




Instagramはどうやって3人のエンジニアで1400万人にサービスを提供できるシステムを組み上げたのか
Instagramは2010年10月にサービスを開始後、2011年12月までのわずか1年間で1400万人に利用されるほど巨大なサービスに成長しました。こうしたスケールに対応できるシステムを組み上げたのはたった3人のエンジニアだったとのことで、どのように少人数でスケールするシステムを組み上げたのかについて、エキスパートエンジニアのレオナルド・クリードさんが解説しています。
How Instagram scaled to 14 million users with only 3 engineers
https://engineercodex.substack.com/p/how-instagram-scaled-to-14-million
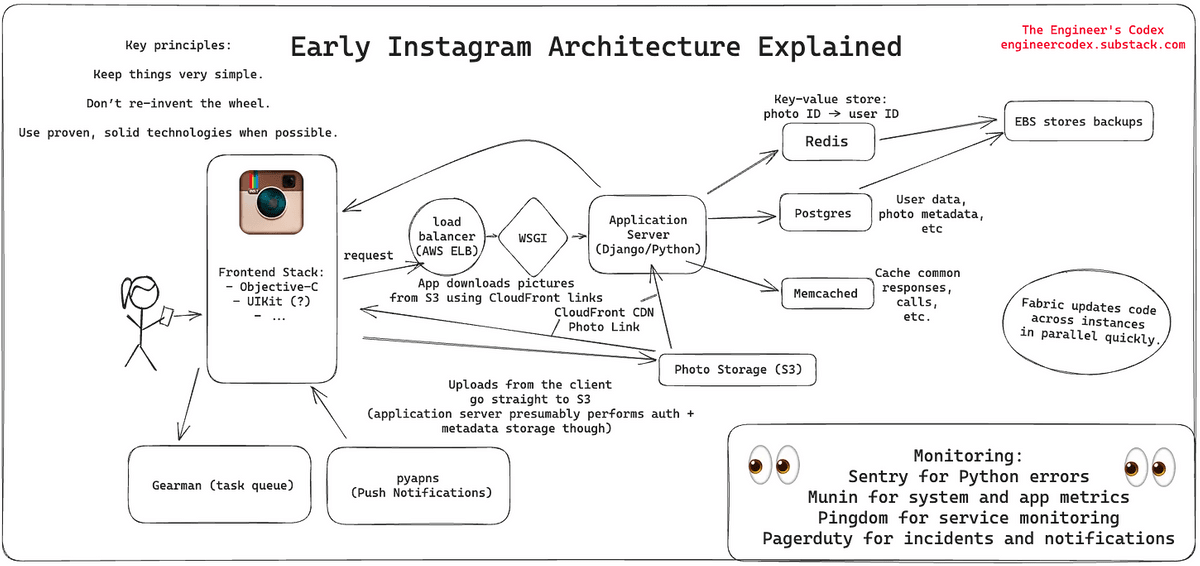
レオナルド・クリードさんは、Instagramが3人のエンジニアで安定して巨大なサービスを提供できた理由として、下記の3つの原則を守ったからだと述べています。
・物事を非常にシンプルにする
・車輪の再発明はしない
・できるだけ実績のある確かなテクノロジーを使用する
初期のInstagramのインフラストラクチャにはUbuntu Linuxが使用されており、Amazonが運営するクラウドサービスのAWS上のEC2で動作していました。一方、フロントエンド側は2010年にiOSアプリとしてリリースされました。Swiftが登場する2014年よりも前のリリースのため、フロントエンドはObjective-CとUIKitなどを利用して構築したのではないかとクリードさんは推測しています。
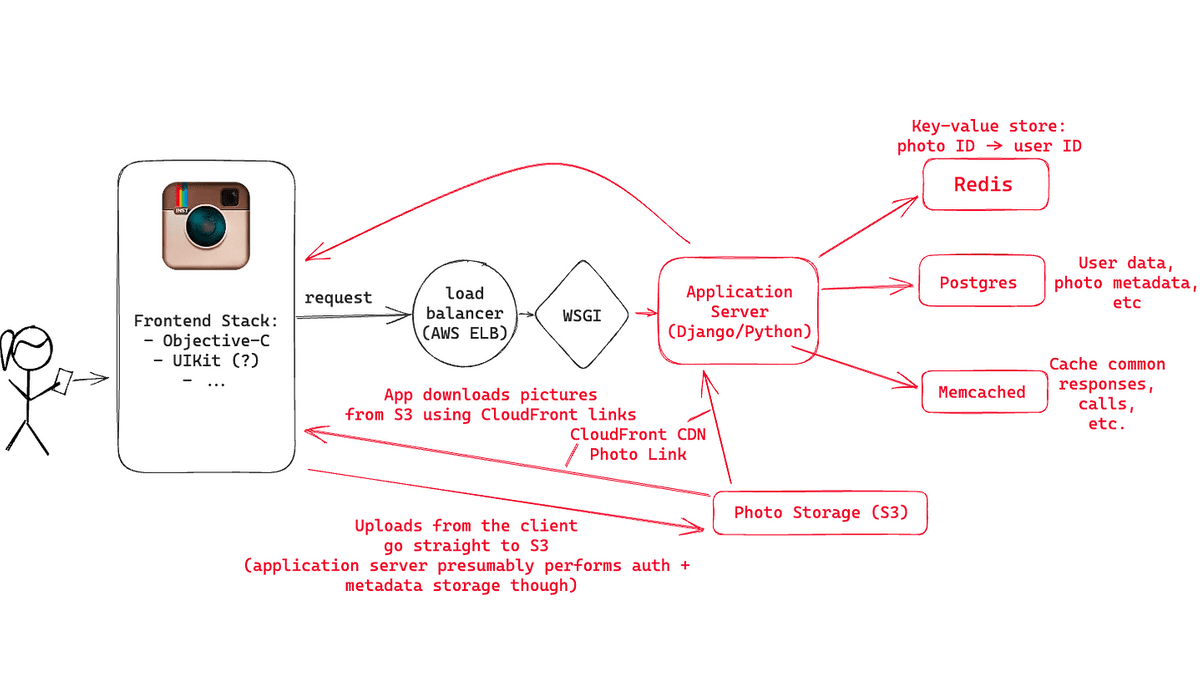
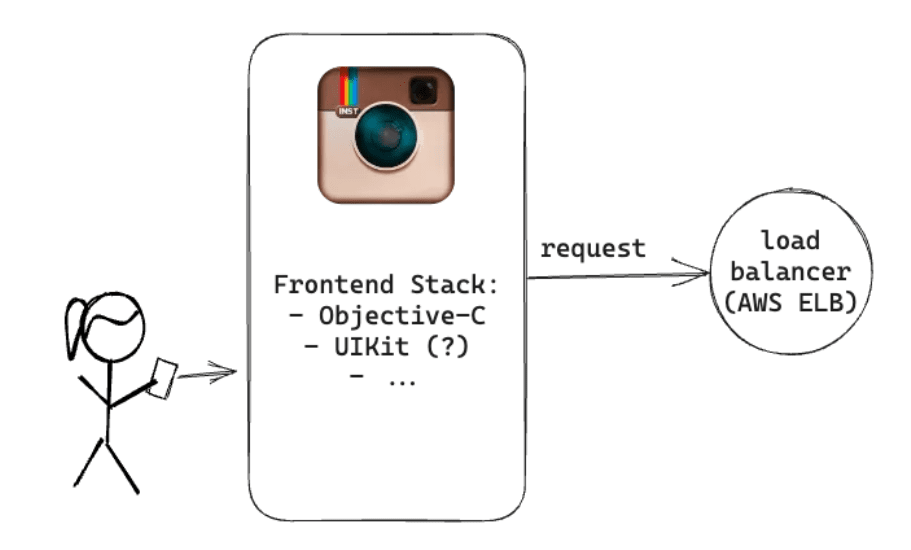
アプリからのリクエストはまずロードバランサーに届きます。Instagramのバックエンドには3つのNGINXインスタンスが設置してあり、稼働状況に応じてロードバランサーが適切なアプリケーションサーバーにリクエストを転送していました。
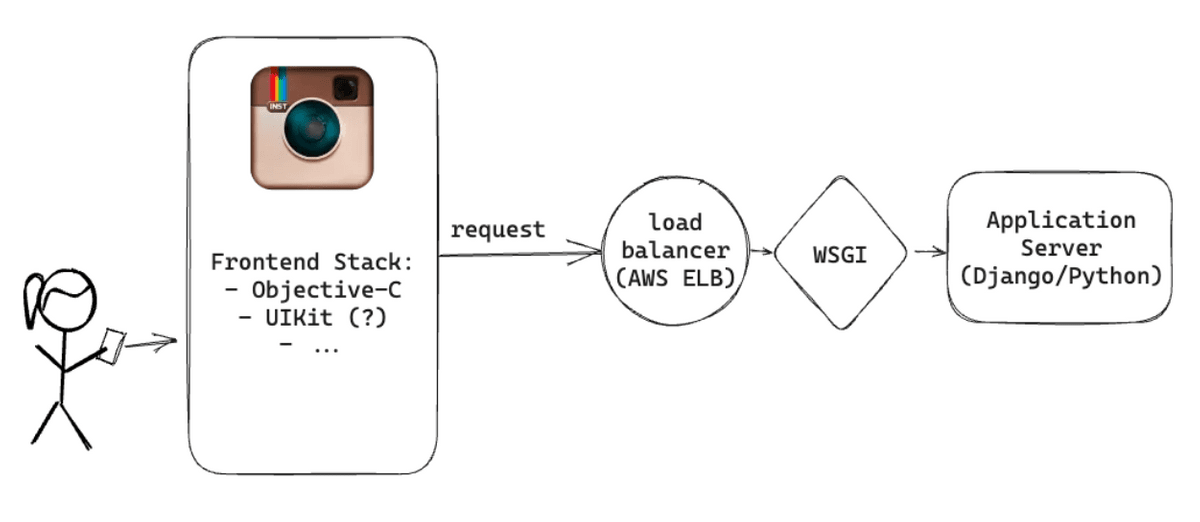
InstagramのアプリケーションサーバーはPythonのDjangoで記述されていたほか、WSGIサーバーとしてGunicornを使用していました。さらにFabricを利用することで同時に多くのインスタンスでコマンドを並列実行可能にし、コードのデプロイを高速化していたとのこと。
アプリケーションサーバーはAmazon High-CPU Extra-Largeマシンで稼働しており、25台以上設置されていました。サーバーがステートレスのため、リクエスト数が多い場合にはマシンを追加して対応することが可能でした。
アプリケーションサーバーがユーザーのメインフィードを生成する際、下記のデータが必要です。
・最新の関連する画像ID
・それらの画像IDに一致する実際の画像データ
・それらの画像に対応するユーザーデータ
これらのデータを収集してメインフィードのデータを生成するプロセスを高速化するため、Instagramではさまざまな手法が利用されていました。
◆Postgresデータベース
Postgresデータベースにはユーザーや写真のメタデータなど、Instagramのデータのほとんどが保存されており、PostgresとDjangoの間の接続では、PgBouncerを使用してコネクションプールが行われています。2012年時点でInstagramには1秒あたり25枚以上の写真と90件以上の「いいね!」が投稿されていたため、そのアクセス量に対応するため数千の「論理」シャードがいくつかの物理シャードにマッピングされていたとのこと。
インスタグラムは上記のアクセスをさばく上で、別の論理シャードでデータを処理した場合でも時間通りに並び替えることを可能にしたまま重複しないようなIDを生成する技術を生み出しました。Instagram公式の解説によると、IDは下記の内容で構成されています。
・ミリ秒単位の時間を41ビット
・論理シャードIDを表す13ビット
・自動インクリメントシーケンスの10ビット
これらを組み合わせることで、シャードそれぞれにおいて1ミリ秒ごとに1024個の重複しないIDを生成でき、かつ時間で並び替えられるようになっています。
◆画像ストレージ
画像のストレージにはAmazon S3を利用しており、何テラバイトものデータが保存されたとのこと。S3に保存されたデータはAmazon CloudFrontを通して配信されました。
◆キャッシュ
InstagramではRedisを使用して約3億枚の画像と投稿したユーザーとのマッピングを保存し、メインフィードやアクティビティフィードの画像を取得する際にどのPostgresシャードにアクセスすれば良いのかを取得していました。Redisは複数のサーバーでシャーディングされており、さらに全てのデータをメモリ上に保存することでアクセス速度を向上していたとのこと。ハッシュ化を駆使することで3億個のマッピングデータを5GBの領域に保存することが可能でした。
また、Djangoのキャッシュには6つのMemcachedインスタンスを利用していたとのこと。2013年には、毎秒数十億のリクエストを処理するためにMemcachedをどのように拡張したのかについての論文を発表しました。
こうしてユーザーがフォローしている人たちの最新の画像をフィードで閲覧することが可能になったというわけです。
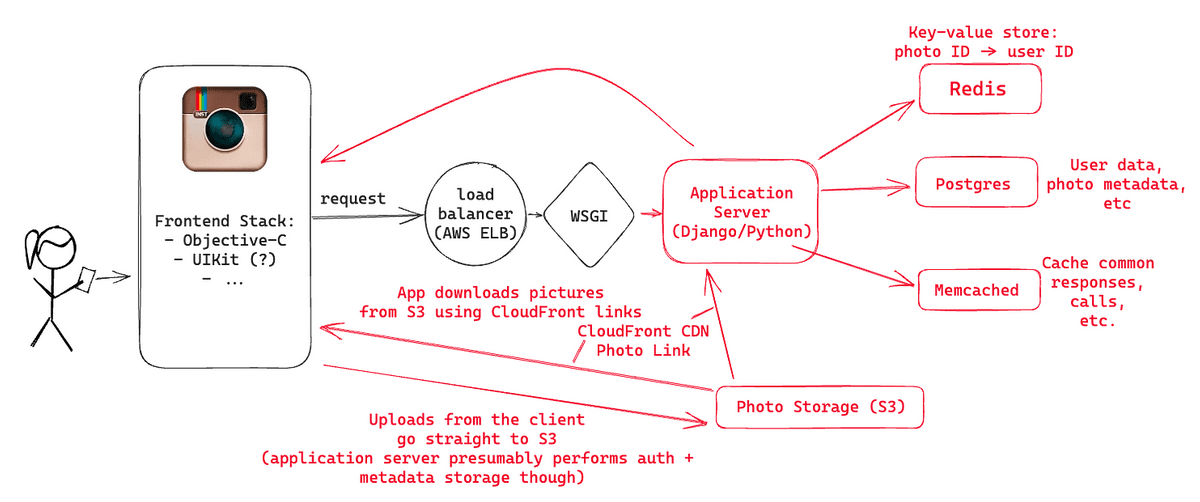
PostgresとRedisは両方マスターとレプリカのセットアップで実行されており、Amazon EBSスナップショットを利用してバックアップを頻繁に作成するようになっていたほか、バックエンドではGearmanを使用して作業を適切なマシンに振り分けるようになっており、フォロワー全員に新しい画像の投稿などのアクティビティを通知するなどの非同期タスクが振り分けられていました。
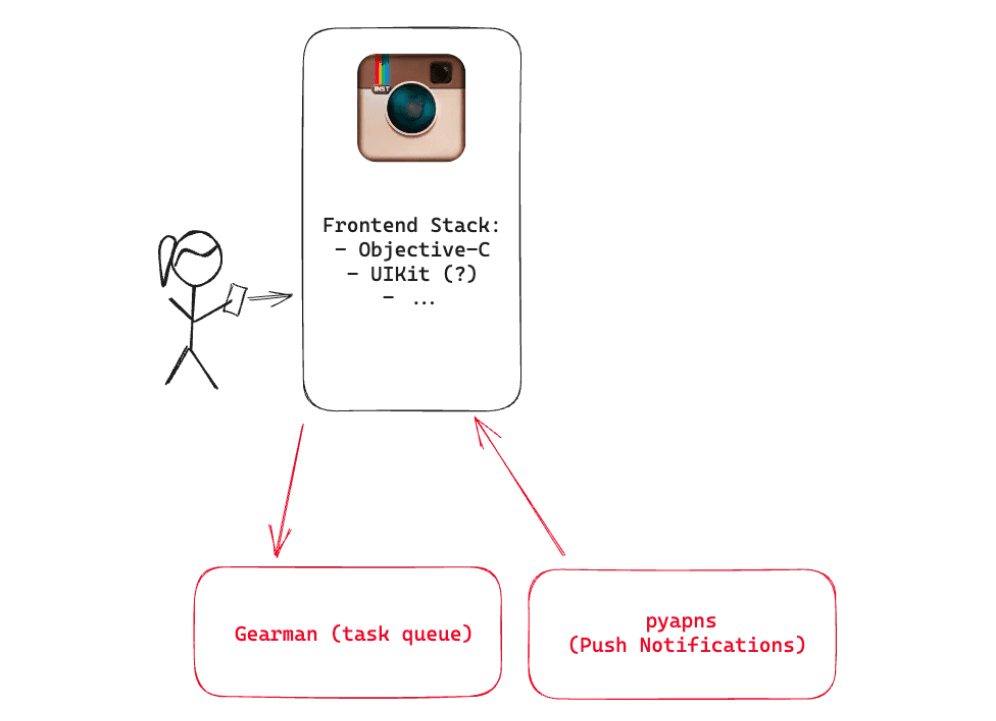
プッシュ通知についてはオープンソースのユニバーサルAppleプッシュ通知サービスプロバイダーのpyapnsを使用していました。
また、エラーの監視についてはオープンソースのSentryやMunin、Pingdomを使用していたとのこと。SentryはPythonエラーをリアルタイムで検知し、Muninはシステム全体の統計をグラフ化して異常を警告する役割がありました。Pingdomは外部からのサービスの監視に使用されていました。
こうした技術を活用することで、Instagramはたった3人のエンジニアで1400万人を支えるサービスを提供できたというわけです。
本記事に関連するフォーラムをGIGAZINE公式Discordサーバーに設置しました。誰でも自由に書き込めるので、どしどしコメントしてください!
• Discord | "少人数でサービスを完成させる秘訣を教えて!" | GIGAZINE(ギガジン)
https://discord.com/channels/1037961069903216680/1155796678721404938
・関連記事
Instagram投稿の表示基準やランク付けの仕組みを公式が解説 - GIGAZINE
世界中で20億人の月間アクティブユーザーを抱えるInstagramの規模がFacebookに迫りつつある - GIGAZINE
「Instagramの埋め込みは著作権侵害に当たらずInstagramはその責任を負わない」という判決が下る - GIGAZINE
Instagramに最初に投稿された写真は実際どれなのかがリバースエンジニアリングで判明 - GIGAZINE
容量たった2MBの軽量版「Instagram Lite」が世界170カ国で再始動、本家の15分の1という身軽さで広告なし - GIGAZINE
・関連コンテンツ







in ソフトウェア, ネットサービス, Posted by log1d_ts
You can read the machine translated English article How did Instagram create a system that c….