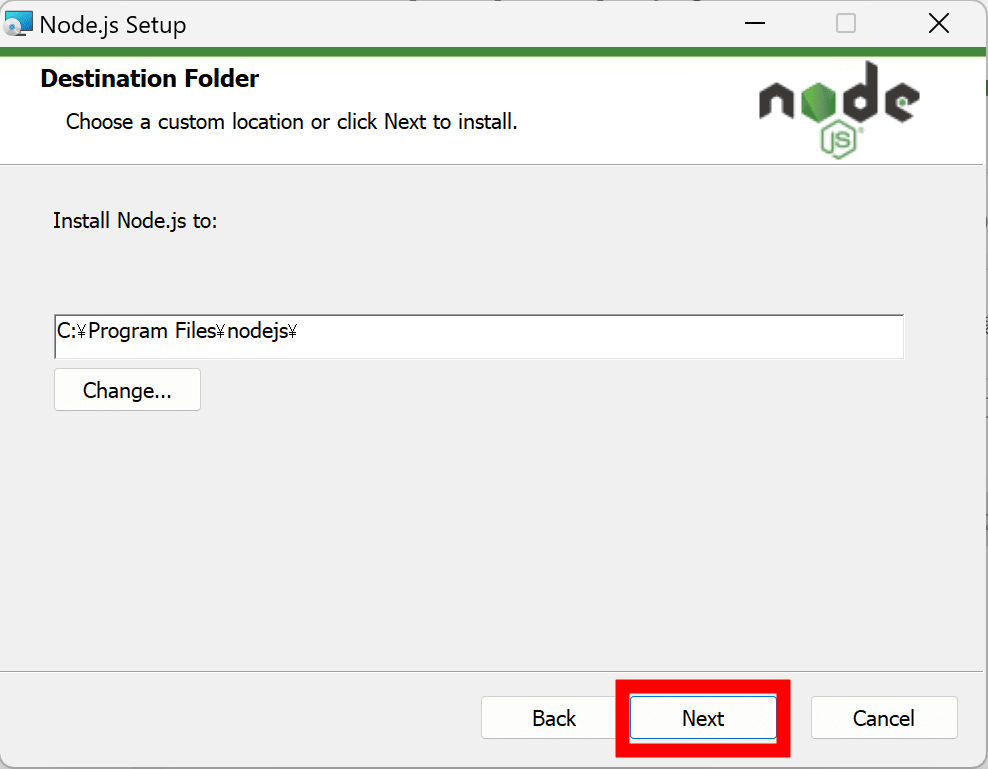
標準で全てのコンポーネントがインストールされるようになっているので、特に変更せず「Next」をクリックします。
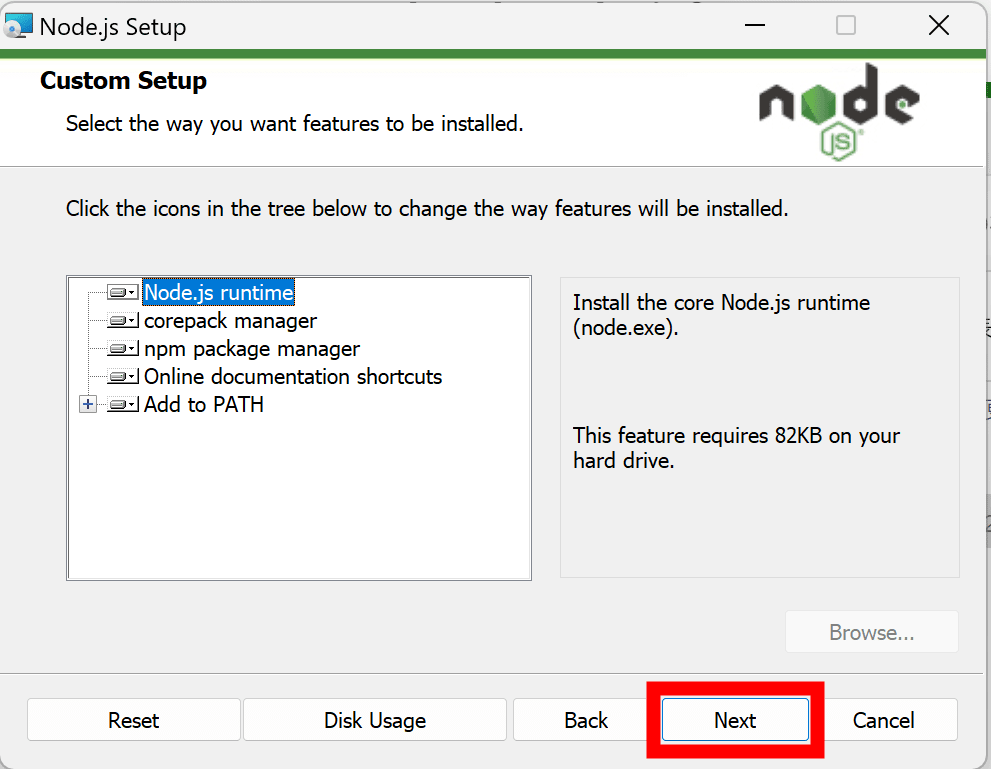
ライブラリの中には使用時にCやC++のソースコードからコンパイルするものもあり、Node.jsのインストール時にCやC++のコンパイル環境を整えるかについても設定できます。今回はコンパイルが必要なライブラリを使用しないのでチェックを付けずに「Next」をクリックしました。
「Install」をクリック。
これでNode.jsのインストールが完了しました。「Finish」をクリックしてセットアップウィザードを終了します。
◆環境構築3:Git
Gitのダウンロードページにアクセスし、「Download for Windows」をクリック。
「Click here to download」をクリックしてインストーラーをダウンロードします。
インストーラーをダブルクリックして起動。
ここから大量の設定項目が用意されています。今回は全て変更せず標準設定のままインストールを進めていきます。念のため全ての設定項目のスクリーンショットを用意していますが、不要であれば「◆Open Interpreterのセットアップ」までスキップしてください。
ライセンスを確認して「Next」をクリック。
「Next」をクリックします。
「Next」をクリック。
「Next」をクリックします。
「Next」をクリック。
「Next」をクリックします。
「Next」をクリック。
「Next」をクリックします。
「Next」をクリック。
「Next」をクリックします。
「Next」をクリック。
「Next」をクリックします。

「Install」をクリック。
Gitのインストールが完了しました。「Finish」をクリックしてインストールウィザードを終了します。
◆Open Interpreterのセットアップ
スタートメニューを開き、「cmd」と検索すると表示されるコマンドプロンプトをクリックして起動します。
下記のコマンドでOpen Interpreterをインストール。
pip install open-interpreter
そして下記のコマンドで起動します。
interpreter
毎回の起動時にOpenAIのAPI keyの入力を求められます。OpenAIのほか、「Azure」「Anthropic」「Replicate」「AI21」「OpenRouter」「Cohere」「Petals」が利用可能で、ローカルの大規模言語モデルで動作させることも可能とのこと。ただし、GPT-4の利用を強く推奨するとのことだったので今回はGPT-4を使用します。
OpenAIのAPI keysの画面を開き、「Create new secret key」をクリック。
分かりやすい名前をつけて「Create secret key」をクリックします。
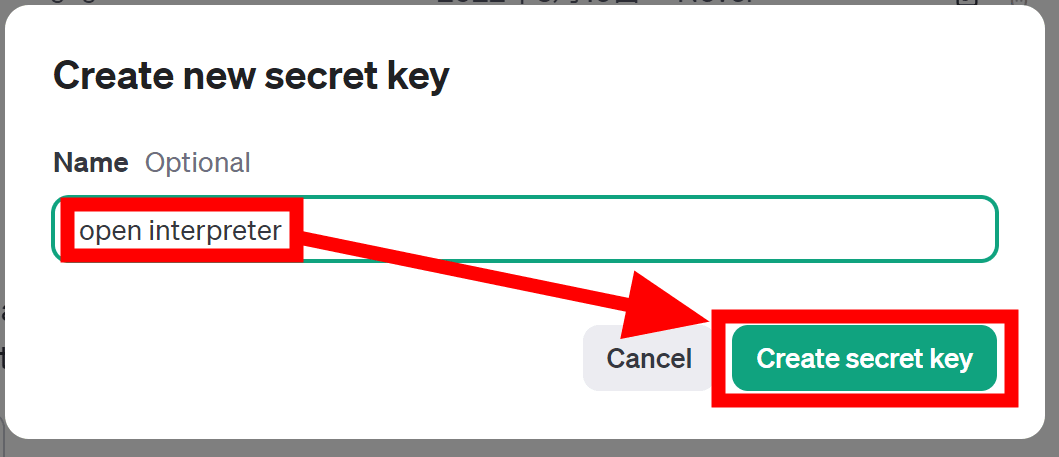
新たなAPIキーが生成されるのでコピー。
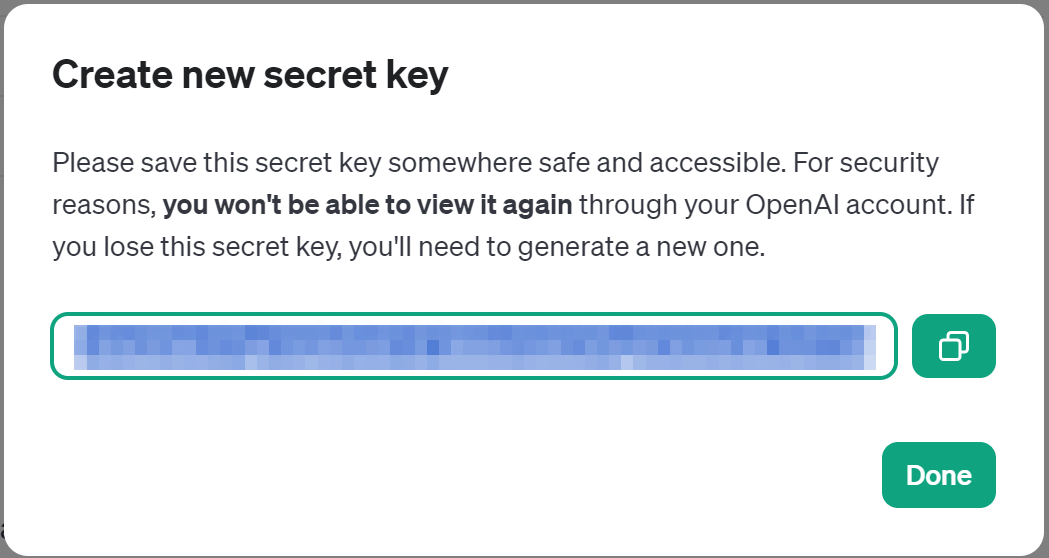
コマンドプロンプトに戻り、ペーストしてEnterキーを押せば準備完了です。なお、毎回APIキーを入力するのが面倒な場合は環境変数に登録すればOKとのこと。
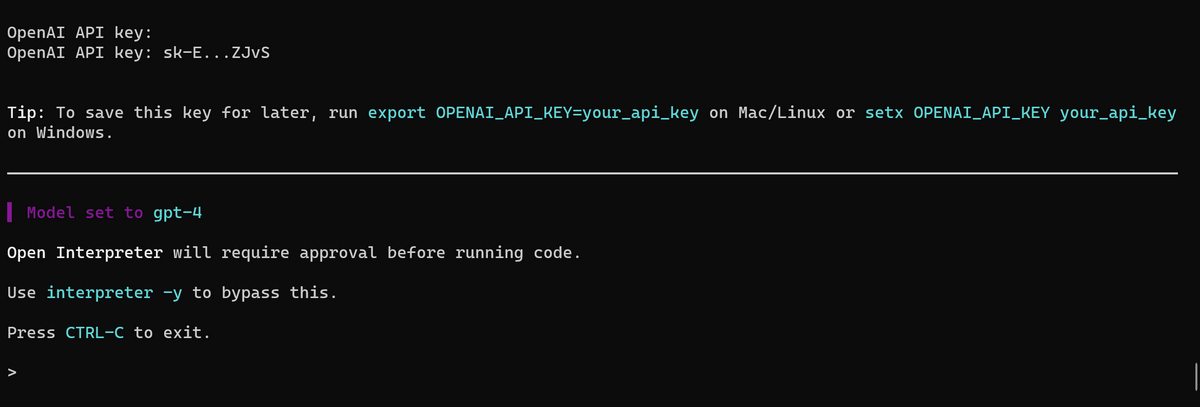
Open Interpreterが実行できることが確認できたら、次に音声認識のセットアップに進むので一度CtrlキーとCキーを同時に押してOpen Interpreterを終了しておきます。
◆Electerpreterのセットアップ
マイクを使用するのにブラウザを利用したいため、ウェブの技術を使用してデスクトップアプリを作成できるElectronというツールを使います。幸い、ElectronからOpen Interpreterを使えるようにセットアップ済みの「Electerpreter」というライブラリが存在しているため、今回はこのElecterpreterを使用します。
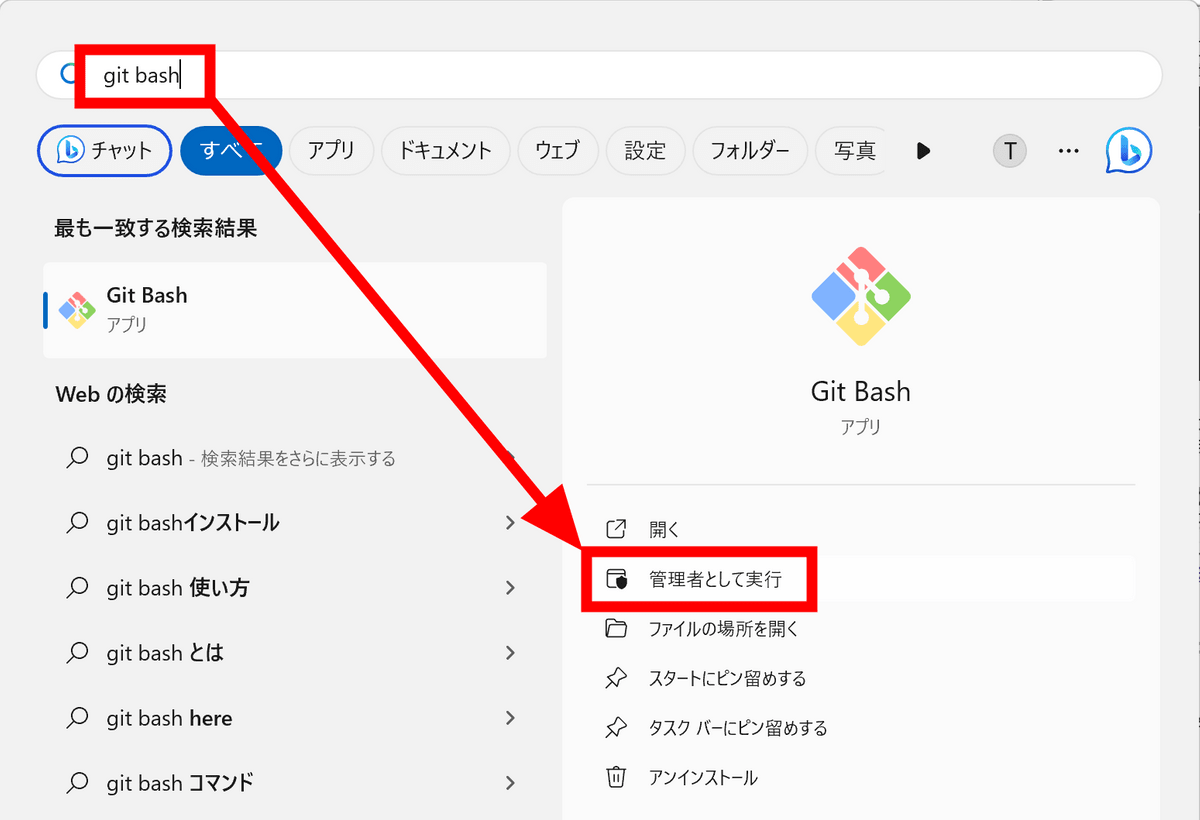
Gitのインストール時に「Git Bash」がインストールされているので、スタートメニューで検索して「管理者として実行」をクリック。
下記のコマンドでElecterpreterをダウンロード。
git clone https://github.com/mrdiamonddirt/Electerpreter.git
なお、Git Bashでは「Ctrl+V」の貼り付けショートカットを使用することができませんが、画面の何も無いところを右クリックして「Paste」をクリックするとクリップボードの中身を貼り付けることができます。
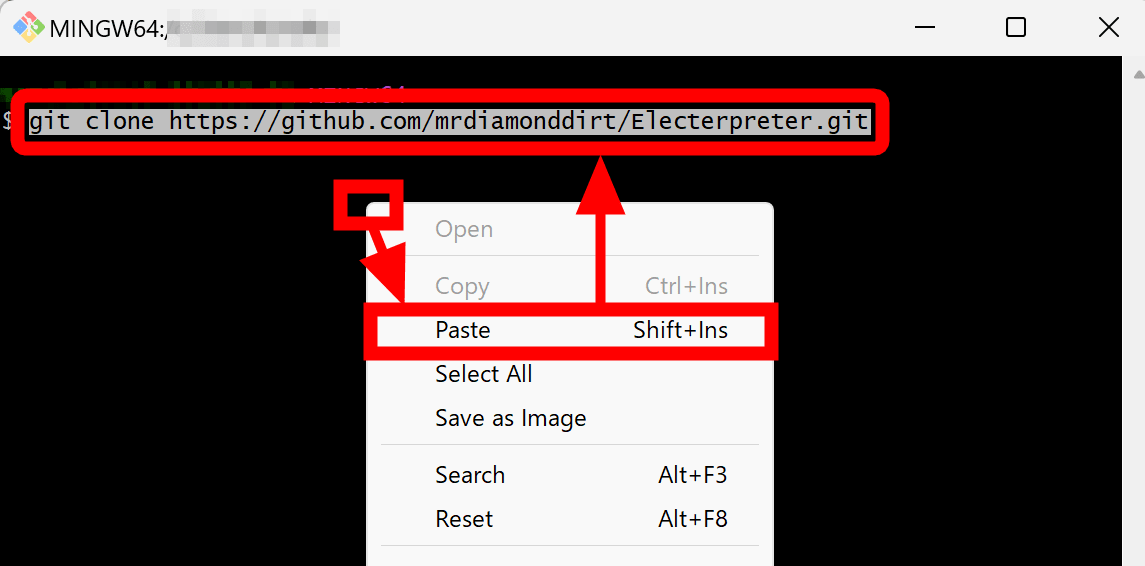
Electerpreterがダウンロードできたら下記のコマンドでフォルダを移動します。
cd Electerpreter
また、この先でファイルを変更する予定なので下記のコマンドでElecterpreterのフォルダをエクスプローラーで開いておきます。
explorer .
下記のコマンドでElecterpreterの実行に必要なライブラリをインストールします。
npm install
「npm install」のコマンドを実行しても画面上に変化が起きず、ちゃんと実行されているのか不安でしたが53秒後に下図のようにインストールが完了しました。
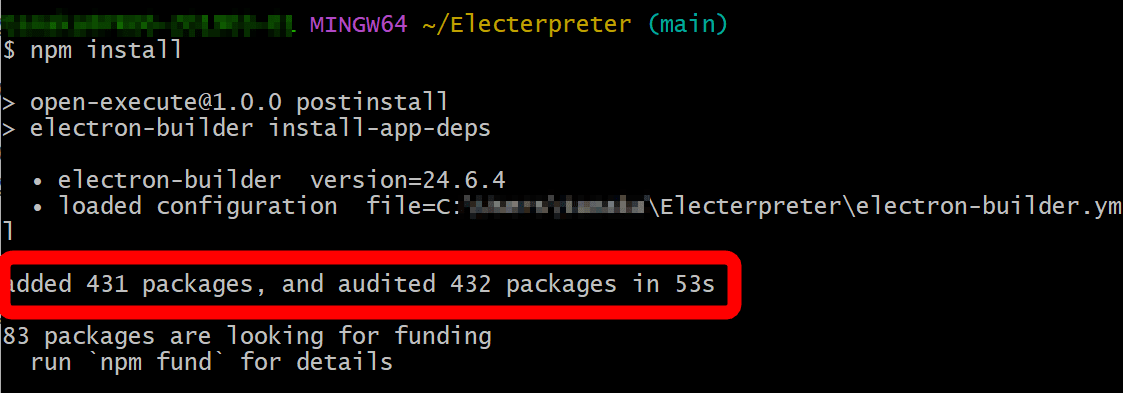
下記のコマンドでElecterpreterを起動します。
npm run dev
起動するとこんな感じ。「Open Interpreterの新バージョンが出ているのでアップグレードしてね」「OpenAIのAPIキーが見つかりません」という2つのメッセージが出現していました。
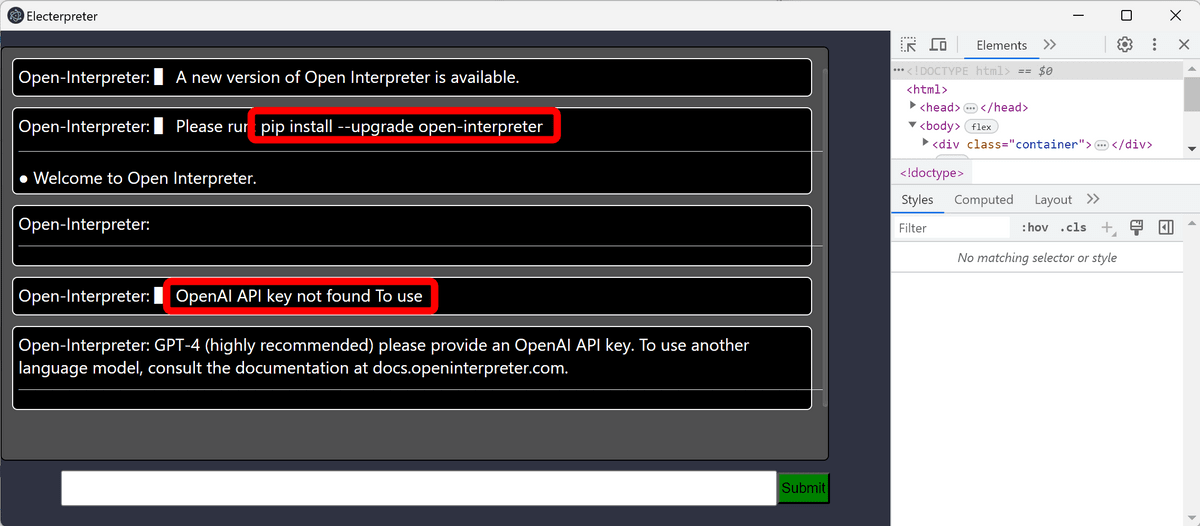
一度ウィンドウを閉じてElecterpreterを終了し、下記のコマンドでOpen Interpreterを最新のバージョンへアップグレードします。
pip install --upgrade open-interpreter
そして下記のコマンドでOpenAIのAPIキーを環境変数に設定。Open Interpreterの設定時に作成したAPIキーを無くしてしまった場合は再発行できないため、新たにAPIキーを作成すればOKです。
export OPENAI_API_KEY=sk-○○○○○○○○○○○○○○○○○○○○
改めてElecterpreterを起動します。
npm run dev
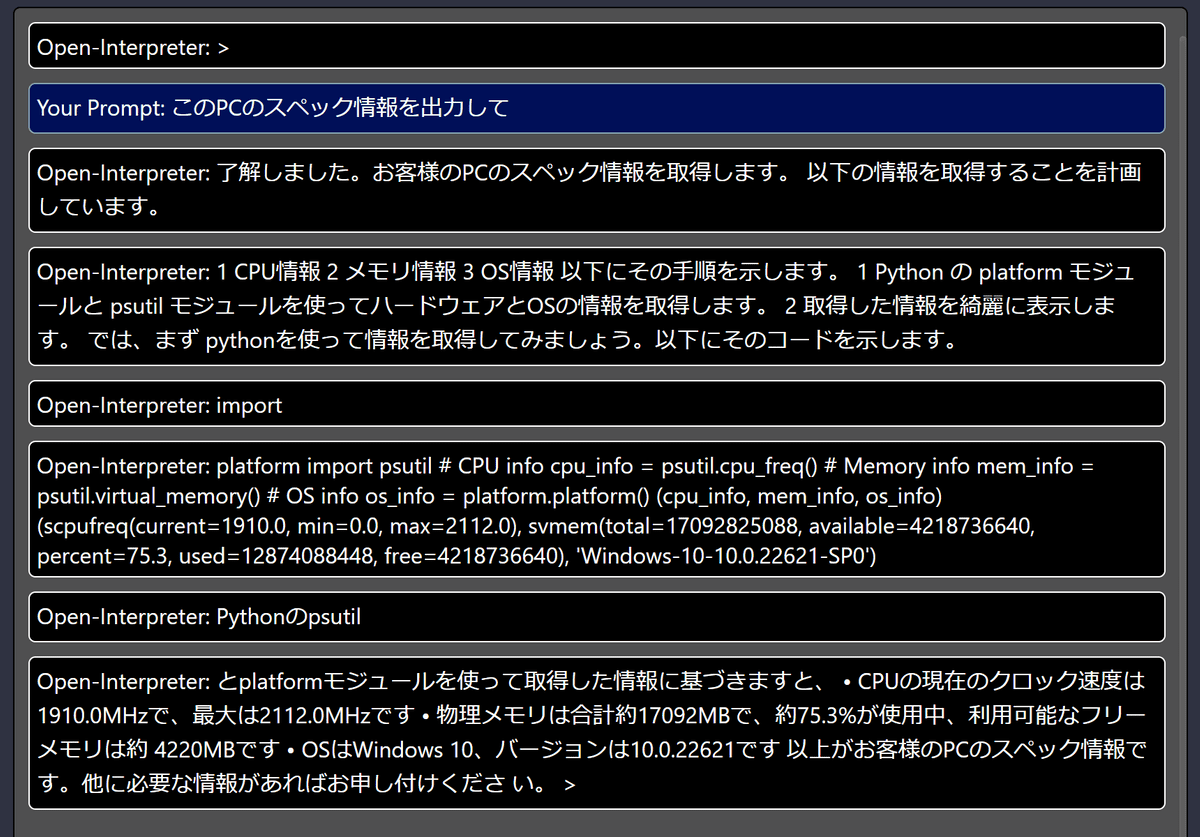
「Open-Interpreter: >」と表示されたら準備完了。下部の入力欄に「このPCのスペック情報を出力して」と指示を入れて「Submit」をクリックしてみます。
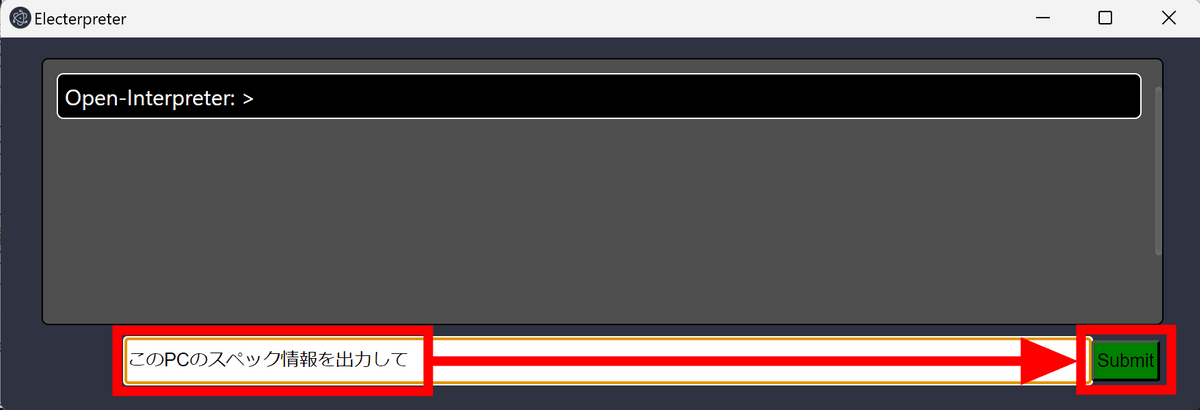
下図のように出力されました。改行せずに表示されてしまっているため、非常に読みづらくなっています。
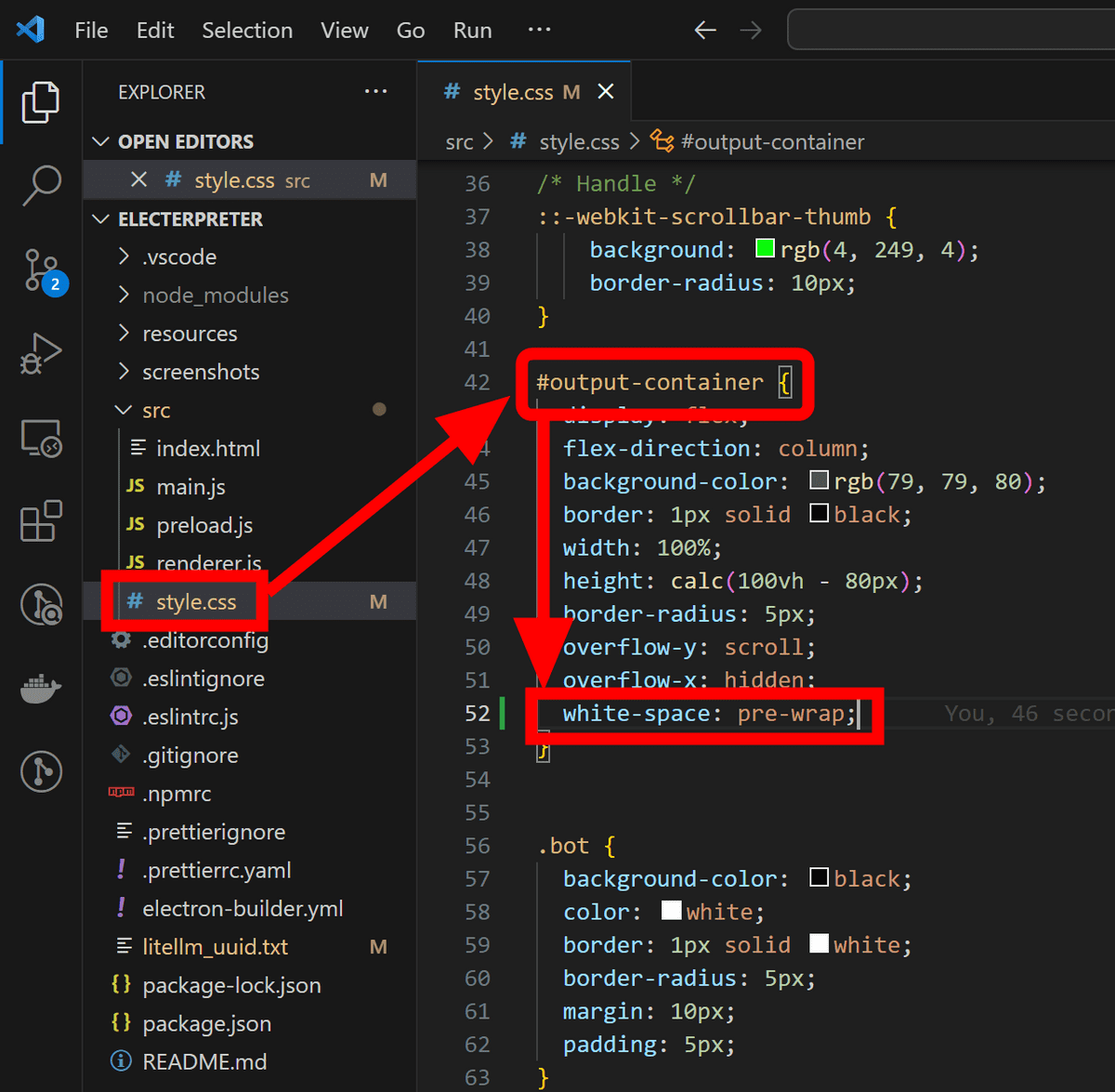
Electerpreterの「src」フォルダ内にある「style.css」の中身を編集して修正します。今回はテキストエディタにVisual Studio Codeを使用しますが、メモ帳を始めどんなテキストエディタを使用しても大丈夫です。style.cssを開いたら「#output-container」の中に「white-space: pre-wrap;」という行を追加して保存します。
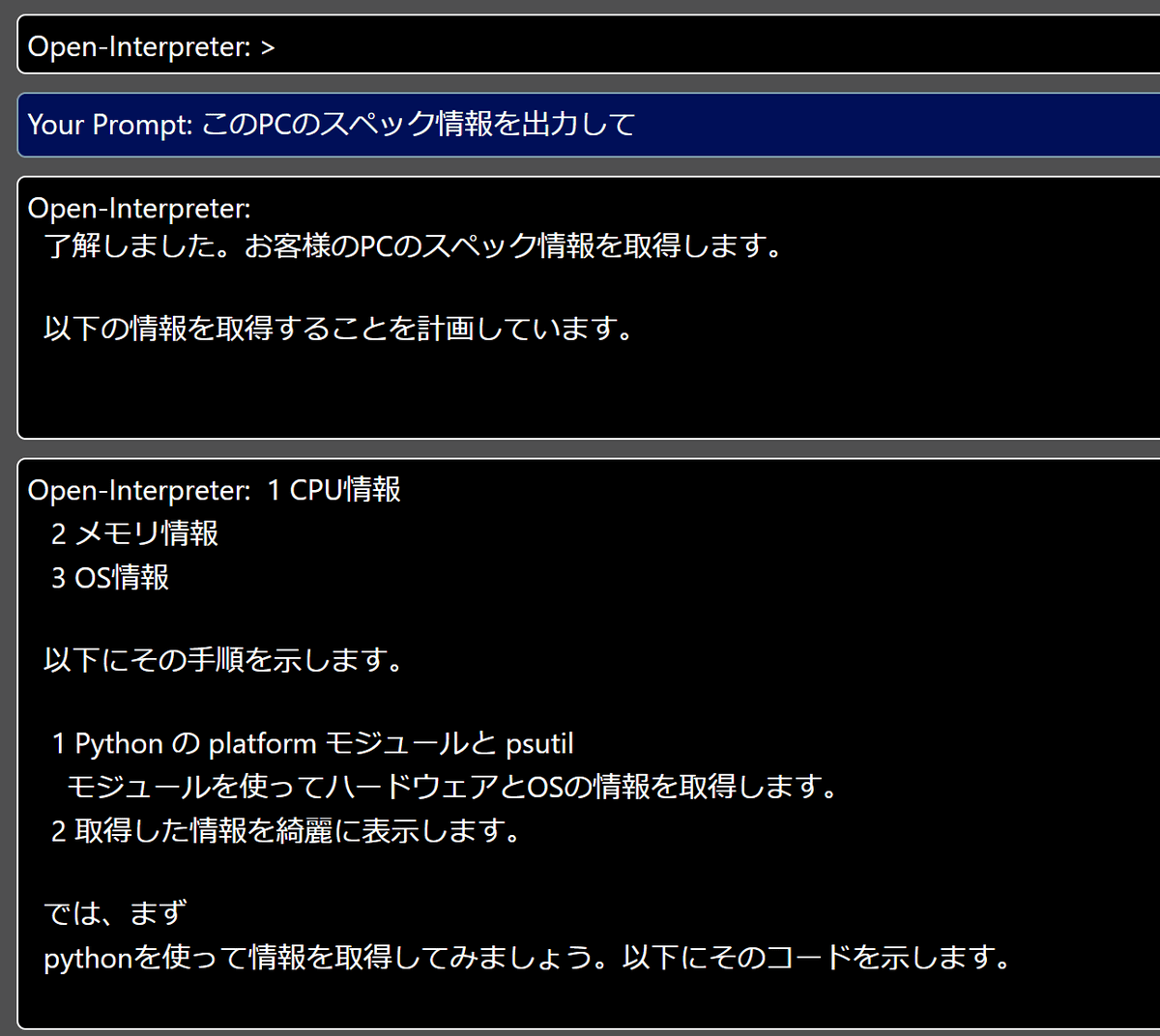
Electerpreterの画面で「Ctrl+R」キーを押して再読み込みし、先ほどと同じように指示すると下図の通り出力されました。改行が反映されて読みやすくなっています。
◆AmiVoiceのセットアップ
続いて、Electerpreterに音声認識をくっつけます。今回は音声認識エンジンとして日本の企業が作った日本語を得意とする「AmiVoice」を使用します。AmiVoiceの実力については下記の記事でレビューしているので確認してみて下さい。
開発実績25年・日本シェアNo1の音声認識サービス「AmiVoice」の実力はどれほどなのか?実際に使ってみた&GIGAZINE読者専用無料期間10倍クーポンあり - GIGAZINE

AmiVoiceのトップページへ行き、「APIを無料で利用開始」をクリック。
メールアドレスを入力し、「利用規約とSLAに同意する」にチェックを入れて「送信」をクリックします。
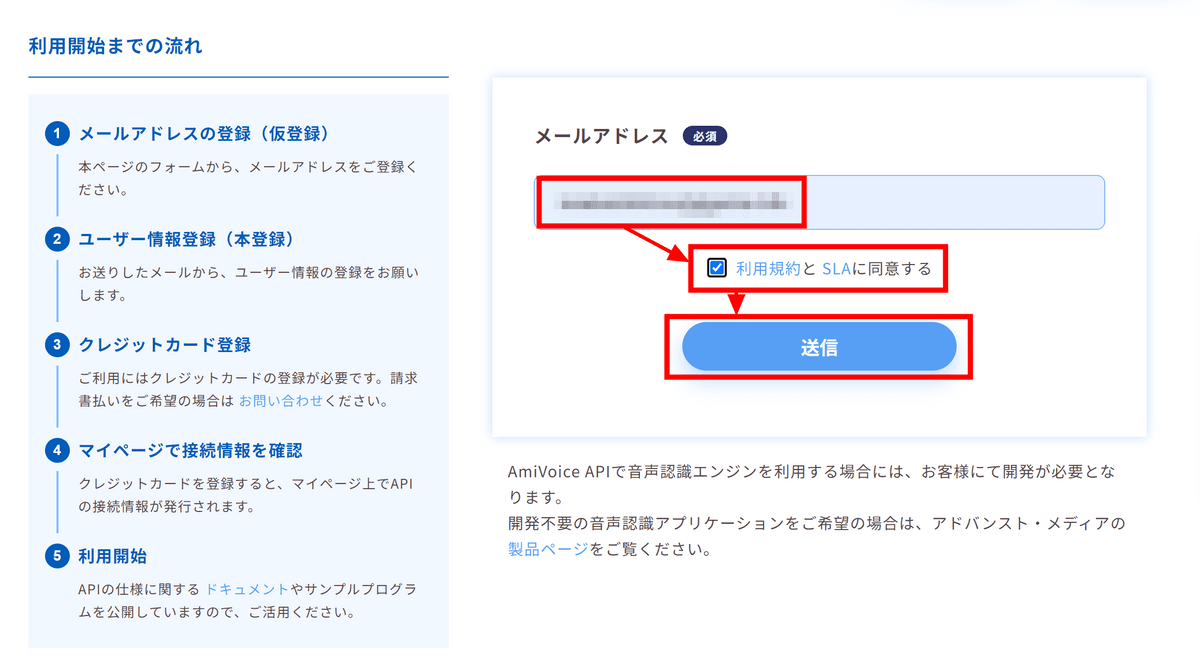
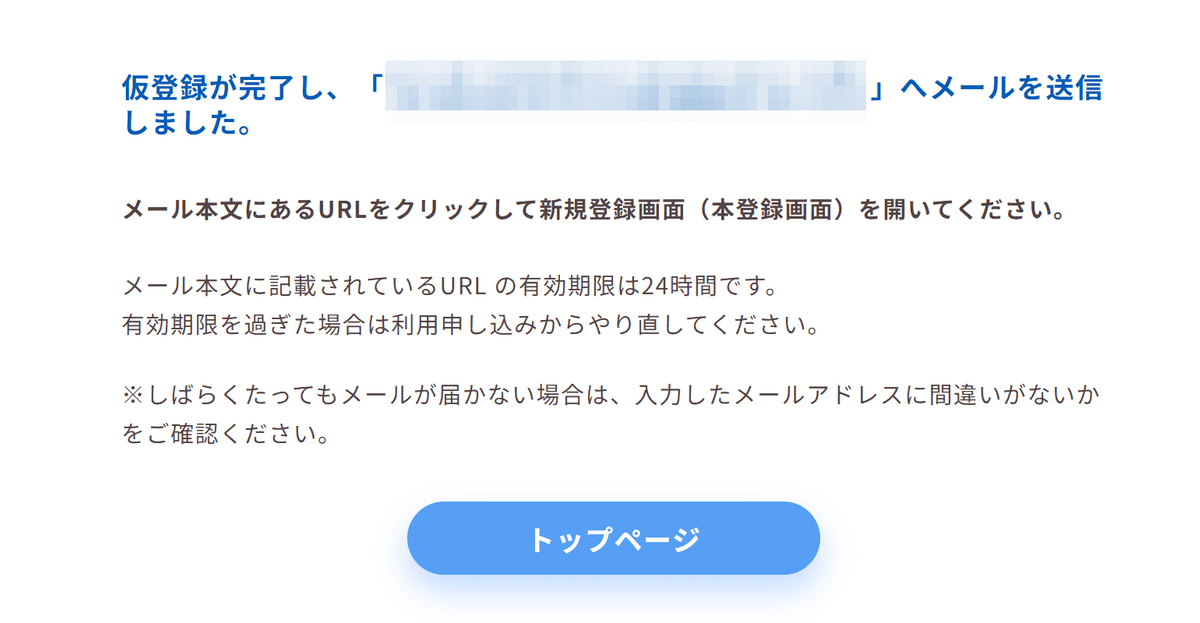
メールを確認するように指示されました。
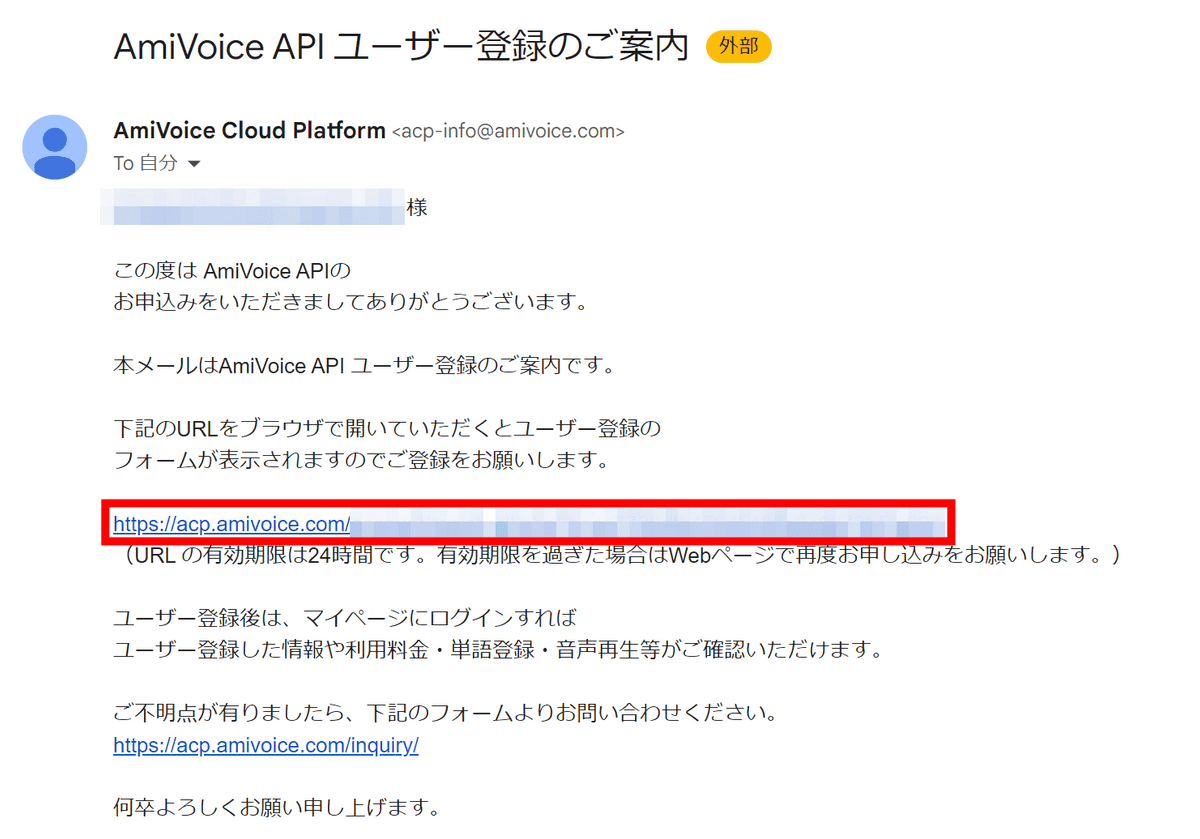
メールでユーザー登録用のURLが届いているので、URLをブラウザで開きます。
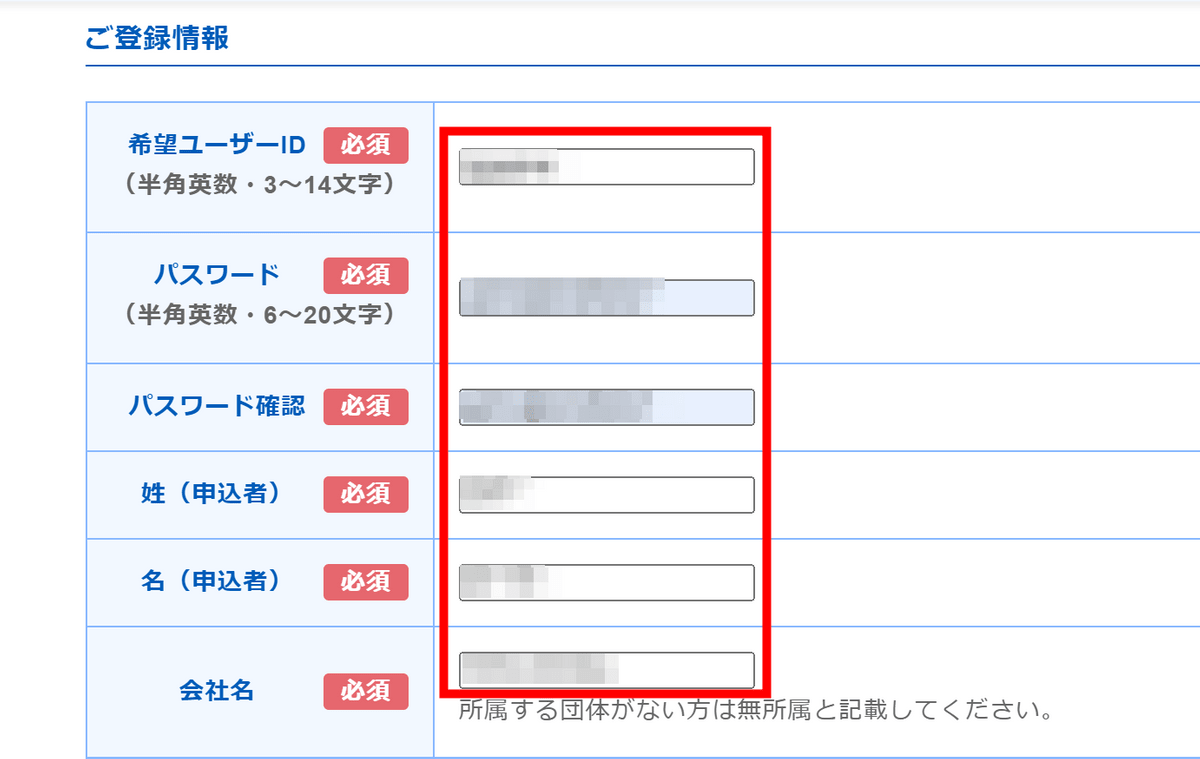
希望するユーザーIDやパスワード、氏名、会社名などの情報を入力していきます。
個人情報の取り扱いについて「同意する」にチェックを入れて「確認」をクリック。
入力した内容を確認します。
確認できたら最下部の「登録する」をクリック。
登録に成功しました。「ログインページ」をクリックして移動します。
登録したIDとパスワードを入力し、「ログイン」をクリック。
マイページの左にあるメニューから「プラン申込」をクリックします。無料でも多数の認識エンジンをそれぞれ60分まで利用することが可能ですが、利用にあたってクレジットカードの登録が必要なので、「登録はこちら」と書かれたリンクをクリック。
クレジットカード情報の取り扱いはGMOペイメントゲートウェイが行うため、いったんAmiVoiceのサイトを離れます。「移動する」をクリック。

クレジットカードの情報を入力して「この内容を保存」をクリック。
内容を確認して「保存する」をクリックします。
これで登録完了です。「マイページに戻る」をクリック。
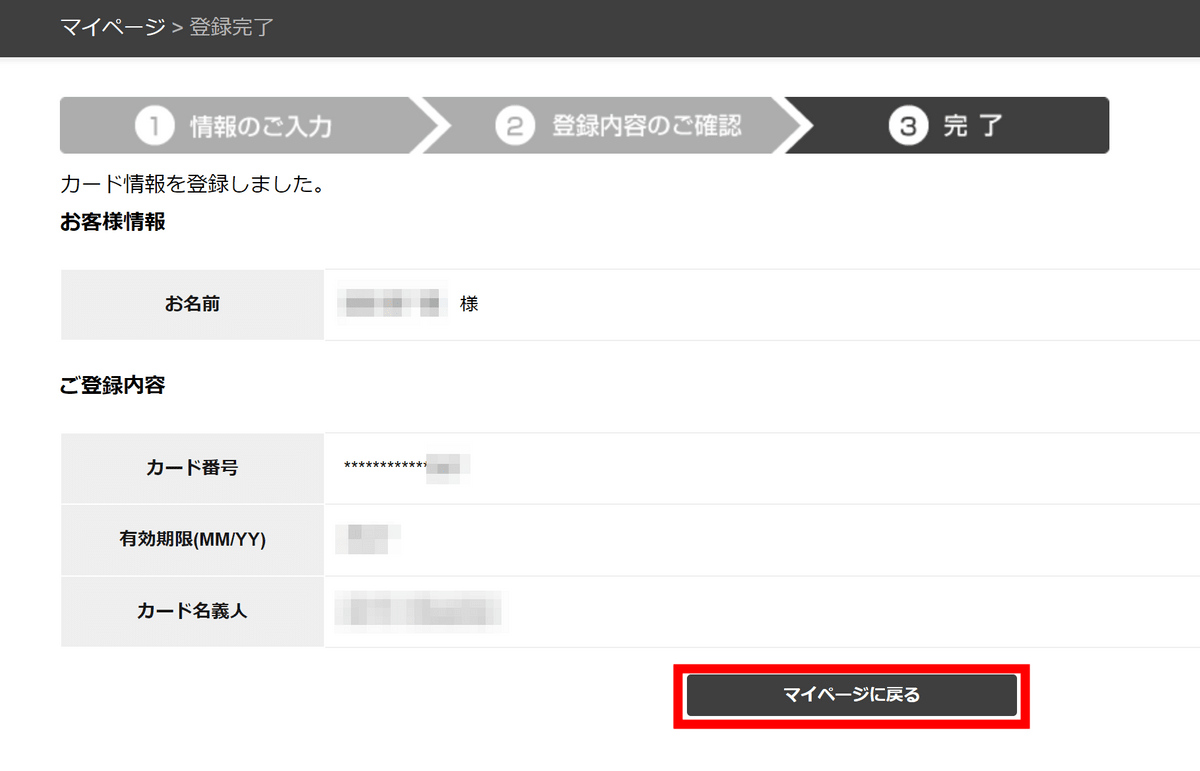
再び「プラン申込」のタブに移動すると、今度は下図のような画面になっています。今回、GIGAZINE読者向けに特別なクーポンが発行されているので、「クーポンを適用」をクリック。
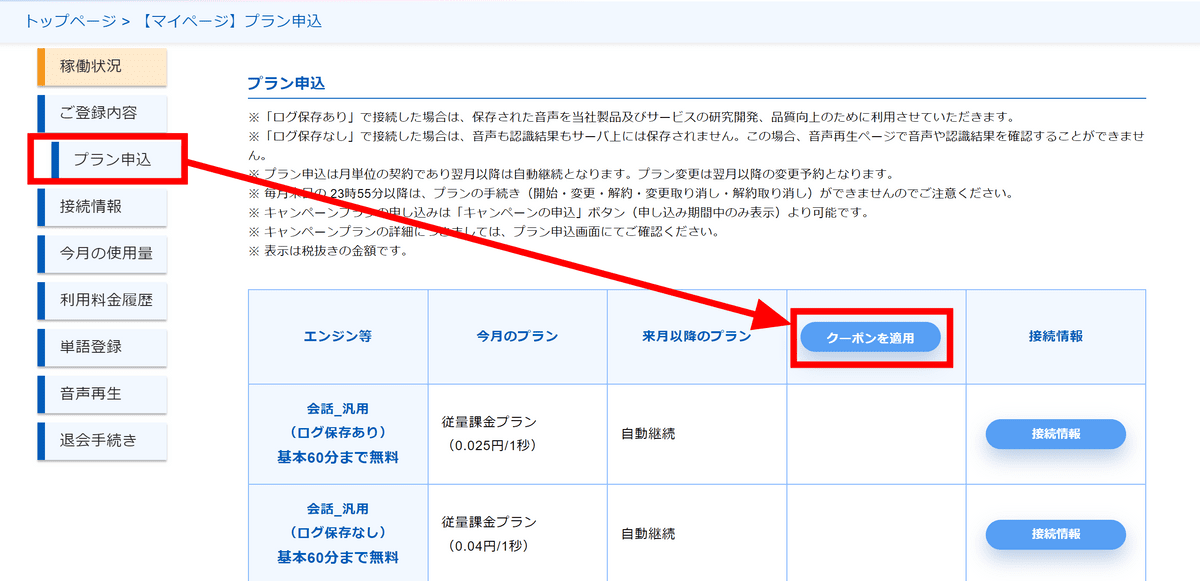
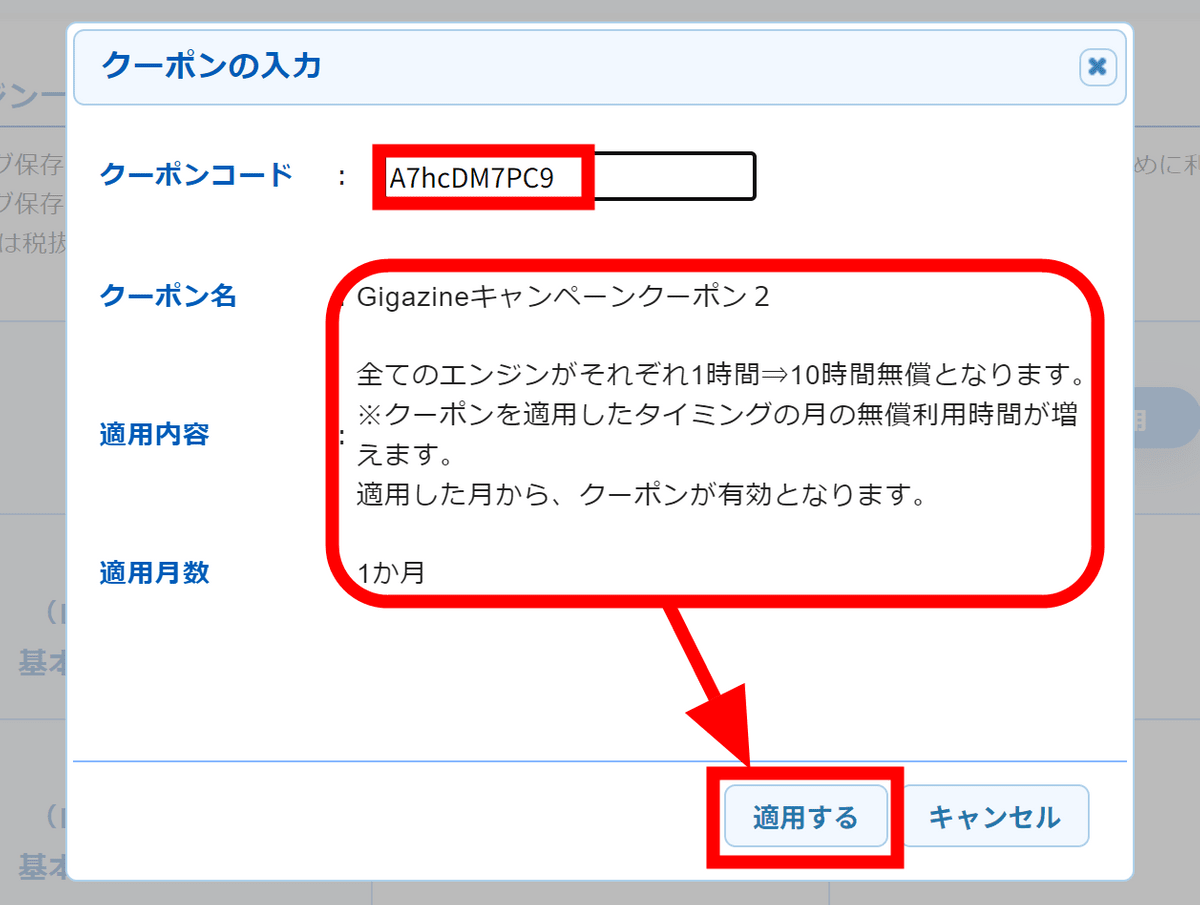
クーポンコード欄に「A7hcDM7PC9」と入力して「適用する」をクリックします。AmiVoiceにはエンジンが13種類あって、それぞれ、品質向上用にデータを保存する「ログ保存あり」版、データをサーバーに残さない「ログ保存なし」版が存在します。今回のクーポンは、各エンジンをそれぞれ10時間無料で利用できるようになるものなので、全エンジンのログ保存あり・なし版を合わせると合計で260時間利用できることになります。なお、クーポンは適用した月のみ有効で、入力期限は2024年12月末です。
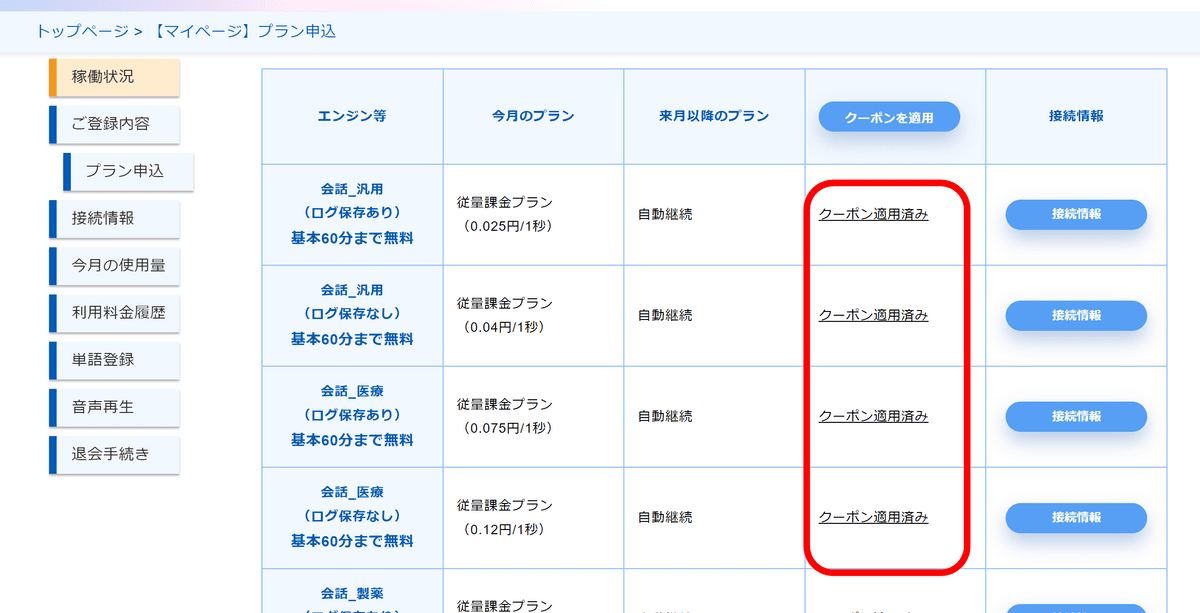
クーポンを適用するとそれぞれのエンジンの欄に「クーポン適用済み」と表示されました。これでAmiVoiceの準備は完了です。
◆AmiVoiceとElecterpreterを合体する
Electerpreterを終了し、下記のコマンドをGit Bashに入力してAmiVoiceのAPIクライアントライブラリーをダウンロードします。
cd ..
git clone https://github.com/advanced-media-inc/amivoice-api-client-library.git
explorer amivoice-api-client-library
cd Electerpreter
自動でAPIクライアントライブラリーのフォルダが開くので、「Wrp」フォルダの「javascript」にある「recorder.js」「result.js」「wrp.html」「wrp.js」の4つのファイルを「Electerpreter」の「src」内にコピー。
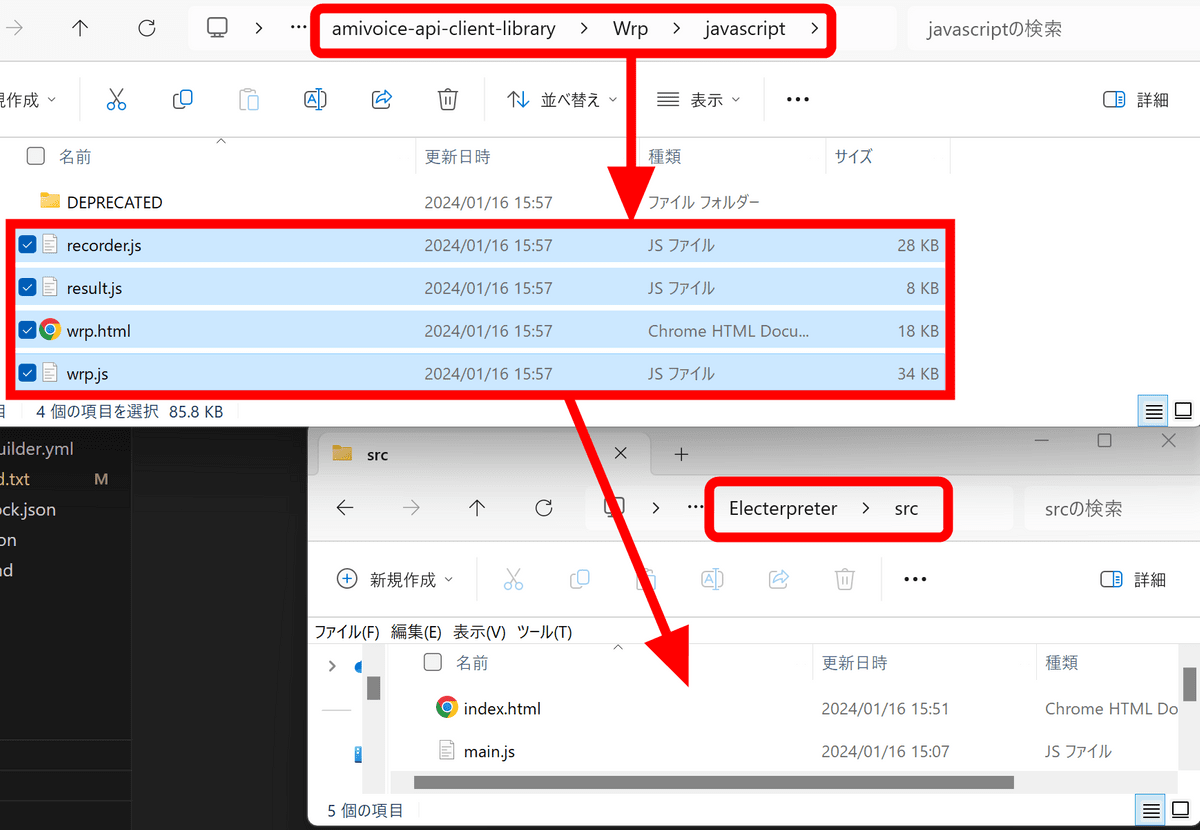
今回はAmiVoiceのデモにElecterpreterの中身を融合させ、テキストで指示を出す代わりに音声認識の結果を指示として入力します。「Electerpreter」の「src」内にある「index.html」の内容をwrp.htmlに反映するため、下図の通り6行目のスタイルシートをwrp.htmlのスタイル設定の上に挿入し、bodyの中身をwrp.htmlのbodyの終了直前部分にコピーします。
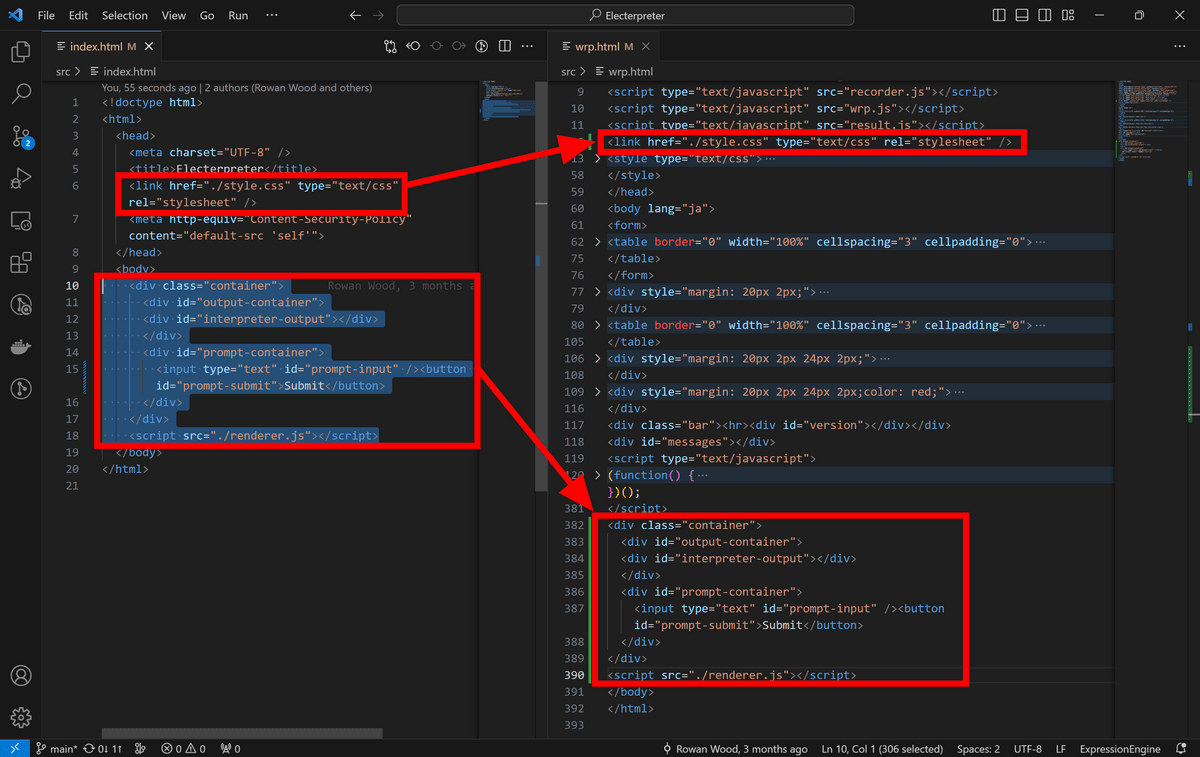
そして「index.html」を「index.html.old」など適当な名前に変更し、「wrp.html」を「index.html」という名前に変更。
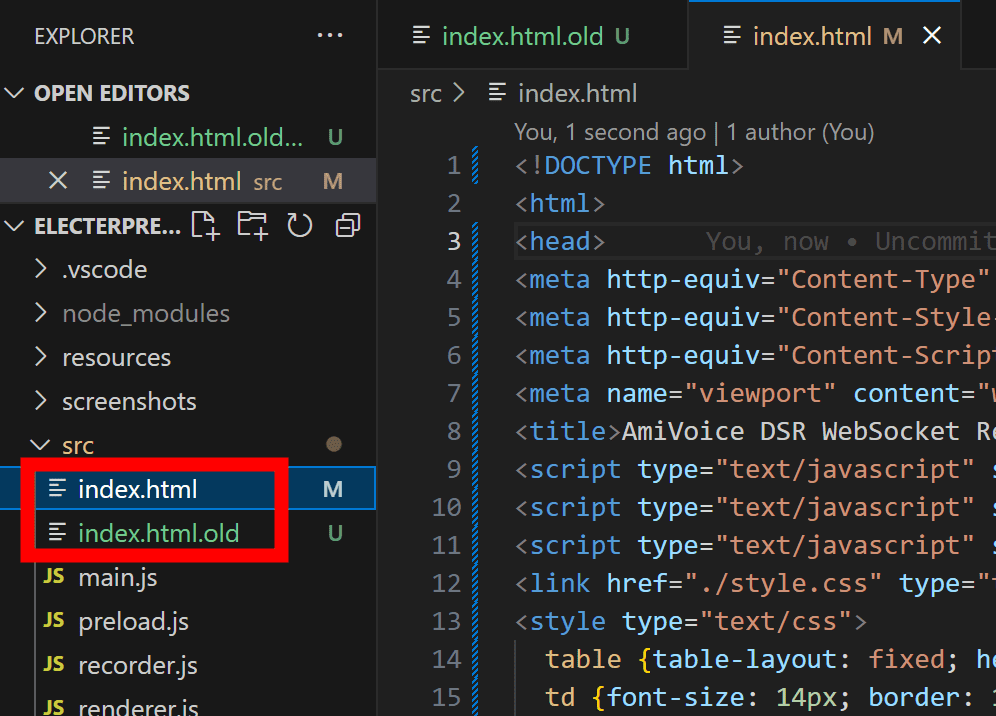
Git Bashで「npm run dev」を実行してElecterpreterを起動すると下図のようになりました。2つのスタイル設定が競合してかなり読みづらくなってしまいました。
ベースのスタイル設定をAmiVoiceの方にあわせるため、「style.css」の「#output-container」より上の部分を全て削除します。
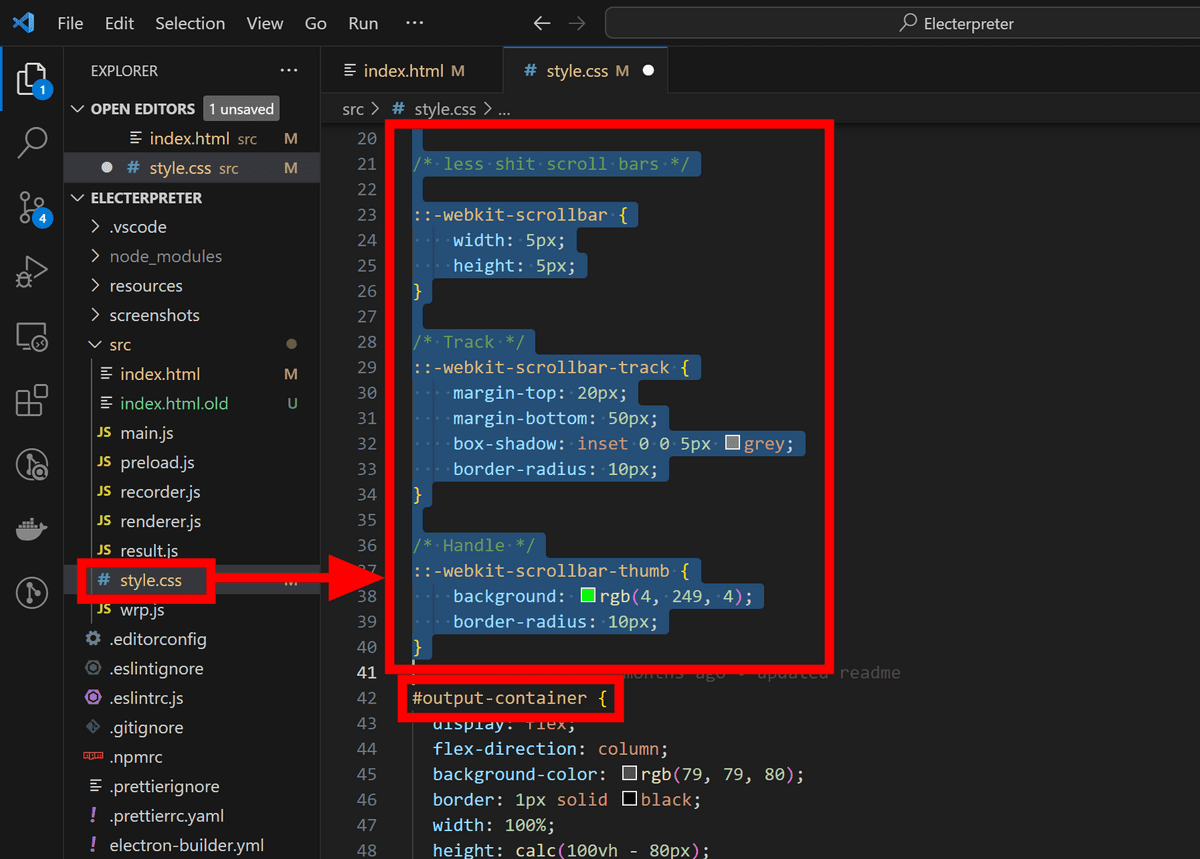
また、Electerpreterにもともと用意されていたテキスト入力欄は不要なため、「index.html」の「div id="prompt-container"」を中身ごと削除。

また、スペースを確保するためAmiVoiceの注意書きを削除します。
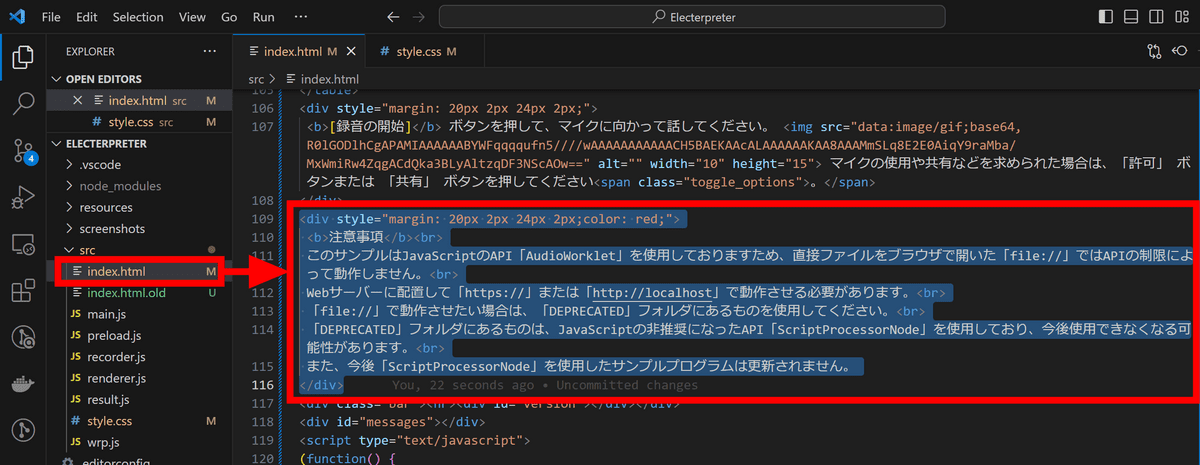
Electerpreterを再読込するとこんな感じの見た目になりました。

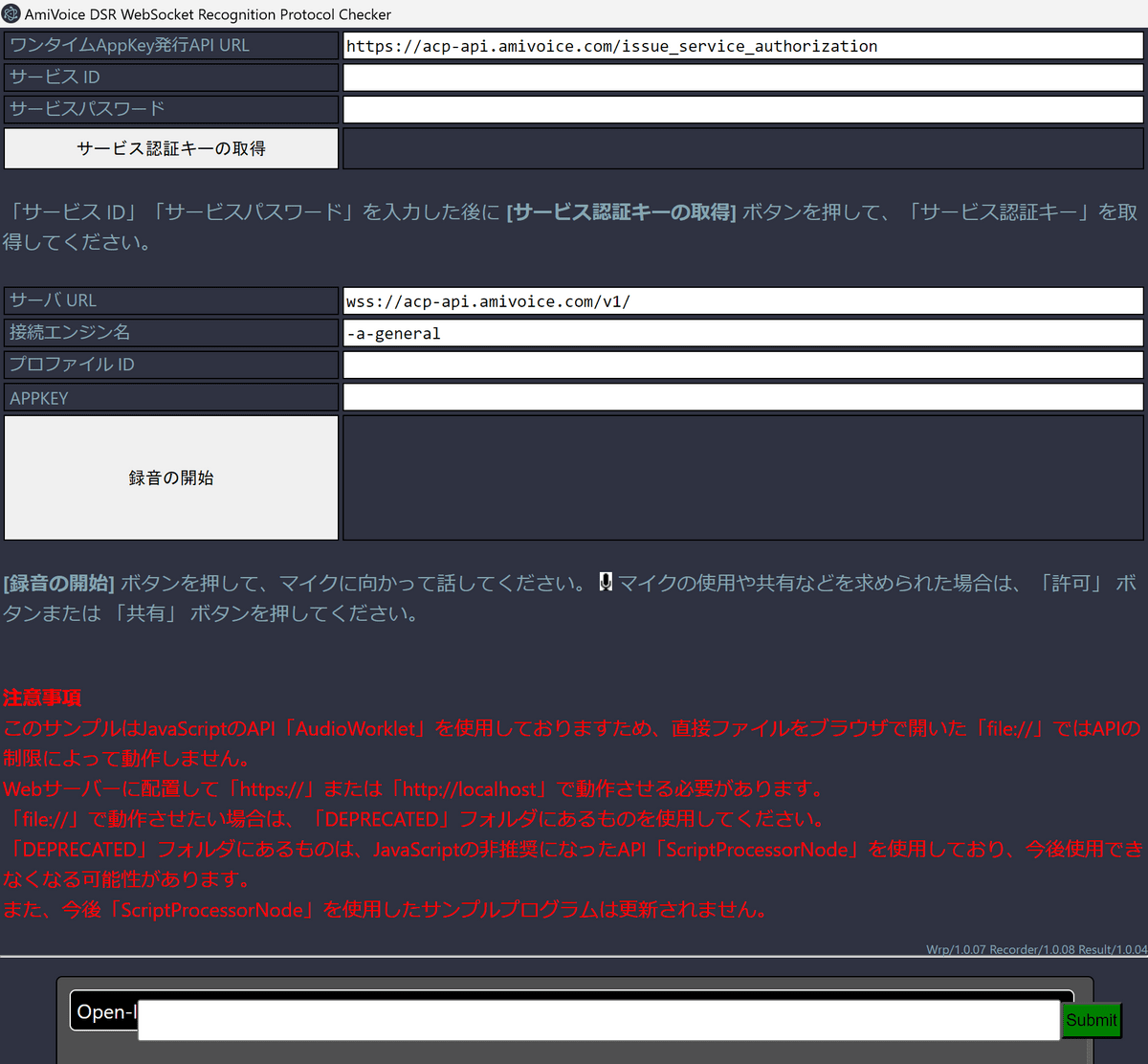
AmiVoiceの「接続情報」のページへ移動し、「サービスID」と「サービスパスワード」をコピーします。
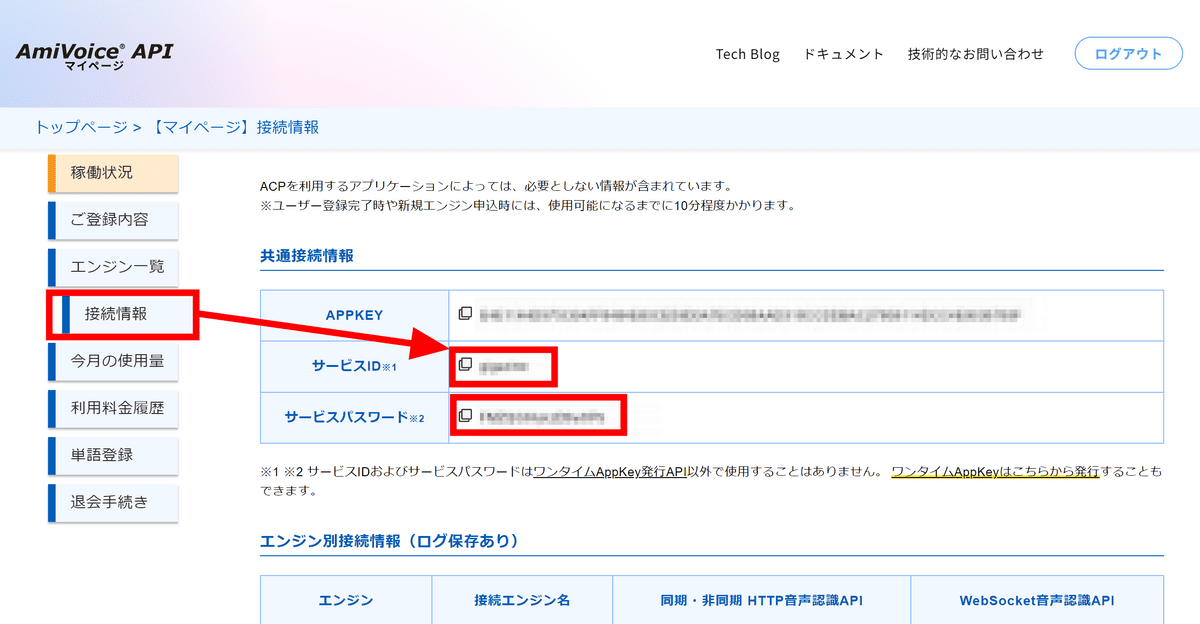
Electerpreterの「サービスID」「サービスパスワード」の欄にそれぞれ入力し、「サービス認証キーの取得」をクリックするとAPPKEYの欄にワンタイムAppKeyが取得されて入力されます。この状態で「録音の開始」を押せば音声認識が開始されるというわけ。なお、ワンタイムAppKeyの有効期限は発行から30秒のようなので「サービス認証キーの取得」をクリックしてから早めに録音を開始する必要があります。
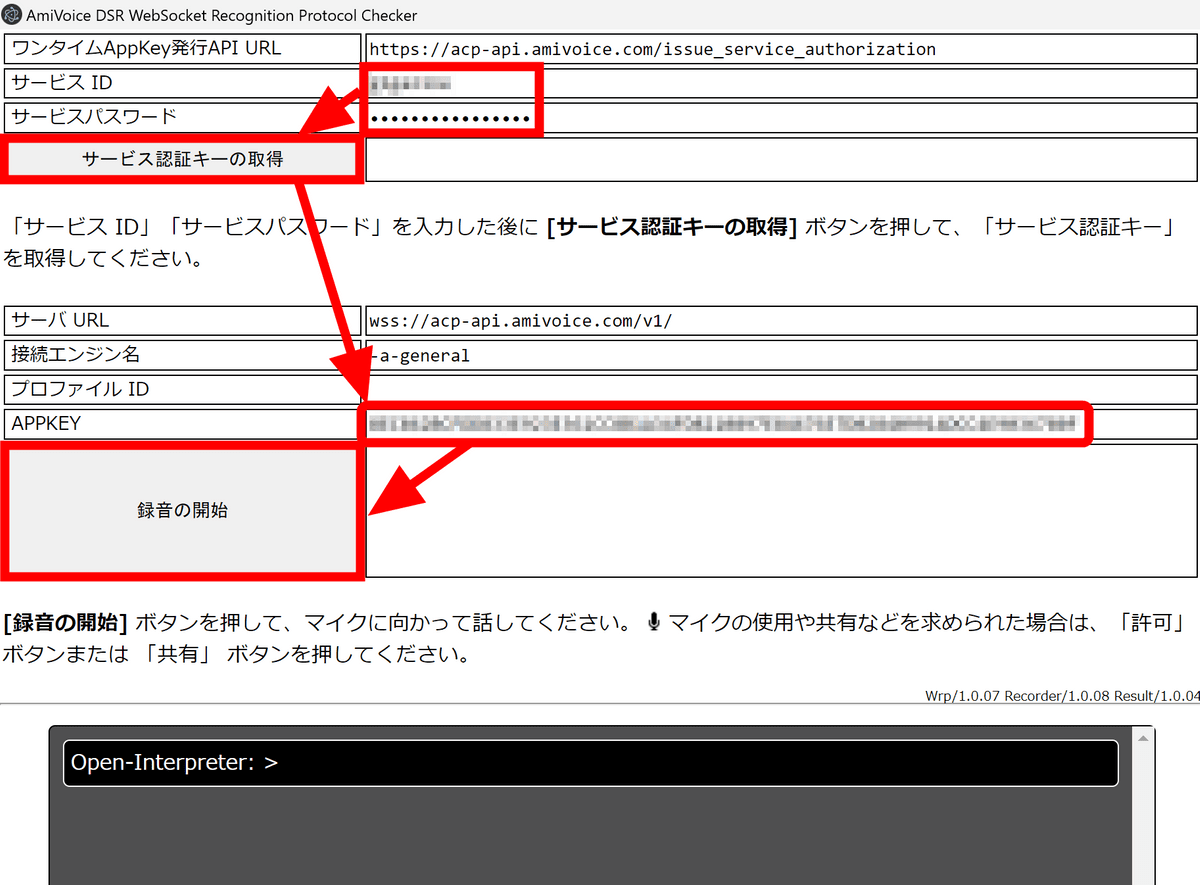
試しに「マイクのテストです」と話してみると下図の通り問題なく認識されました。ただし、ログが下部に出力されるためOpen Interpreterの出力欄が見えなくなってしまいます。
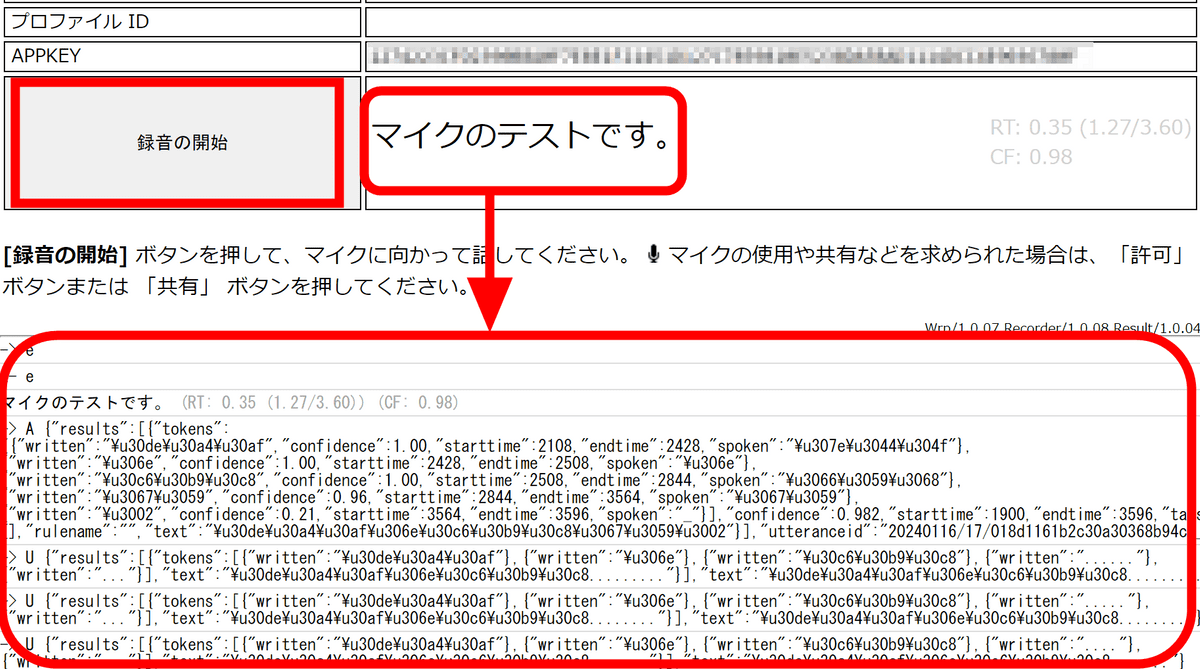
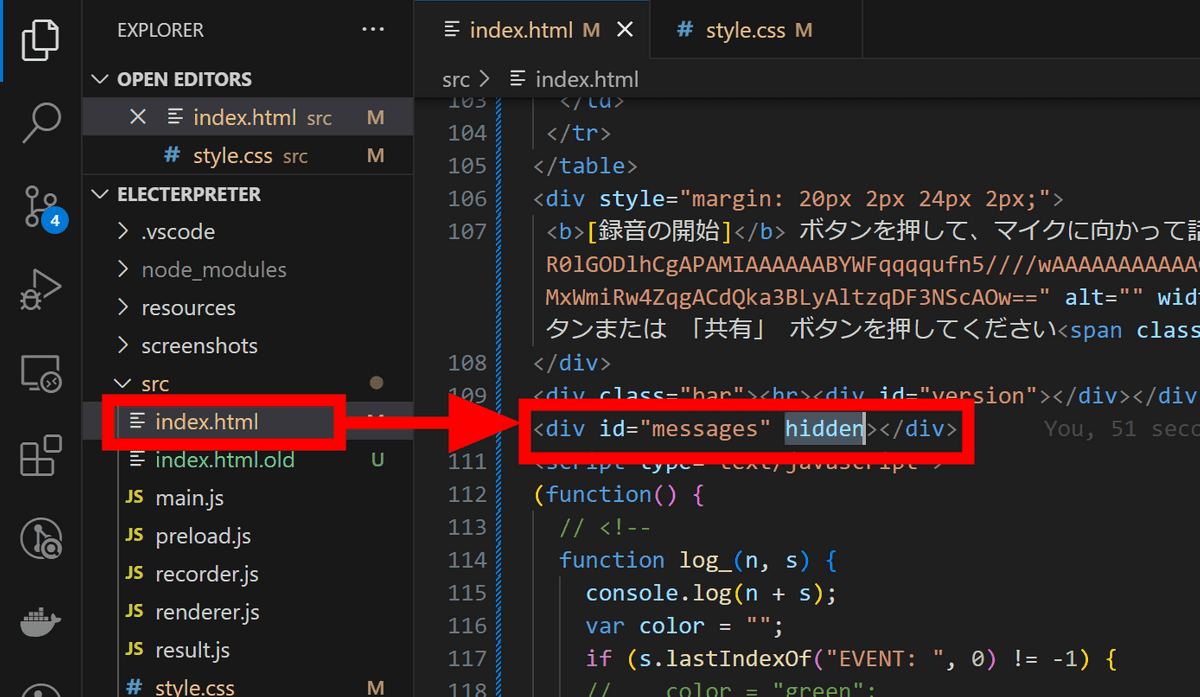
そこで、index.htmlの「<div id="messages">」に「hidden」属性を付与して非表示にしました。ログはこのエリアだけでなく、開発者ツールのコンソールにも出力されているようなので今後はコンソールで確認します。
◆音声でAIに指示してコードを生成・実行させる
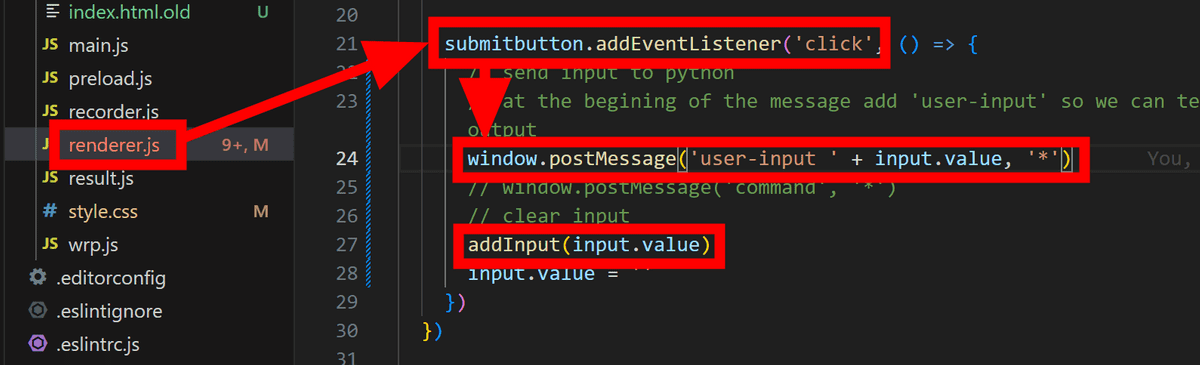
続いて認識の成功後にOpen Interpreterに指示文を入力するためのコードを書いていきます。「renderer.js」の中を見ると「送信ボタンをクリックしたときの動作」が書かれており、そこを確認すると「window.postMessage()」と「addInput()」という関数が呼ばれています。
「addInput()」の中身は同じファイルの下部に書かれていました。「outputcontent」という要素に入力文を表示させているようです。
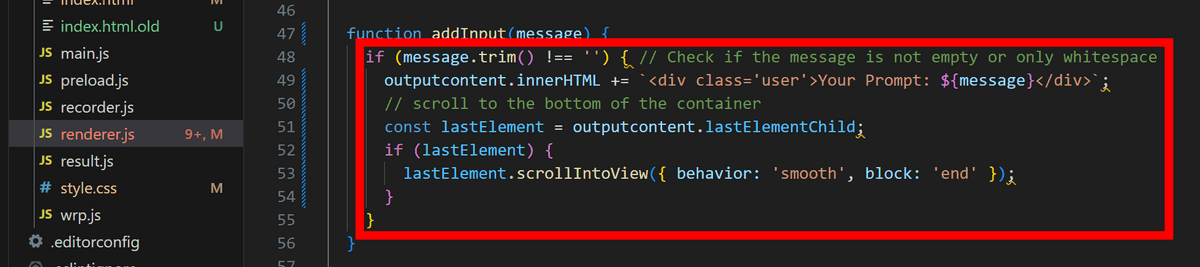
「outputcontent」の宣言も同じファイルの上の方で行われています。今回はテキストボックスや送信ボタンを削除したので、「outputcontent」の下に書かれているテキストボックスや送信ボタンに紐付いている処理を全て削除しました。
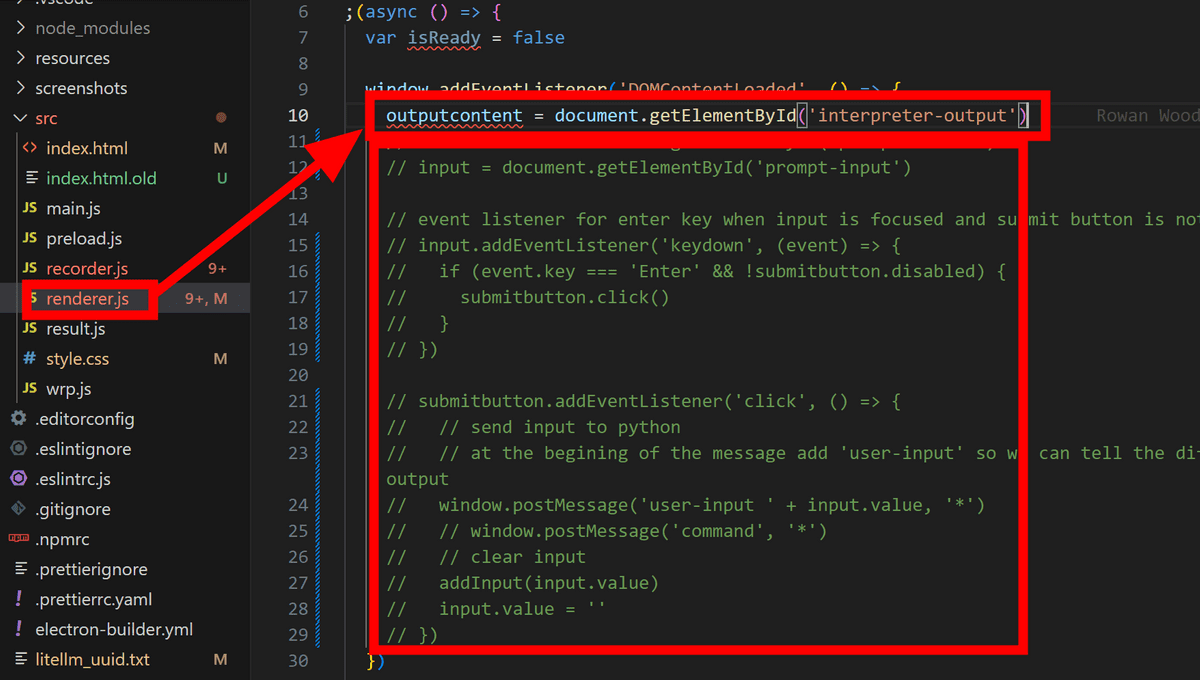
「index.html」の「認識処理が確定したときに呼び出されます」と書かれている関数の最下部に「window.postMessage()」と「addInput()」の中身を貼り付けます。また、認識結果は「result.text」という変数に入っているので貼り付けた中身の変数名をあわせておきます。
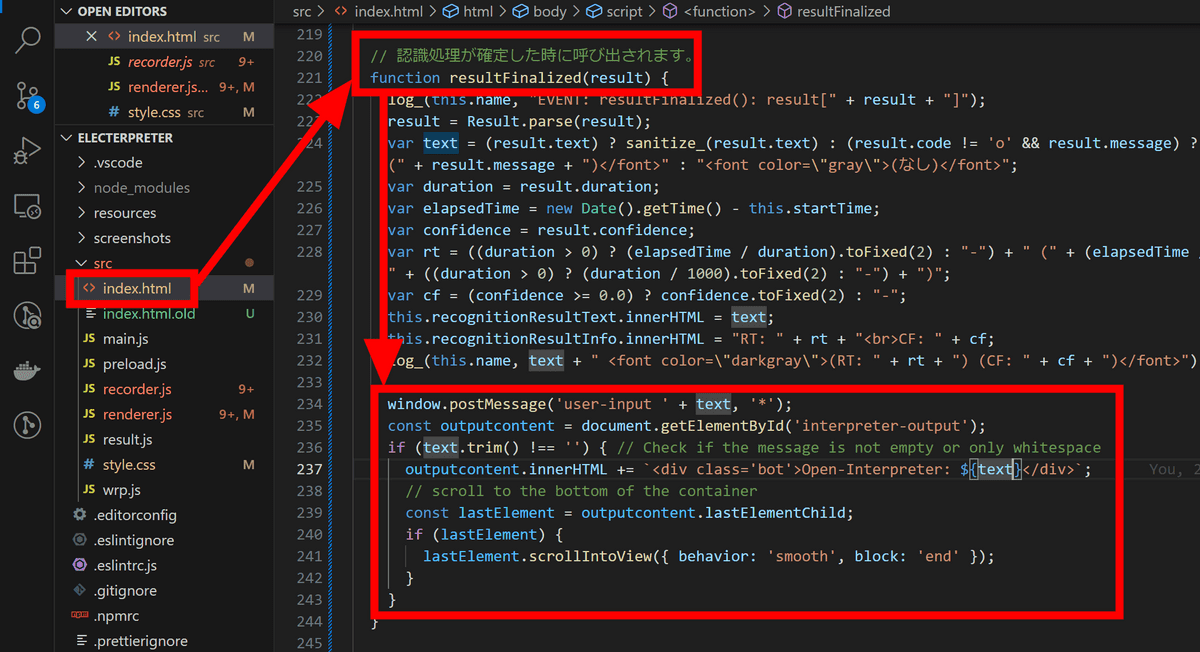
録音ボタンをオンにし、「Googleの株価をグラフにしてください」と話すとOpen Interpreterに話した内容が入力され、実行が開始されます。
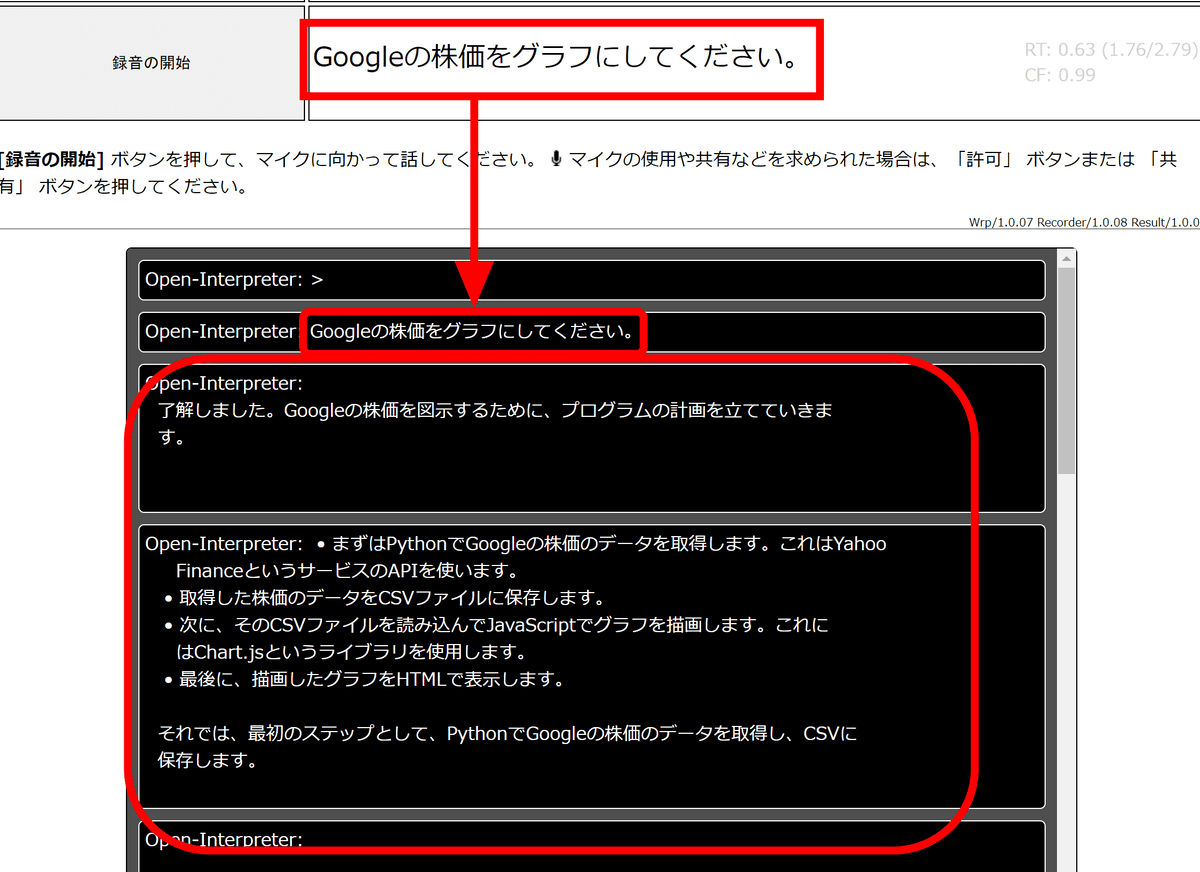
最初のコードはエラーが出ますがOpen Interpreterが自動で修正して再度実行していきます。
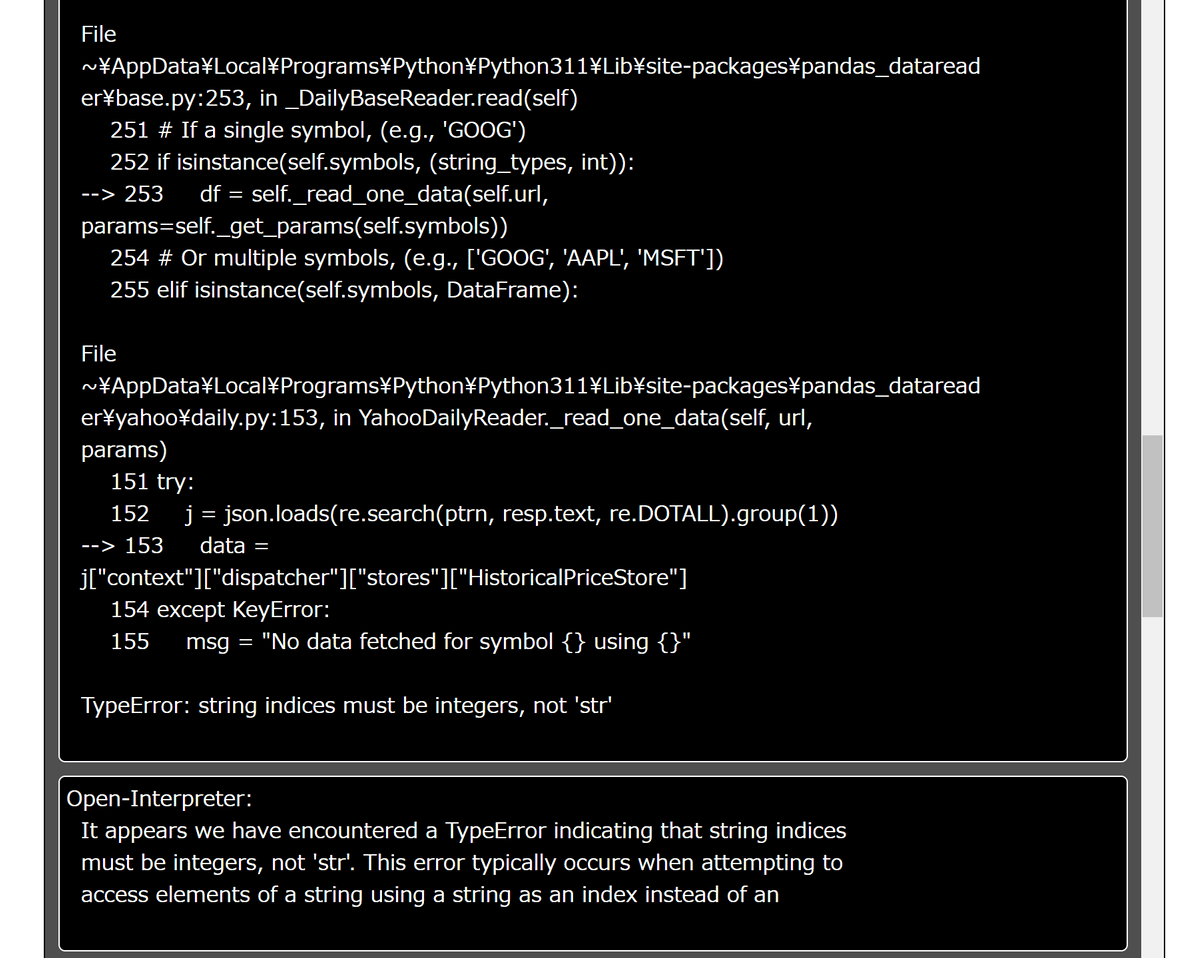
Googleの株価を頼んだはずなのですが、途中のコードでなぜかAppleの2000年1月1日からのデータをダウンロードしていました。
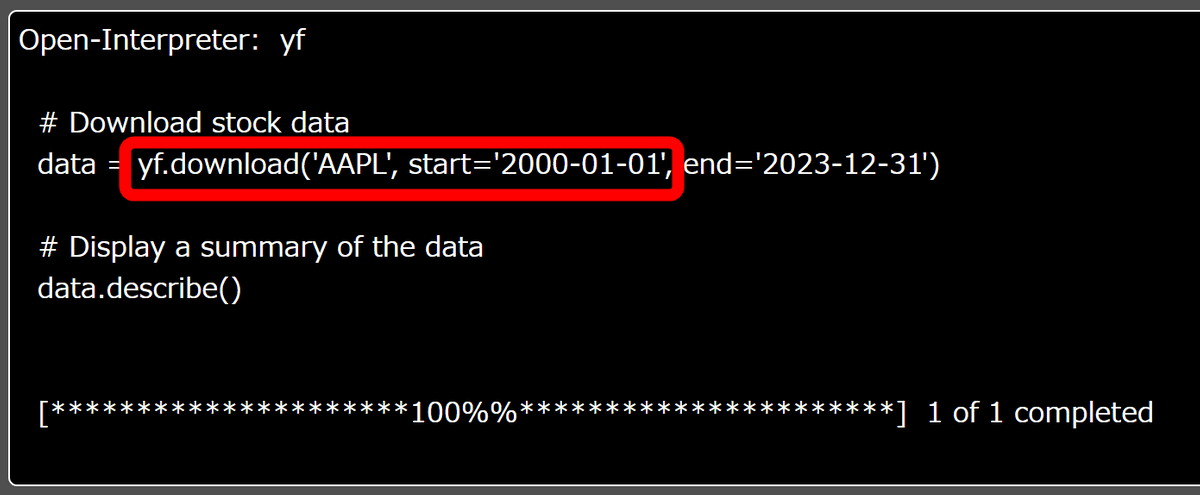
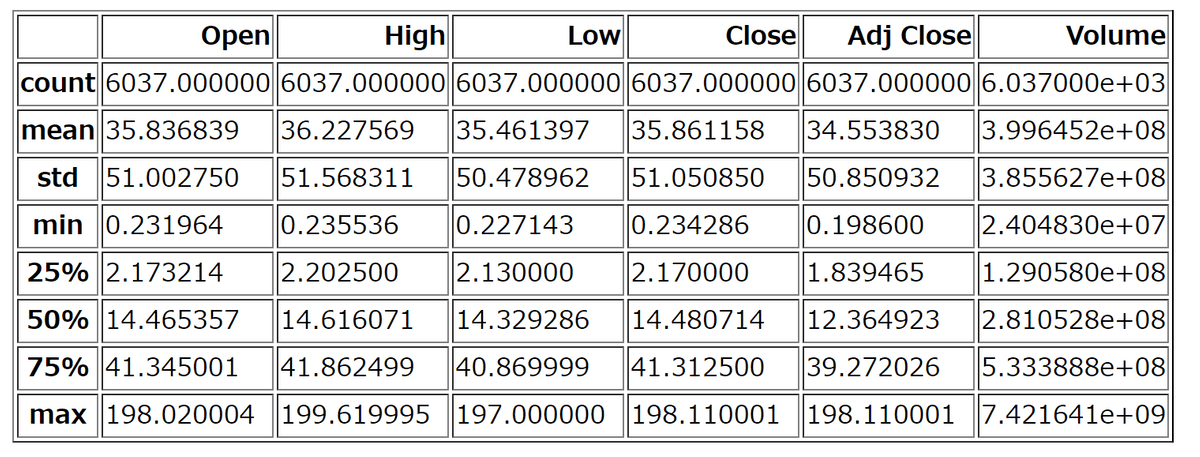
そして出力結果は下図の通り。グラフを頼んだはずが表になってしまっています。
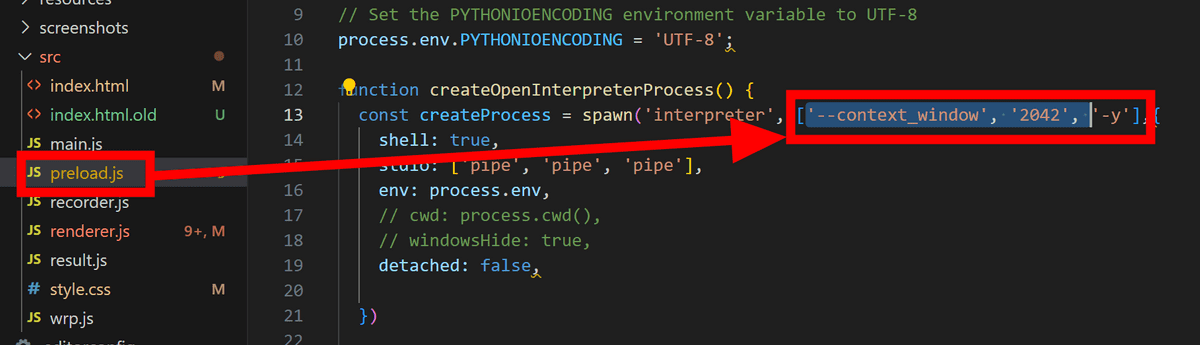
「preload.js」のOpen Interpreterの引数を設定している部分を確認するとコンテキストの長さが2042トークンに制限されていました。コンテキストが長くなりすぎて最初の情報が抜け落ちてしまったようなので、コンテキストを制限している部分を削除します。
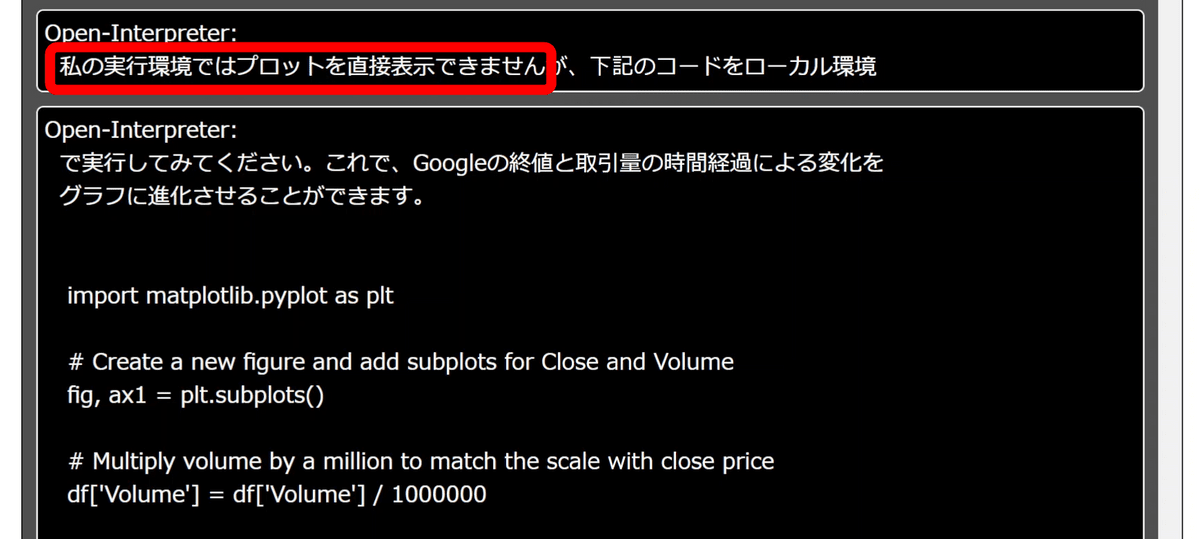
改めて実行してみると「私の実行環境ではプロットを直接表示できません」とメッセージが出ました。Electron経由でOpen Interpreterを呼び出しているためこうした制限が発生してしまったようです。
代わりに「タイマー機能付きのウェブアプリを作ってください」と頼んでみました。実際に動作する様子を動画で記録してみたので、実行速度などがどれぐらいか見て確認できます。
AmiVoiceとOpen Interpreterを使って口頭指示だけでAIにプログラミングさせてみた - YouTube
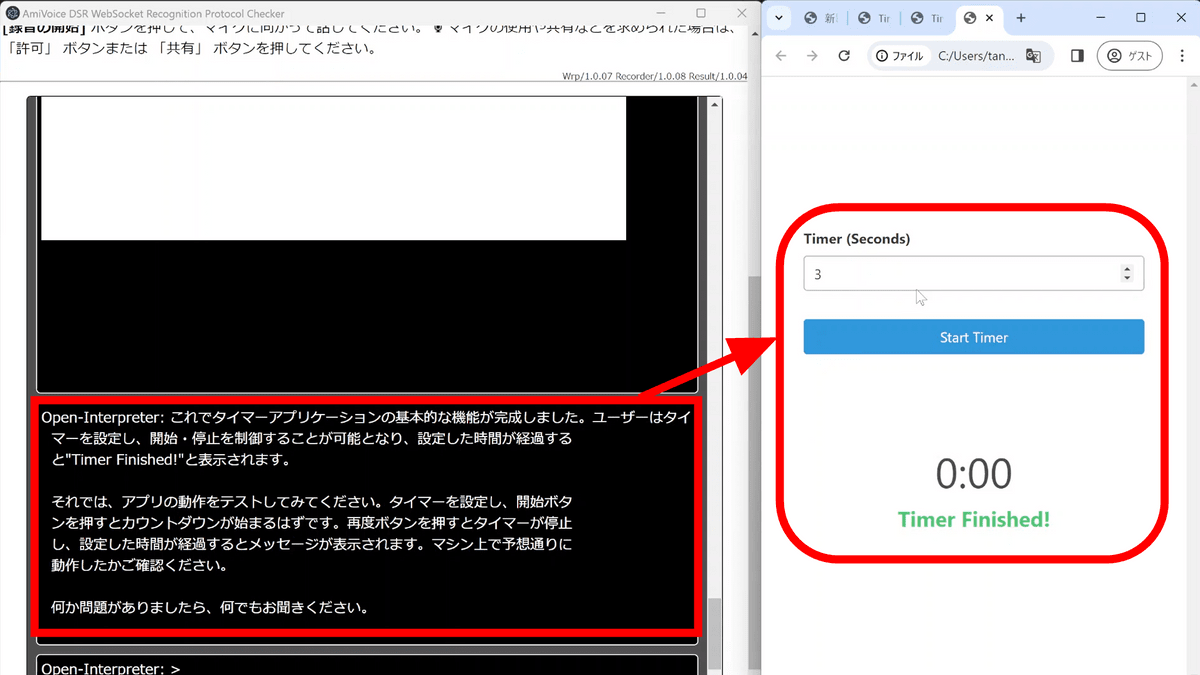
機能を追加するたびにウェブアプリが開くようで何回かフェイントをもらいましたが、無事アプリが完成して出力されました。見た目もいい感じに仕上がっており、こうしたアプリが一言頼んで待っているだけで出力されるのは驚きです。
今回は音声認識エンジンにAmiVoiceを使用しました。AmiVoiceは日本の会社が作成した日本語を得意とする音声認識エンジンで、AmiVoice APIクライアントライブラリのコードをそのまま流用するだけで簡単に使い始められるほか、汎用・医療用・金融用など26個の音声認識エンジンをそれぞれ毎月60分まで無料で利用可能なので、アプリに音声認識を組み込みたいと考えている場合はトライしてみてください。
なお、クーポンコード欄に「A7hcDM7PC9」と入力すると60分ではなく10時間分利用が無料になります。クーポンは適用した月のみ有効で、入力期限は2024年12月末となっています。
AI音声認識のAPI・SDKなら-AmiVoice Cloud Platform(アミボイス)
https://acp.amivoice.com/
AmiVoice API 利用申し込み
https://acp.amivoice.com/amivoice_api/regist/
・関連コンテンツ