How did Instagram create a system that can serve 14 million people with three engineers?
After launching in October 2010, Instagram grew into a huge service that was used by 14 million people in just one year until December 2011. It was said that only three engineers assembled a system that could handle such scale, and expert engineer Leonard Creed explains how they assembled a system that scales with a small number of people.
How Instagram scaled to 14 million users with only 3 engineers
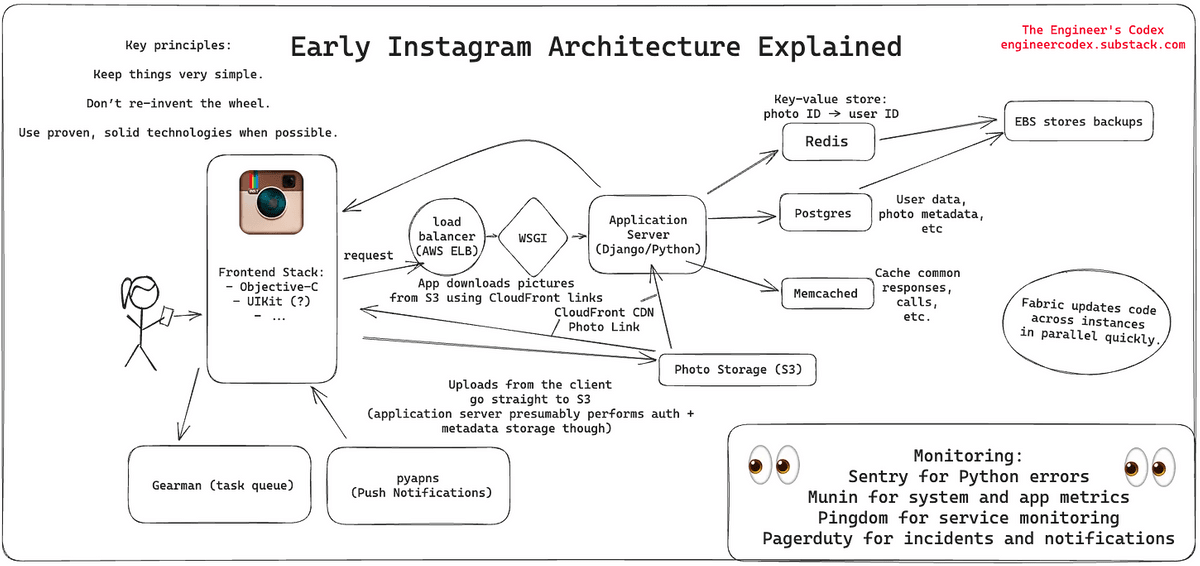
Leonard Creed says that the reason Instagram was able to provide a stable and huge service with just three engineers was because they adhered to the following three principles.
-Make things very simple
- Don't reinvent the wheel
・Use proven technology as much as possible
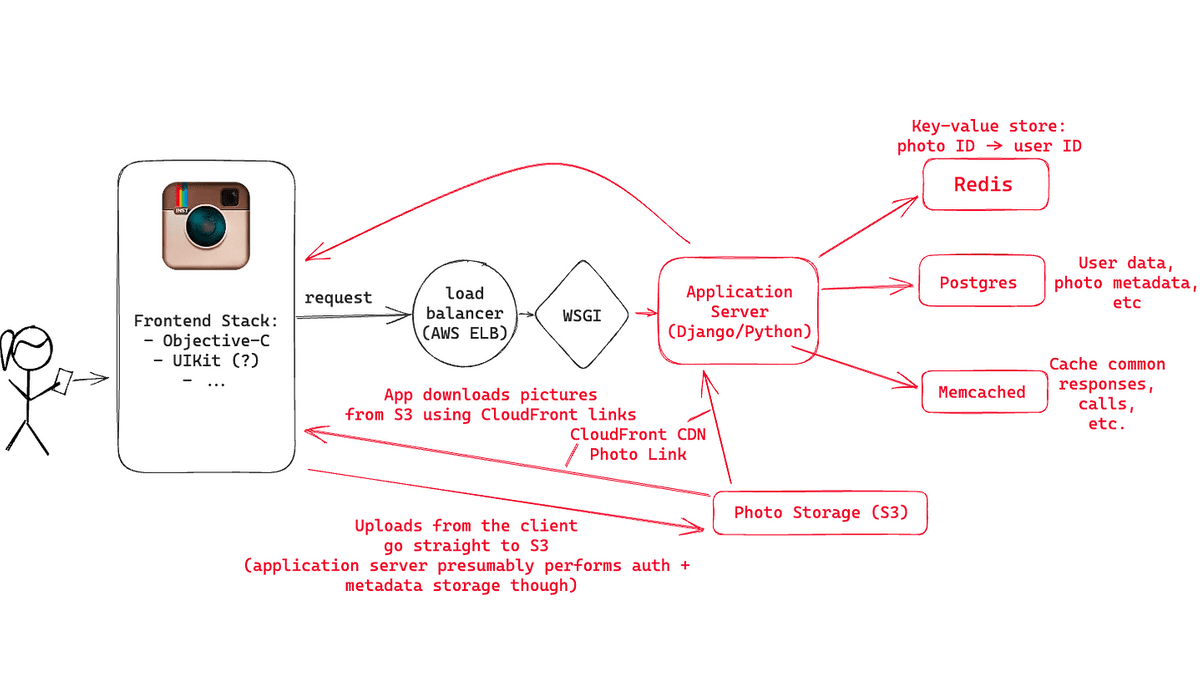
Initially, Instagram's infrastructure used Ubuntu Linux and ran on EC2 on AWS, a cloud service operated by Amazon. On the other hand, the front end side was released as an iOS app in 2010. Since it was released before Swift appeared in 2014, Creed suspects that the front end was built using Objective-C and UIKit.
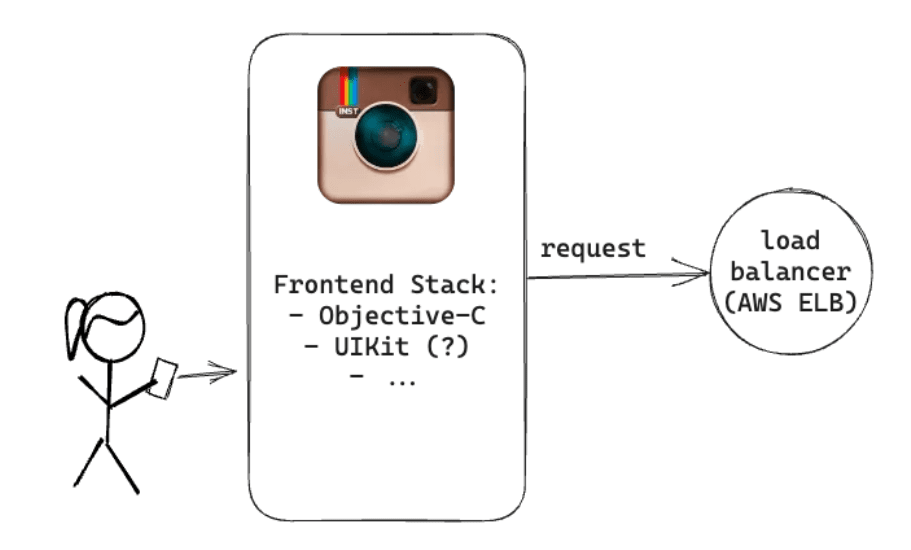
Requests from your app first reach the load balancer. Instagram's backend had three NGINX instances, and a load balancer forwarded requests to the appropriate application server depending on the operating status.
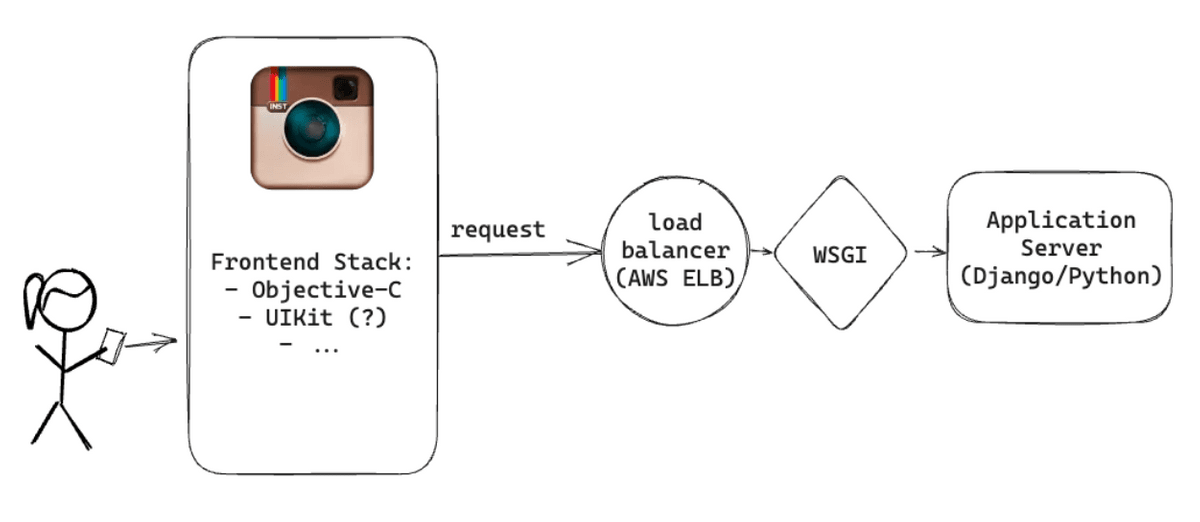
Instagram's application server was written in Python's Django and used
The application servers were running on Amazon High-CPU Extra-Large machines and had over 25 installed. Since the server was stateless, it was possible to add more machines to handle the large number of requests.
When the application server generates the user's main feed, it requires the following data:
・Latest related image ID
・Actual image data that matches those image IDs
・User data corresponding to those images
To speed up the process of collecting this data and generating data for the main feed, Instagram utilized a variety of techniques.
◆Postgres database
The Postgres database stores most of Instagram's data, including user and photo metadata, and connection pooling between Postgres and Django is done using
In order to handle the above access, Instagram has created a technology that generates unique IDs that can be sorted on time even when data is processed in different logical shards. According to Instagram's official explanation , the ID consists of the following contents.
・41 bits of time in milliseconds
・13 bits representing logical shard ID
・10 bits of auto-increment sequence
By combining these, each shard can generate 1024 unique IDs every 1 millisecond, and can be sorted by time.
◆Image storage
Amazon S3 was used for image storage, and several terabytes of data were saved. Data stored in S3 was delivered through Amazon CloudFront.
◆Cache
Instagram uses Redis to store the mapping between approximately 300 million images and the users who posted them, and to determine which Postgres shard to access when retrieving images for the main feed and activity feed. Ta. Redis is sharded across multiple servers, and all data is stored in memory to improve access speed. By making full use of hashing, it was possible to store 300 million pieces of mapping data in a 5GB area.
Also, six Memcached instances were used for Django's cache. In 2013, we published a paper on how we scaled Memcached to handle billions of requests per second.
In this way, users can now view the latest images of the people they follow in their feed.
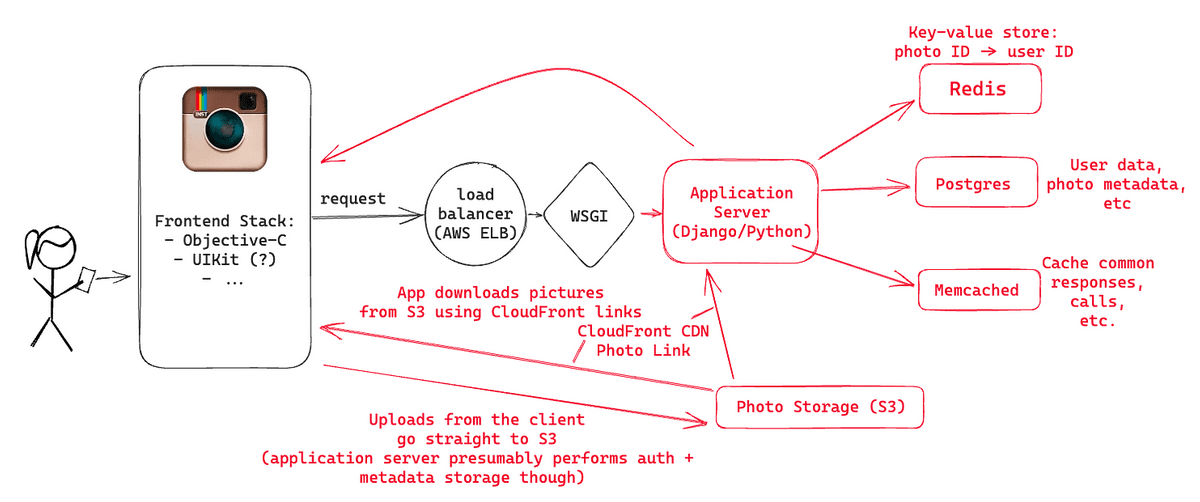
Postgres and Redis were both running in a master-replica setup, leveraging Amazon EBS snapshots to create frequent backups, and on the backend using Gearman to ensure work was done on the right machine. Asynchronous tasks such as notifying all followers of activities such as posting new images were distributed.
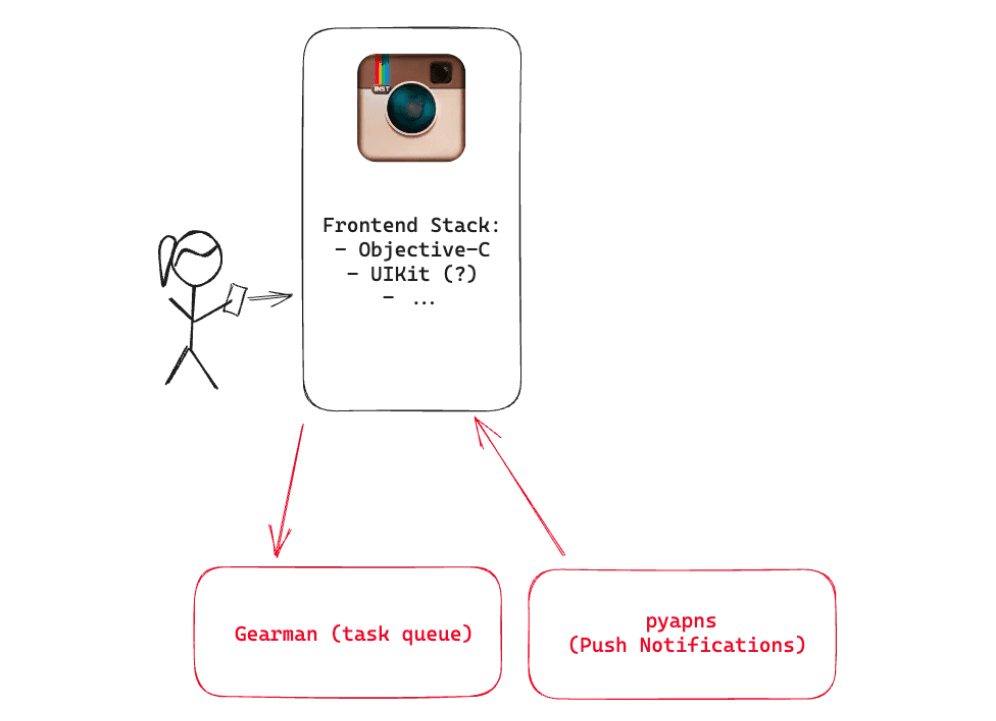
For push notifications we were using
Also, for error monitoring, they used open source Sentry , Munin , and Pingdom . Sentry was responsible for detecting Python errors in real time, and Munin was responsible for graphing system-wide statistics and warning of anomalies. Pingdom was used to monitor services from the outside.
By utilizing these technologies, Instagram was able to provide a service that supports 14 million people with just three engineers.
A forum related to this article has been set up on the GIGAZINE official Discord server. Anyone can write freely, so please feel free to comment!
• Discord | 'Tell me the secret to completing a service with a small number of people!' | GIGAZINE
https://discord.com/channels/1037961069903216680/1155796678721404938
Related Posts:







in Software, Web Service, Posted by log1d_ts