How does Meta maintain the infrastructure to run AI at scale?

Meta is actively developing and utilizing AI, such as
Maintaining large-scale AI capacity at Meta - Engineering at Meta
https://engineering.fb.com/2024/06/12/production-engineering/maintaining-large-scale-ai-capacity-meta/
Meta has traditionally operated a large number of data centers around the world, but the rise of AI has forced the company to transform its data center fleet. Large-scale generative AI models require trillions of parameters to train, which requires enormous resources.
Meta is building one of the world's largest AI training infrastructures, with the number of GPUs in use expected to reach 600,000 by 2025. Hundreds of different teams perform thousands of training tasks every day, and depending on the task, it may be necessary to closely coordinate a large number of GPUs.
Meta says that when building a GPU cluster for training AI, the following conditions must be met:
·capacity
Most tasks need to be done quickly and don't allow for a lot of space to be set aside as standard.
・Bad hosts are deadly
Most tasks require all hosts to be in sync, so a bad host that's just a little slow, has minor hardware issues, or has network problems becomes a huge problem.
・Cannot be interrupted
The task of training the AI is a coordinated effort among many hosts, so any interruptions have a large impact.
There are risks to the rollout
AI software stacks are deep, so special care must be taken when rolling out new components, as it can be difficult to pinpoint the cause when a problem occurs.
Host consistency
When using multiple hosts for AI training tasks, hardware compatibility should be high as long as the CUDA versions match, but it is very important to standardize the hardware for efficient debugging.
Meta uses custom hardware with the latest chips and high-performance backend networking, and strives to keep the software as up-to-date and flexible as possible. Because there are so many hosts and we need to update many hosts in parallel at all times, we maintain compatibility between components so that we can update components in a sliding scale.
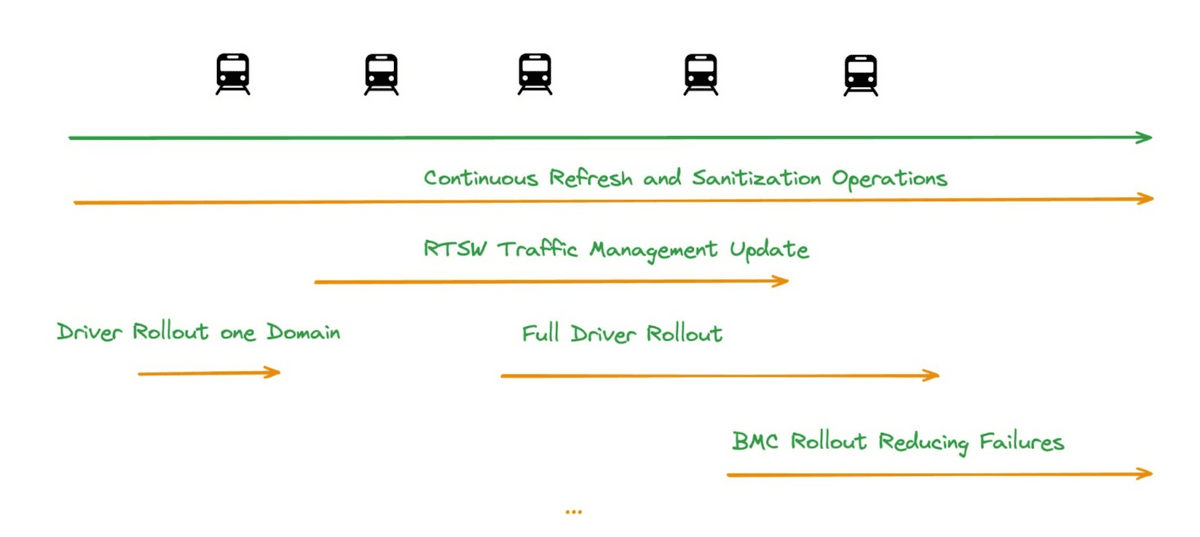
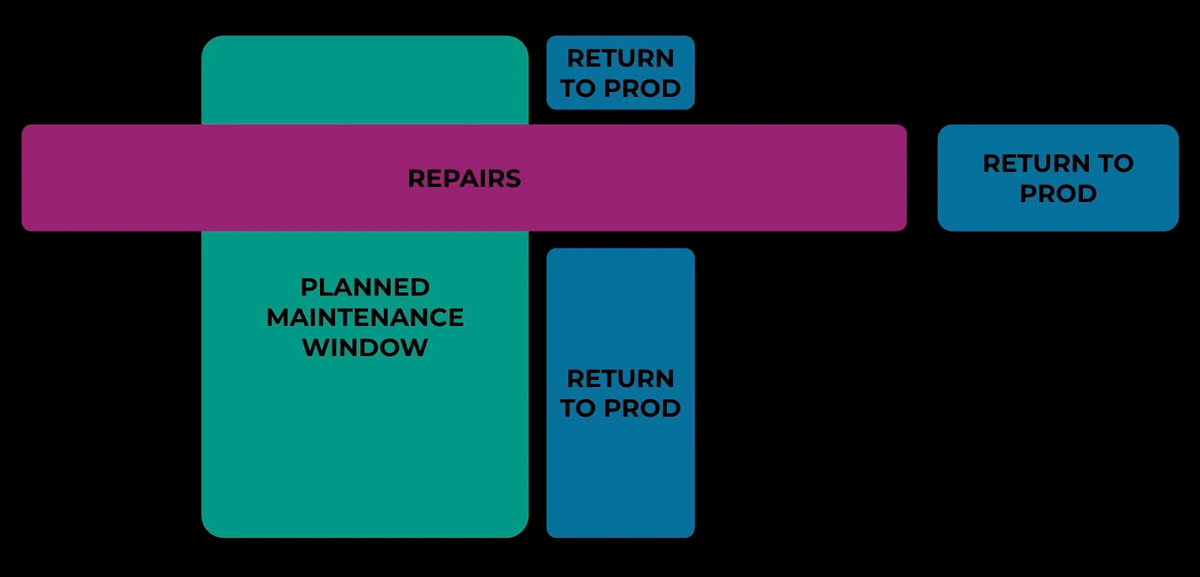
For maintenance of clusters that operate multiple hosts at once, a technique called 'maintenance train' is used. In the 'maintenance train', a small number of hosts in the cluster are sequentially removed from operation, and at that point, all possible updates are applied and the host is returned to the cluster. By having each host undergo maintenance at regular intervals (maintenance train), the entire cluster can be constantly updated while maintaining availability.
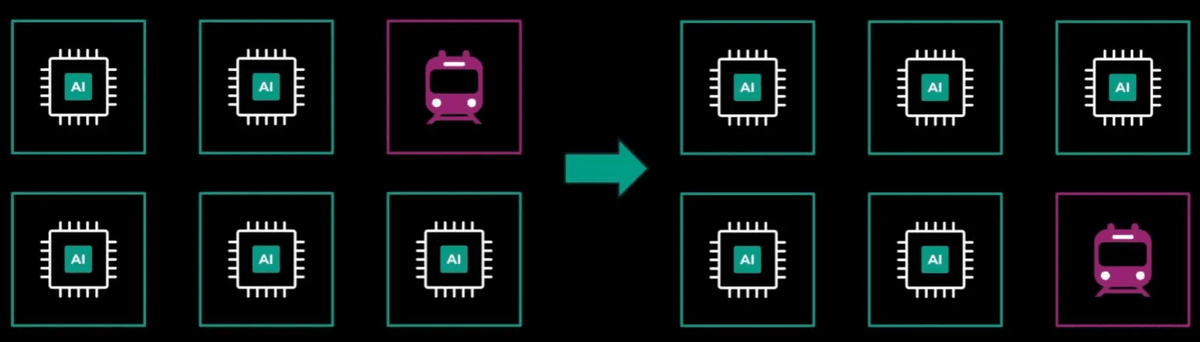
Additionally, due to the scale of the infrastructure, any disruptive rollouts must be orchestrated in a gradual manner, meaning different hosts in the cluster need to be able to run the tasks without issues even if they have different configurations. This is common for non-AI training scenarios, but is a challenge as AI tasks are tightly coupled to the hardware.
In Meta, the CUDA libraries and AI tasks themselves are always consistent, but the lower components such as the OS, firmware, and network can be done incrementally. It sounds simple, but it took a lot of development, including careful testing at all levels, special monitoring, and close collaboration with vendors.

To optimize AI performance, it is also important to adjust the number of hosts undergoing maintenance at the same time. Performing maintenance on a large number of hosts at the same time will temporarily reduce processing power, while performing maintenance on a small number of hosts at the same time will cause a large number of interruptions to tasks running on the hosts. Meta is working with the AI team to find the optimal number.
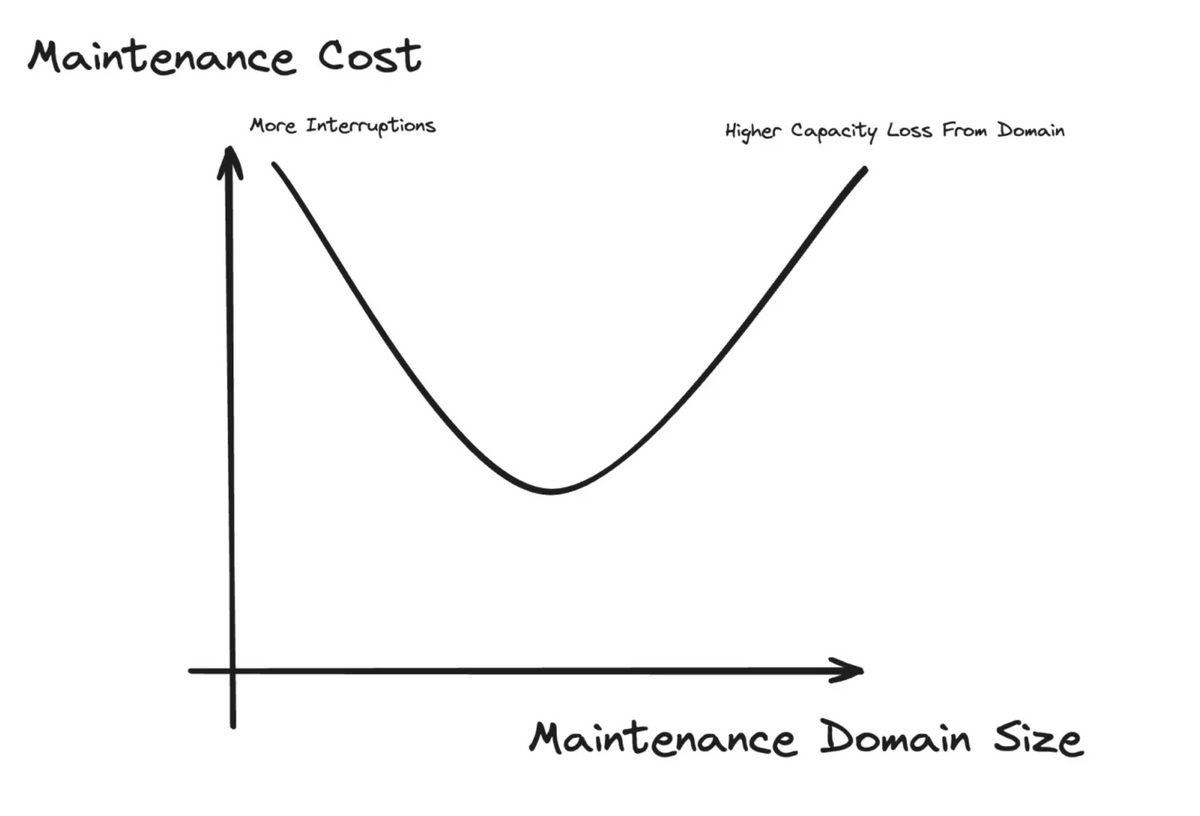
Meta uses a tool called 'OpsPlanner' for cases where all related hosts need to be updated at the same time, such as when updating the version of CUDA. By using OpsPlanner, it is possible to automatically perform operations on thousands of hosts at the same time, make the appropriate updates, and move them to the production environment.
For more information about Meta's AI training efforts other than maintenance, please see the article below.
Meta explains what they paid attention to when training large-scale language models and how they worked on it - GIGAZINE

Related Posts: