




AWS・Azure・Cudoなどが提供するクラウドGPUが1時間あたり何ドルで利用できてどういう構成なのかの一覧表

ニューラルネットワークのトレーニングや実行にはGPUが使われることが多く、クラウドサービスのGPUの需要はAIの普及に伴い高まりつつあります。そんなクラウドGPUの構成や価格を、AI関連のニュース&コミュニティサイト・The Full Stackが公開しました。
Cloud GPUs - The Full Stack
https://fullstackdeeplearning.com/cloud-gpus/
表はクラウドサーバーとサーバーレスの2種類に分かれています。ピックアップされたサービスはAmazon Web Service(AWS)やMicrosoft Azure、Cudo Compute、Google Cloud Platform(GCP)、AWS Lambdaなど。Hugging Faceなど一部サービスの記載はありません。
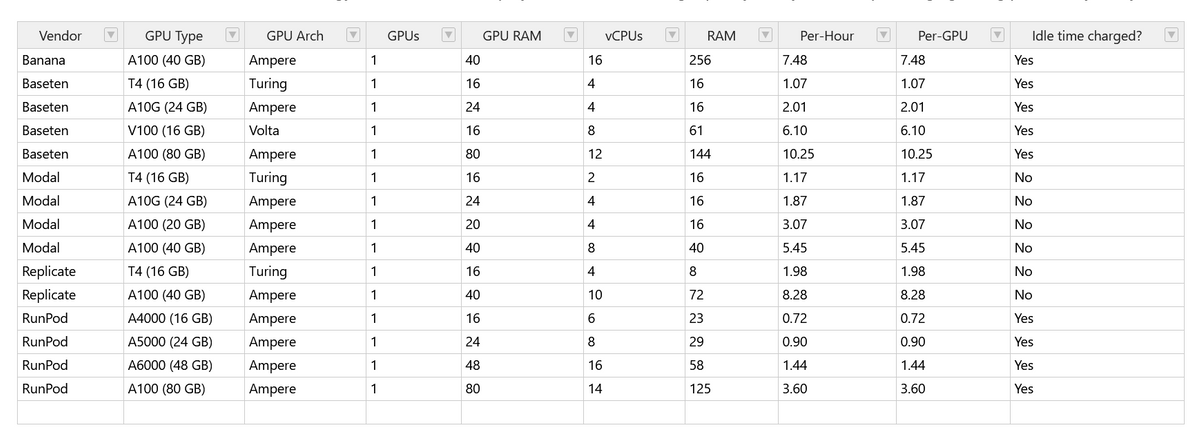
クラウドサーバーの表がこんな感じ。最左列にサービス名、その右にGPUタイプ、その右にアーキテクチャといった感じに記載されています。料金はすべてドル/時間の表記。
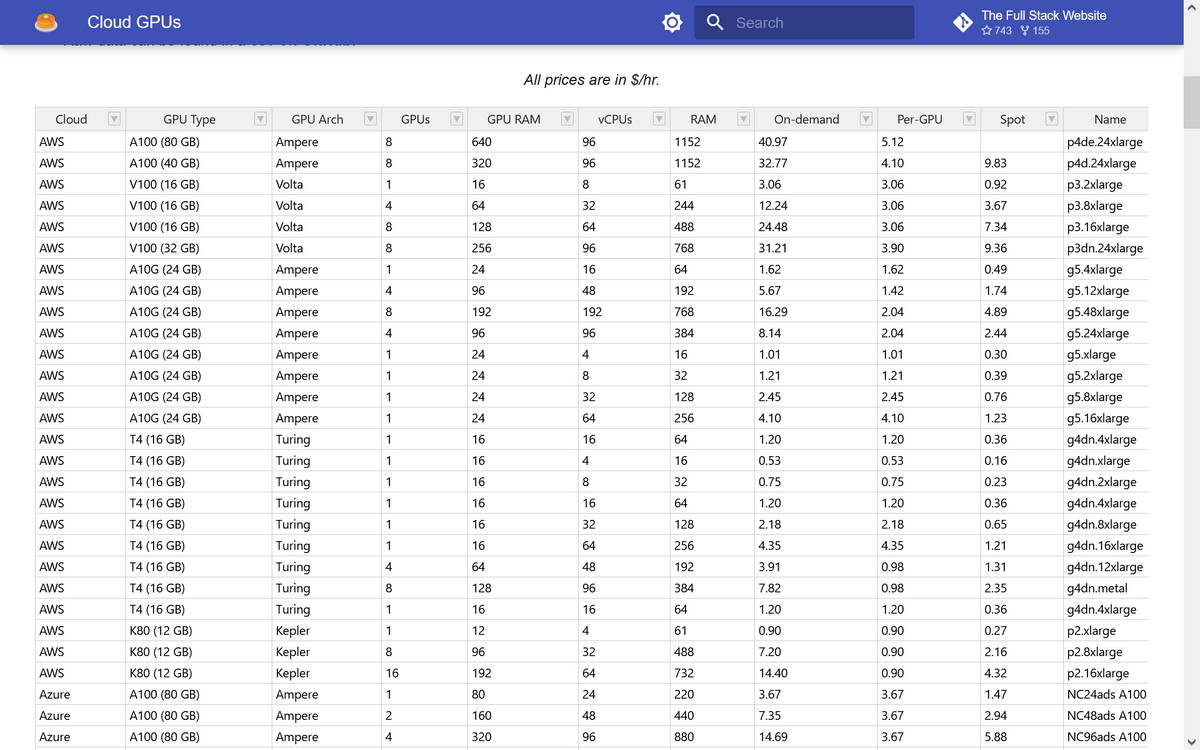
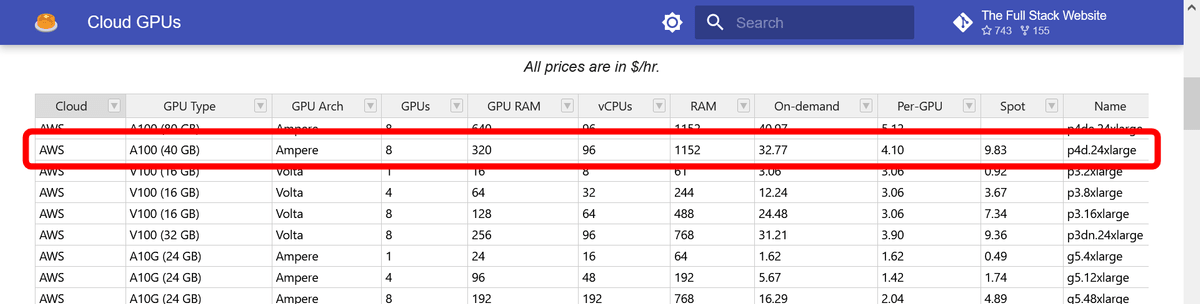
例えばAWSのp4d.24xlargeであれば、アーキテクチャはNVIDIAのAmpere、GPUの種類はA100(40GB)、個数は8個、RAMは320GiB、vCPUは96、RAMは1152GiB、オンデマンド料金が1時間当たり32.77ドル(約4578.87円)、GPU毎料金が1時間当たり4.10ドル(約572.81円)、スポットインスタンスの料金が1時間当たり9.83ドル(約1373.34円)です。
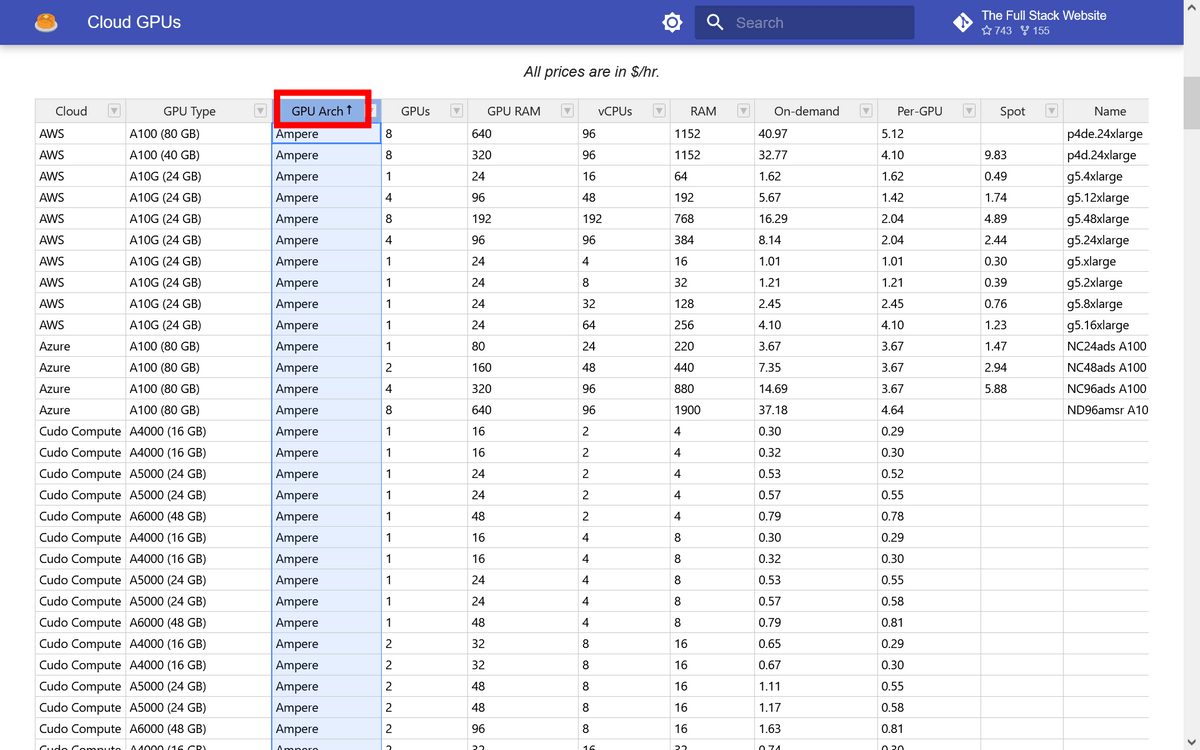
カテゴリのタイトルをクリックするとソートが可能。
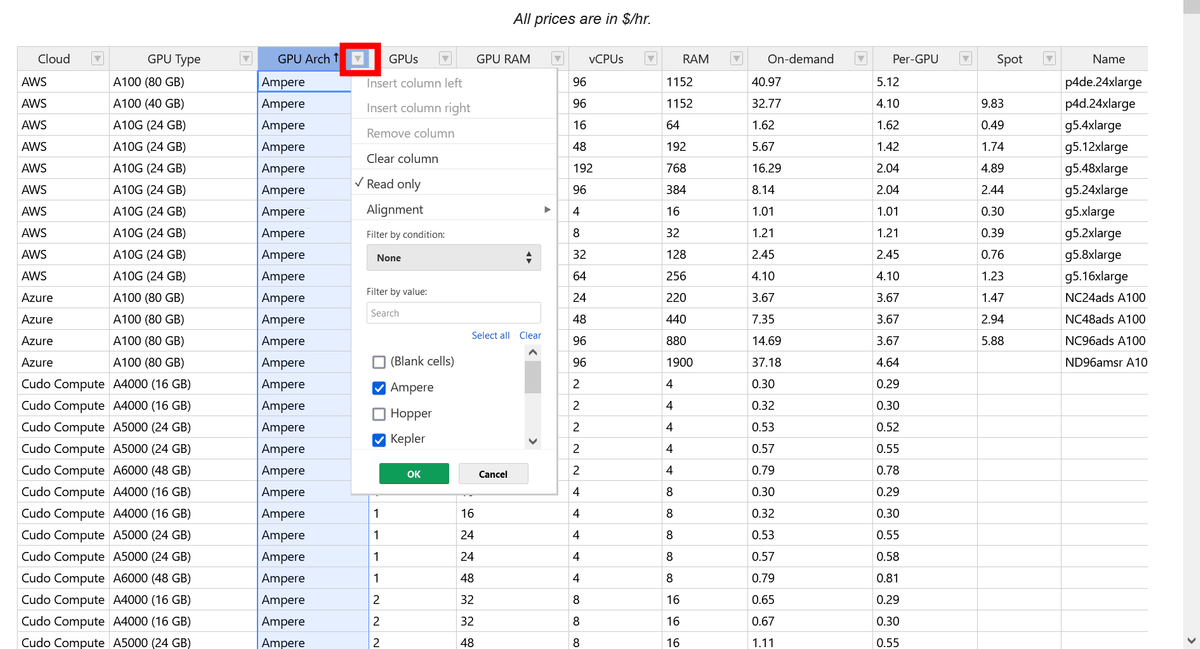
下向き三角印をクリックするとフィルターをかけられます。
クラウドサーバーの次にある表がサーバーレス。ここでは、「サーバー管理不要、柔軟なスケーリング、高可用性、アイドル容量なし」という条件をもってサーバーレスと定義されています。
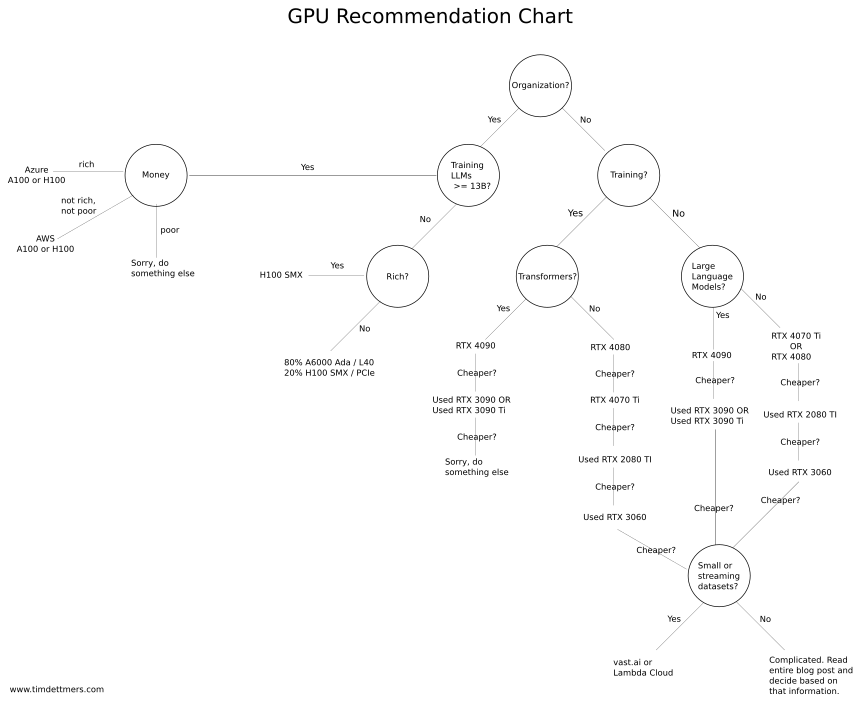
次に表示されるのは、GPUを選ぶときに役立つフローチャート。「組織?」「大規模言語モデル(LLM)をトレーニングしたい?」などの質問に答えていくと、適切なGPUがわかるというものになっています。この図によると、13B以上のLLMでトレーニングしたい場合はAzureまたはAWSの利用がオススメとのこと。
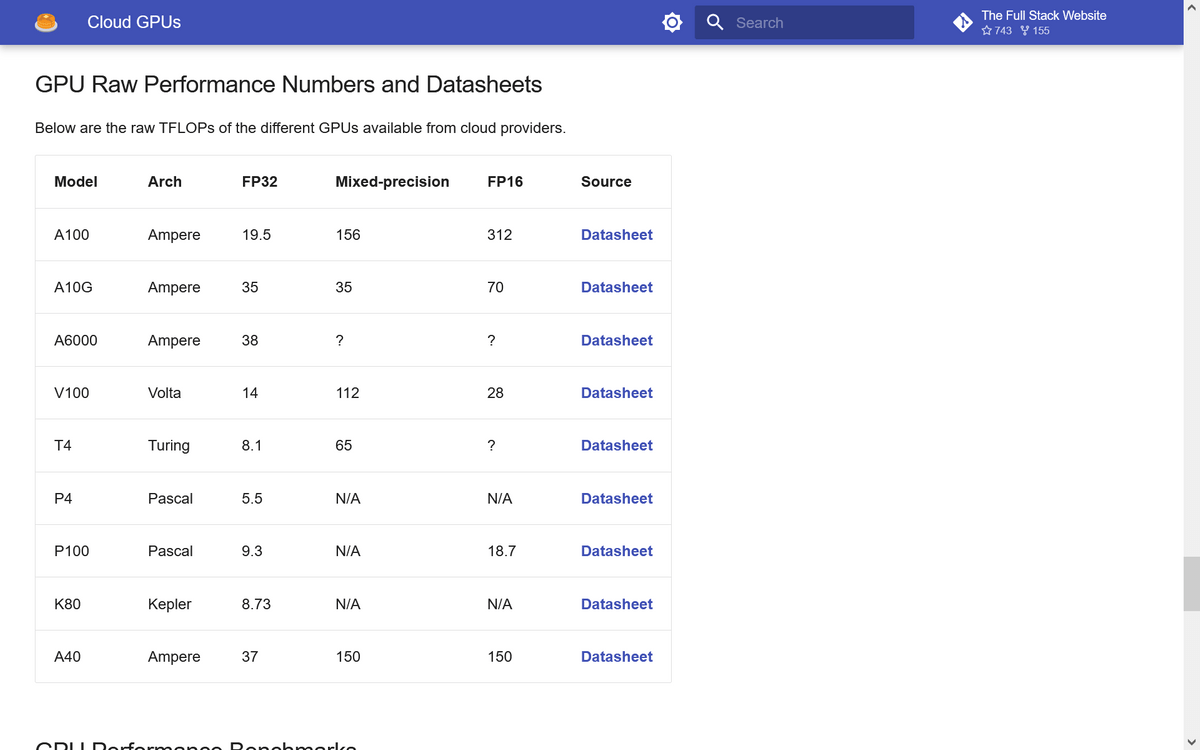
GPUモデルごとのデータシートへのリンクも掲載されていました。
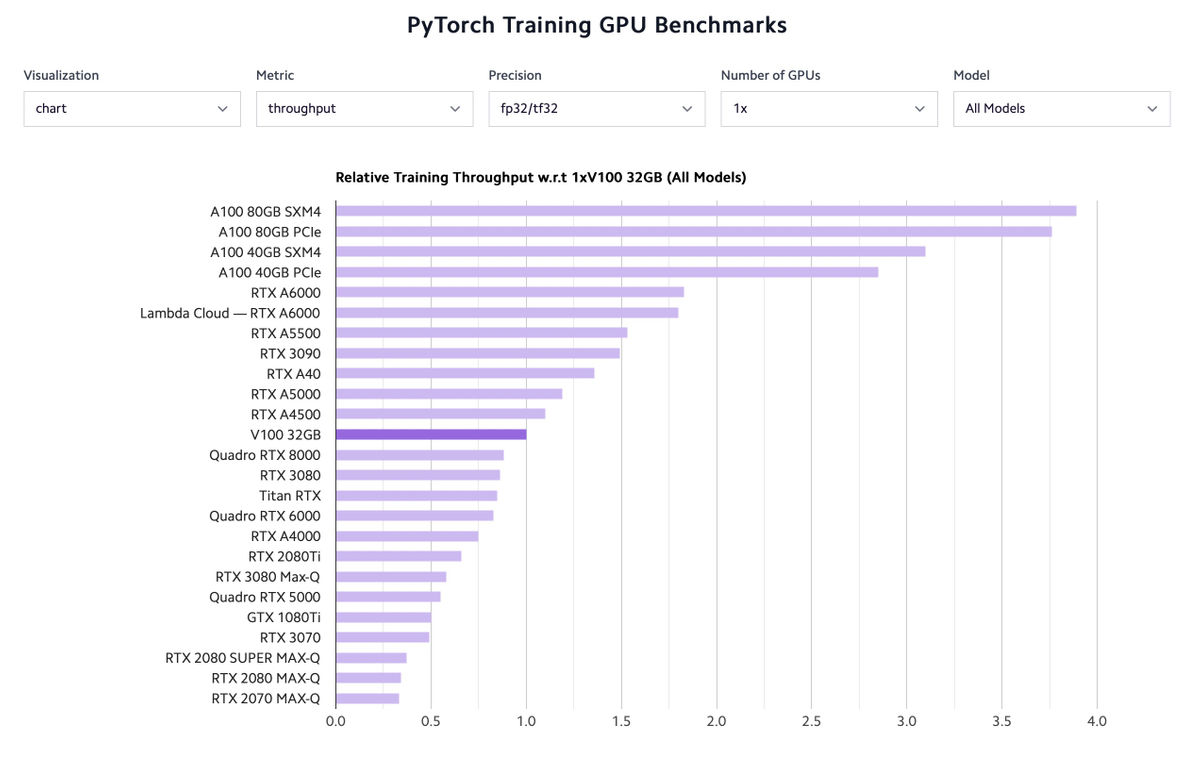
その次に記載されているのは、一般的な深層学習タスクにおけるGPUの基本的なベンチマーク。

最後にはLambda Labsが公開したPyTorchのベンチマーク結果が掲載されています。
・関連記事
NVIDIAが価格5万2800円からのミドルレンジGPU「GeForce RTX 4060 Ti」「GeForce RTX 4060」を発表 - GIGAZINE
CPU・メモリ・GPU使用率や天気予報・ビットコインの価格などあらゆる情報を表示できるシステムモニター「thilmera」レビュー - GIGAZINE
最も費用対効果の高いクラウドを自動選択して大幅なコスト削減が可能な「SkyPilot」 - GIGAZINE
・関連コンテンツ




in ネットサービス, Posted by log1p_kr
You can read the machine translated English article A list of how many dollars per hour the ….