画像生成AI「Stable Diffusion」でfMRIによる脳活動のデータから画像を生成する研究を阪大の研究者が発表

磁気共鳴機能画像法(fMRI)は、脳内の活動部位を非侵襲的に測定するための方法です。このfMRIで測定した脳の機能活動から画像生成AIのStable Diffusionを使い、被験者が見た画像を再構築することに成功したという論文を、大阪大学大学院生命機能研究科の高木優助教らが発表しました。
High-resolution image reconstruction with latent diffusion models from human brain activity | bioRxiv
https://doi.org/10.1101/2022.11.18.517004
Stable Diffusion with Brain Activity
https://sites.google.com/view/stablediffusion-with-brain/
High-resolution image reconstruction with latent diffusion models from human brain activity | bioRxiv
https://doi.org/10.1101/2022.11.18.517004
人間が目や耳で何かを認識したり何かをイメージしたりした時、脳細胞の活動が活発になります。脳細胞の活動が活発になるとその部位の血流が増加します。fMRIは、この血流増加によるわずかな磁気の変化を捉えることで、脳の活動部位を視覚化できる装置で、外科手術を必要としない非侵襲的な測定が可能です。
視覚で何かを捉えた人の脳の機能活動から、その人が得た視覚体験を再現する試みはこれまでの研究でも行われてきました。視覚体験は初期視覚野で扱われる「映像特徴」と、より高次な視覚野で扱われる「文章的な意味特徴」で構成されますが、高木助教の研究はこの2つを組み合わせ、Stable Diffusionを用いて画像化するというものです。
Stable Diffusionの仕組みについては、以下の記事にまとめられています。
画像生成AI「Stable Diffusion」がどのような仕組みでテキストから画像を生成するのかを詳しく図解 - GIGAZINE

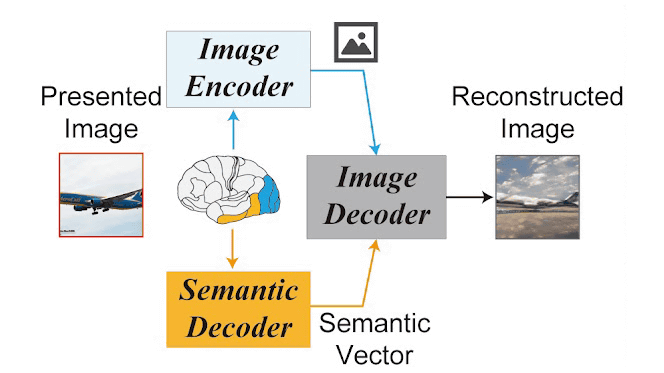
以下はStable Diffusionの仕組みを示した図。画像(X)を画像エンコーダー(ε)で読み込んで潜在表現(z)に変換し、ノイズを付加させる拡散プロセスでzTに変換。このzTをUNETエンコーダーに通して拡散プロセスの逆、つまりノイズを除去します。この時、入力したテキストをテキストエンコーダーのCLIP(τ)で特徴量(c)に変換します。このcでノイズ除去の方向性を調整することで、新たな潜在表現(zc)を生成し、このzcを画像デコーダー(D)に読み込ませることで新たな画像(X')を生成します。
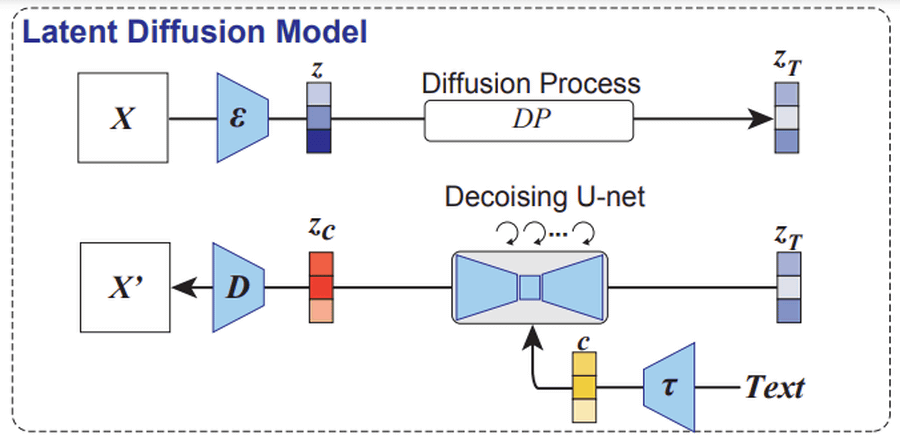
そして、高木助教の研究が以下。fMRIで測定した初期視覚野の活動(映像特徴)から潜在表現(z)を取得し、画像デコーダーに読み込ませて画像(Xz)を生成します。この画像のリサイズコピーをStable Diffusionの画像エンコーダーに読み込ませ、拡散プロセスを経て潜在表現(zT)を生成します。さらに、高次視覚野の活動(文章的な意味特徴)から線形モデルによって得たテキスト表現からテキストエンコーダーで特徴量(c)を獲得。UNETエンコーダーでzTとcから潜在表現(zc)を生成し、これをデコーダーに通して画像(Xzc)を生成します。このXzcが、被験者が見た画像をStable Diffusionを使って再構成した画像になります。
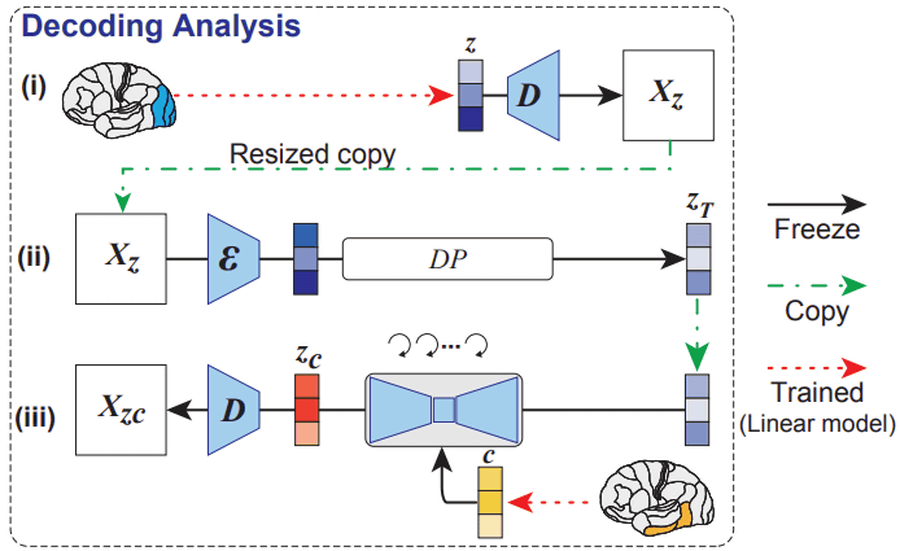
実験で被験者に提示されたのが一番左の赤枠に囲まれた画像。その被験者の初期視覚野から生成した画像がZ、高次視覚野の脳活動からテキストエンコーダーで生成した画像がC、最終的にStable Diffusionによって生成された画像がZcです。赤枠の画像とZcを見比べると、確かに被験者が見た画像を再構成できているということがわかります。

ただし、個人によって脳の形や構造が異なるため、個人で作ったモデルを直接他人に適用することはできないとのこと。以下は、4人の被験者(subj01・subj02・subj05・subj07)に左端の画像を見せてから、Stable Diffusionを通じて生成された画像。なんとなく共通点らしいものはありますが、違う画像が生成されていることがわかります。それでも、個人差を補正する手法はいくつか提案されているとのことで、被験者を横断したモデルの適用は一定精度で可能ではないかと高木助教は期待しています。

さらに高木助教らは、潜在拡散モデルにおける特定の構成要素を脳活動部位にマッピングすることで、潜在拡散モデルの各構成要素を脳神経科学の観点から定量的に解釈する試みも行っています。
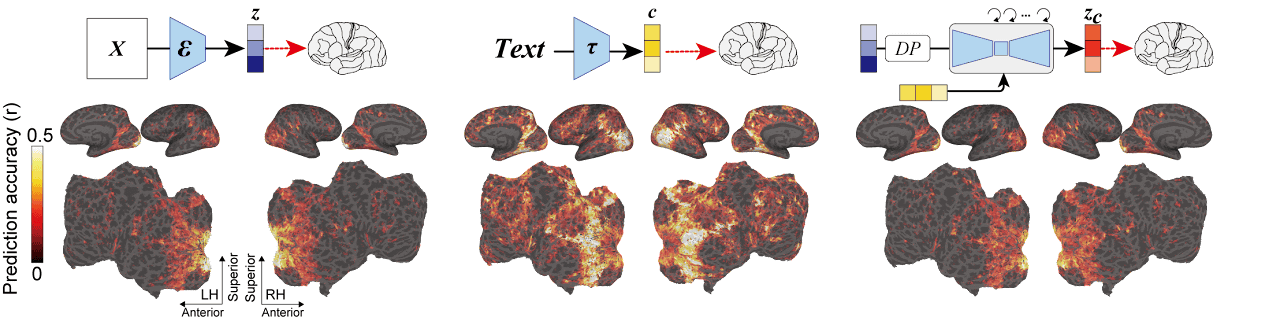
従来の研究でも機械学習を使ってfMRIのデータから画像を生成することを目指した研究はありましたが、そのトレーニングやファインチューニングが必要でした。しかし、高木助教らの手法では、fMRIの測定結果から潜在表現を作成するための線形モデルをトレーニングするだけで、Stable Diffusionについてはバージョン1.4のモデルがそのまま利用されています。
高木助教の線形モデルのトレーニング用データセットには、最大1万枚の画像を複数回見ている被験者の脳活動の測定データをまとめた「Natural Scenes Dataset」が用いられたとのこと。
高木助教によれば、「何かを体験(知覚)しているときの脳活動とそれを想起あるいは夢を見ている時の脳活動には一定の相同性があることが知られており、この性質を利用して想起あるいは夢の内容を一定精度で解読できることが知られています」とのことで、見ている夢を画像で視覚化できる可能性を示唆しています。ただし、高木助教は「(今回の研究は)知覚した内容と脳活動の関係性を調べるもので、マインド・リーディングではありません」と述べており、人が考えていることをそのまま視覚化するような技術ではないと念押ししています。
さらに、高木助教は「前提として、脳の情報を十分に解読する技術がすぐに実用化されることは考えにくいです。今回の論文で扱ったようなデコーディングモデルを構築するためには、大型のfMRIスキャナーに何時間も入らなければいけません。デコーディングモデルの精度もまだまだ向上の余地があります」としながらも、「脳活動を解読することは倫理やプライバシーに関わる重大な問題を引き起こす可能性があります。私たちは、脳は極めてデリケートな個人情報であると考えており、インフォームドコンセントなしに、いかなる形の脳活動解析も行われるべきでないと強く信じています」と述べました。
・関連記事
人の脳は目で見た情報を「低解像度の圧縮データ」にエンコードして保存していることが判明 - GIGAZINE
「同じものを見ても支持政党が違うと解釈がまったく異なるのはなぜか?」が神経学的に解明される - GIGAZINE
「ゲーム・オブ・スローンズ」のキャラクターになりきっている人の脳内では何が起きているのか? - GIGAZINE
画像生成AIの「Stable Diffusion」をゲームに活用する方法 - GIGAZINE
ポーズや構図を指定してサクッと好みのイラスト画像を生成しまくれる「ControlNet」&「Stable Diffusion」の合わせ技を試してみたよレビュー - GIGAZINE
・関連コンテンツ