




Metaが「テキストから画像」「画像からテキスト」の両方に1つのモデルで対応できる生成AI「CM3leon」を発表

FacebookやInstagramといったSNSを開発するMetaの人工知能(AI)研究所であるMeta AIが、テキストから画像を生成したり、画像からテキストを生成したりすることができる単一のAIモデル「CM3leon(カメレオン)」を発表しました。
Introducing CM3leon, a more efficient, state-of-the-art generative model for text and images
https://ai.meta.com/blog/generative-ai-text-images-cm3leon/
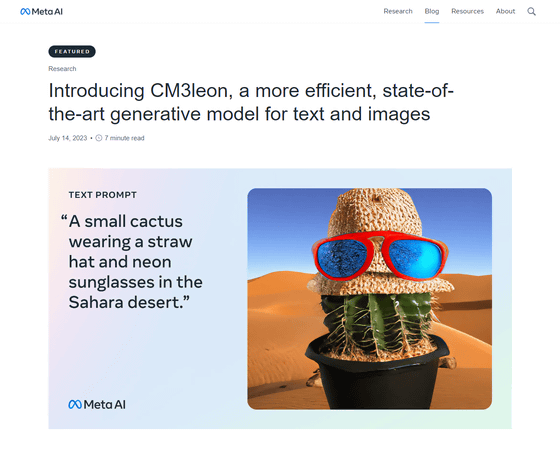
Introducing CM3leon, a first-of-its-kind multimodal model that achieves state-of-the-art performance for text-to-image generation with 5x the compute efficiency of competitive models.
— Meta AI (@MetaAI) July 14, 2023
More details ➡️ https://t.co/VR12zkmLDs pic.twitter.com/jUnG7G1Fxf
Meta claims its new art-generating model is best-in-class | TechCrunch
https://techcrunch.com/2023/07/14/meta-generative-transformer-art-model/
Meta reveals new AI image generation model CM3leon, touting greater efficiency | VentureBeat
https://venturebeat.com/ai/meta-reveals-new-ai-image-generation-model-cm3leon-touting-greater-efficiency/
CM3leonはREALMとセカンドマルチタスクファインチューニング(STF)ステージを含む、テキストのみの言語モデルを利用してトレーニングされた最初のマルチモーダルモデルです。
CM3leonはシンプルかつ強力なモデルを生成し、トークナイザベースのTransformerを、既存の拡散モデルと同じくらい効率的にトレーニングすることが可能。さらに、Transformerベースのトレーニングよりも5倍少ないコンピューティングでトレーニングしても、テキストから画像を生成するパフォーマンスで最先端のモデル同様のパフォーマンスを実現可能です。
また、CM3leonは低いトレーニングコストと推論効率を維持しながら、自己回帰モデルの多用途性と有効性を備えています。これは他の画像およびテキストコンテンツの任意のシーケンスを条件としてテキスト画像シーケンスを生成できるため、因果マスク混合モーダル(CM3)モデルでもあるとMetaは説明しています。
一般的に、テキストのみの生成AIは指示プロンプトに従う能力を向上させるために、さまざまなタスクに合わせてマルチタスク指示が調整されています。一方で、画像生成モデルは特定のタスクに特化されているそうです。これに対して、CM3leonはテキストと画像のどちらも生成可能となるように、大規模マルチタスク命令チューニングを適用しており、これにより「画像のキャプションの生成」「視覚的な質疑応答」「テキストベースの編集」「条件付き画像生成」などのパフォーマンスが大幅に向上しています。
最も広く利用されている画像生成ベンチマークのzero-shot MS-COCOでパフォーマンスを比較したところ、CM3LeonはFID(Fréchet Inception Distance)スコアで「4.88」を達成しており、テキストから画像を生成する上で最先端モデル並みのパフォーマンスを実現しています。なお、これはGoogleの画像生成AIである「Parti」のパフォーマンスを上回っているそうです。
CM3Leonは「サハラ砂漠にある麦わら帽子とサングラスをかけて小さなサボテン」など、複雑な構成要素を持った画像を生成することができるだけでなく、視覚的な質問への応答や長い形式のキャプション、さまざまな視覚言語タスクなど優れたパフォーマンスを発揮可能です。これはわずか30億のテキストトークンで構成されるデータセットでトレーニングした場合であっても同様だそうです。

CM3leonを使えば、画像生成ツールは「入力プロンプトによく従った、一貫性のある画像」を生成可能です。これについて、Metaは「多くの画像生成モデルは全体的な形状や局所的な詳細を復元する能力に苦労しています。一方で、CM3leonはこの分野で強力なパフォーマンスを発揮しており、さまざまなタスクをひとつのモデルで実行可能です」と記しています。
MetaはCM3leonが得意とするタスクとして、以下の7つを挙げています。
◆テキストガイドによる画像の生成と編集
複雑なオブジェクトの場合、またはプロンプトにすべての制約を含める必要がある場合、画像生成は非常に困難になります。CM3leonのテキストガイドによる画像編集機能を使えば、「空の色を明るい青に変更する」などの入力で、画像の編集が可能。これはAIモデルがテキストの指示と視覚的なコンテンツの両方を同時に理解しているCM3leonだからこそ実現できます。
◆テキストから画像を生成
CM3leonは高度な構造を持つプロンプトを与えられた場合でも、プロンプトに従って一貫した画像を生成することが可能です。以下は実際にCM3leonでテキストから生成した画像の例で、左から「サハラ砂漠にある麦わら帽子とサングラスをかけて小さなサボテン」「人間の手のクローズアップ写真。高品質なもの」「壮大な戦いの準備をしている、刀を持ったアニメ調のアライグマ」「1991という数字が入ったファンタジー風の一時停止標識」というプロンプトで生成された画像です。

◆テキストベースの画像編集
画像とテキストのプロンプトが両方存在する場合、テキストの指示に従って画像を編集します。テキストガイドによる画像編集専用に調整されたInstructPix2Pixなどのモデルとは異なり、単一のモデルでこれも実現できるというのがCM3leonの優れたポイントです。
以下はテキストベースの画像編集の一例で、左から元画像、「ヒゲの生えた男性のように見える」「サングラスをかける」「100歳に見える」「フェイスペイントを施す」というテキストで編集した画像。

◆テキストタスク
CM3leonはさまざまなプロンプトに従って短いまたは長いキャプションを生成し、画像に関する質問に答えることが可能です。例えば犬が棒を持っている以下の画像の場合、「犬は何を運んでいますか?」と入力すれば、CM3leonは「棒」と回答します。さらに、「画像を非常に細かく説明してください」と入力すれば、CM3leonは「画像には棒をくわえた犬がいます。地面には草が生えており、背景には木々が見えます」と返答するそうです。

CM3leonの画像からテキストを生成するパフォーマンスは、既存のAIモデルと比べても同等のパフォーマンスを発揮していることが明らかになっています。Flamingo(1000億トークン)やOpenFlamingo(400億トークン)と比べて、CM3leon(30億トークン)はトークン数が非常に少ないにもかかわらず、MS-COCOのベンチマークでこれらと同等のパフォーマンスを発揮しており、Flamingoのスコアを上回ることさえあったそうです。
◆構造に基づいた画像編集
構造に基づいた画像編集では、テキストの指示だけでなく入力として使用される構造情報やレイアウト情報の理解と解釈も含まれます。CM3leonは指定された構造やレイアウトのガイドラインを順守しながら、視覚的に一貫性があり、状況に応じて適切な編集を画像に施すことが可能です。
◆オブジェクトから画像へ
画像の境界ボックスセグメンテーションのテキスト説明を指定して画像を生成することもできます。
例えば、「洗面台と鏡のある部屋」を生成する際に、画像に含まれるオブジェクト(洗面台・ボトル・ベッド)の位置を指定することが可能です。

◆セグメンテーションから画像へ
セグメンテーションのみを含む画像を指定し、画像を生成することも可能。以下の画像は左から入力画像、入力画像をベースに出力したセグメンテーション、セグメンテーションをベースに出力した画像その1、その2です。

Metaは「CM3leonのようなモデルは、最終的にはメタバースでの創造性の向上とより優れたアプリケーションの作成に役立つ可能性があります。私たちは、マルチモーダル言語モデルの限界を探求し、将来さらに多くのモデルをリリースすることを楽しみにしています」と述べています。なお、MetaがCM3leonをリリースする予定があるかどうか、いつリリースする予定なのかは不明です。
・関連記事
Metaが開発した音声生成AI「Voicebox」は「他人の声で文章を勝手に読ませる」ことが可能、危険過ぎるのでMetaは一般公開を避ける - GIGAZINE
Metaが音楽生成AIモデルをオープンソースで公開、テキスト&音声入力で誰でも高品質な音楽を作成できるように - GIGAZINE
Metaが既存の生成AIにあるトークン制限をはるかに上回る100万トークン超のコンテンツ生成を可能にする次世代AIアーキテクチャ「Megabyte」を発表 - GIGAZINE
Metaの「LLaMA」と同規模のAIモデル構築をオープンソースで目指す「RedPajama」開発元のTogetherが2000万ドルの資金調達に成功 - GIGAZINE
文字・画像と映像・音・3D深度・熱・動作を統合して現実世界を理解できるAI「ImageBind」をMetaがオープンソースで公開 - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by logu_ii
You can read the machine translated English article Meta announces generation AI 'CM3leo….