




OpenAIがAIのウェブ検索能力を測定する高難度ベンチマーク「BrowseComp」を発表

インターネット上の情報を収集して回答を生成できるAIエージェントが次々と登場しています。新たに、OpenAIがAIエージェントのウェブ検索能力を測定できるベンチマーク「BrowseComp」を発表しました。
BrowseComp: a benchmark for browsing agents | OpenAI
https://openai.com/index/browsecomp/
ウェブ検索能力を測定するテストはOpenAIが2024年10月に発表したベンチマーク「SimpleQA」にも含まれていますが、GPT-4oなどのブラウジング機能はすでにSimpleQAで測定できる範囲を超える能力を備えているとのこと。そこで、OpenAIはインターネット上の「複雑で見つけにくい情報」を見つける能力を測定できるベンチマークツールとしてBrowseCompを開発しました。BrowseCompは「Browsing Competition(ブラウジング競争)」の略語です。
BrowseCompには高難度かつ正誤の評価が簡単な問題が1266問含まれています。各問題は人間のトレーナーによって以下の条件を満たすように作られています。
条件その1:「GPT-4o」「OpenAI o1」「Deep researchの初期バージョン」では解決できないことを確認する。
条件その2:人間のトレーナーが検索エンジンで5種類の検索を実施し、検索結果の最初の1ページ目に回答が表示されないことを確認する。
条件その3:人間が10分以内に解けない問題を作る。別のトレーナーに挑戦させて40%以上のトレーナーが正答した場合は問題を修正する。
作成された問題と回答例は以下の通り。問題から正答を導くのは困難ですが、反対に正答か否かは数回ウェブ検索すれば検証できます。
問題:2018年から2023年の間にEMNLPカンファレンスで発表された論文。筆頭著者はダートマス大学、第4著者がペンシルバニア大学で学士号を取得している。
回答:Frequency Effects on Syntactic Rule Learning in Transformers, EMNLP 2021
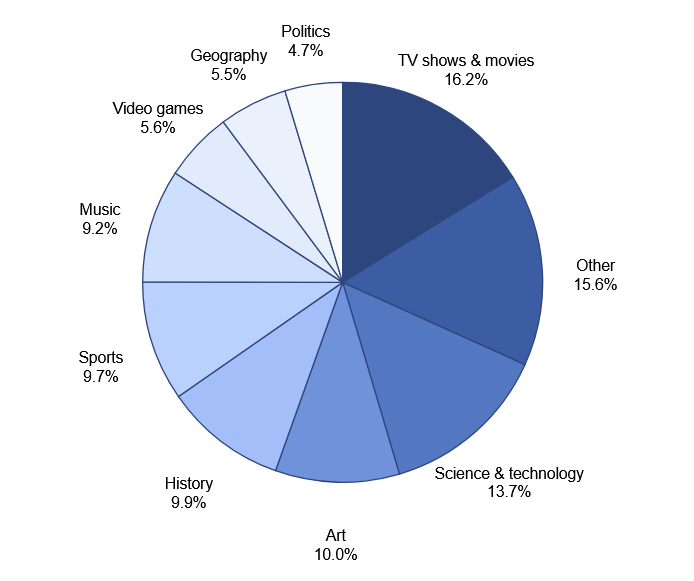
BrowseCompに含まれる問題のカテゴリの内訳はこんな感じ。「テレビ番組および映画」が16.2%、「科学および技術」が13.7%、「アート」が10.0%、「歴史」が9.9%、「スポーツ」が9.7%、「音楽」が9.2%、「ゲーム」が5.6%、「地理」が5.5%、「政治」が4.7%、「その他」が15.6%含まれています。
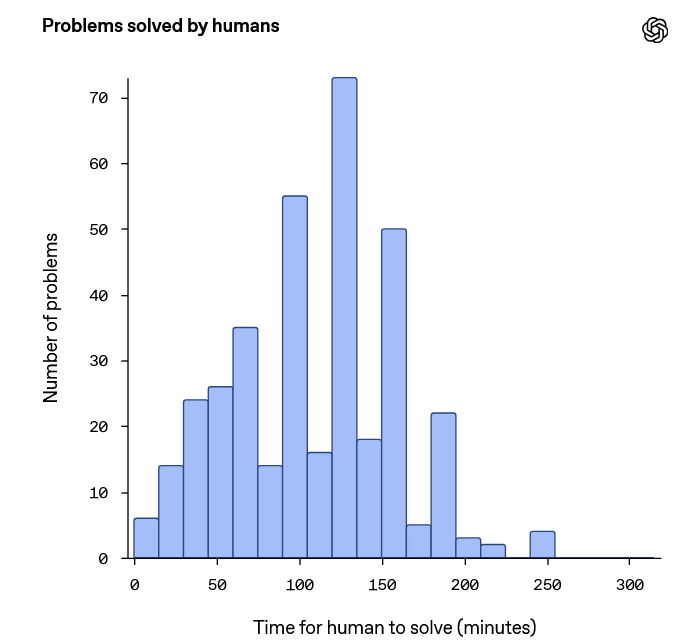
BrowseCompに含まれる問題のうち1255問を人間に解かせた結果、2時間以内に回答できた問題は367問(全体の29.2%)で、正解できた問題は317問(回答できた問題の86.4%)でした。回答に要した時間をまとめたグラフが以下。問題の中には数分で解けるものもあれば、数時間かかるものもありました。
OpenAIのAIモデルにBrowseCompの問題を解かせた結果は以下の通り。推論モデルのOpenAI o1でも9.9%しか正答できませんでしたが、ウェブ検索用のAIエージェントであるDeep researchは51.5%という比較的高い正答率を記録しました。
| モデル | 正答率 |
|---|---|
| GPT-4o | 0.6% |
| GPT-4oのウェブ検索機能 | 1.9% |
| GPT-4.5 | 0.9% |
| OpenAI o1 | 9.9% |
| Deep research | 51.5% |
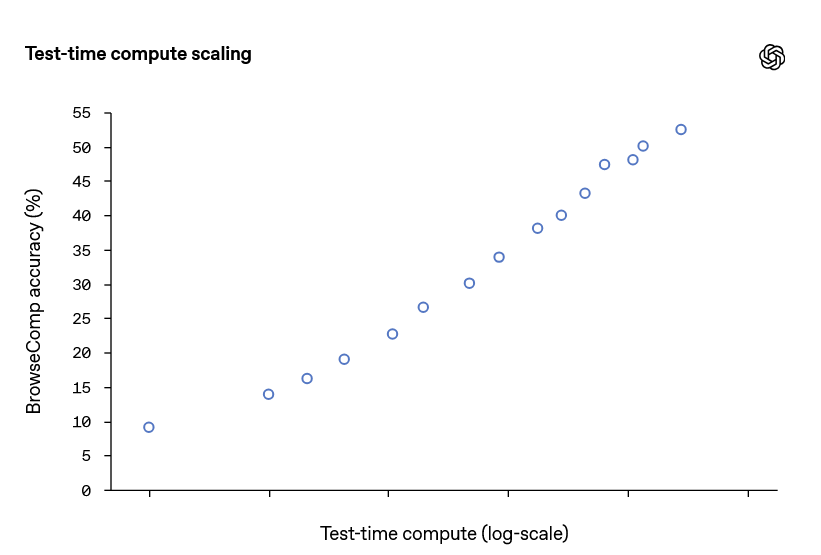
同じAIエージェントで推論に使うコンピューターリソースを増やした際のBrowseCompのスコアの推移を示すグラフが以下。推論にコストを割くほどスコアは上昇します。
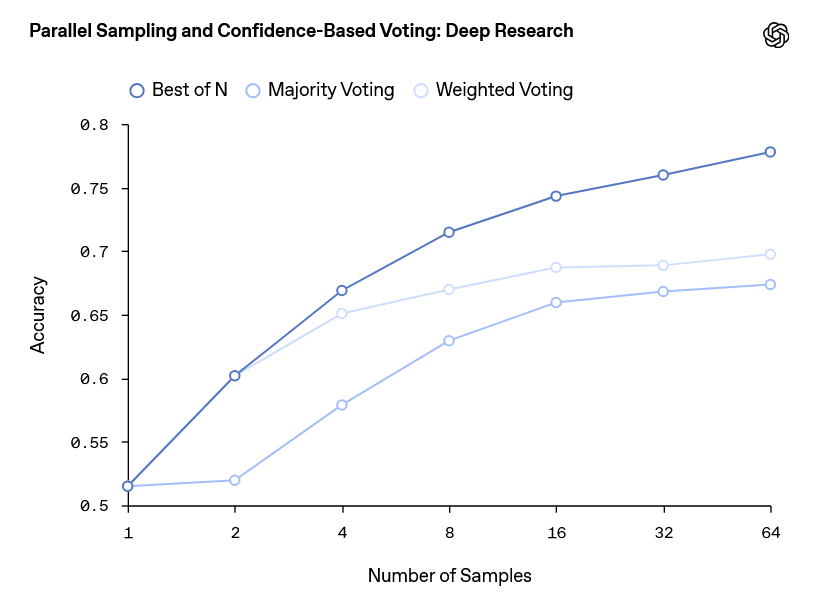
Deep researchでの回答生成を複数回実施し、「最も信頼スコアの高い回答(Best of N)」「信頼スコアで重み付けした多数決で選ばれた回答(Majority Voting)」「最も多く出力された回答(Majority Voting)」という条件で代表回答を選んだ際のスコアをまとめたグラフが以下。横軸は「回答の生成回数」を示しています。どの回答選択方法でも生成回数が増えるに従って正答率が向上しており、最も優れた回答選択方法は「Best of N」でした。
さらに、BrowseCompの問題の難度を分析するべく、各問題をDeep researchで64回解いて、正答率を調査しました。その結果、16%の問題は正答率100%で、14%の問題では正答率が0%でした。また、正答率0%の問題について「正答を提示された上で、正答を裏付ける証拠をウェブ上から探す」という課題を与えた結果、ほとんどの問題では証拠を探すことに成功。これらの結果から、OpenAIは「BrowseCompは単なる検索能力だけでなく、『検索を柔軟に再構築する能力』や『複数の情報源から断片的な手掛かりを抽出して回答を組み立てる能力』を測定できる」と結論付けています。
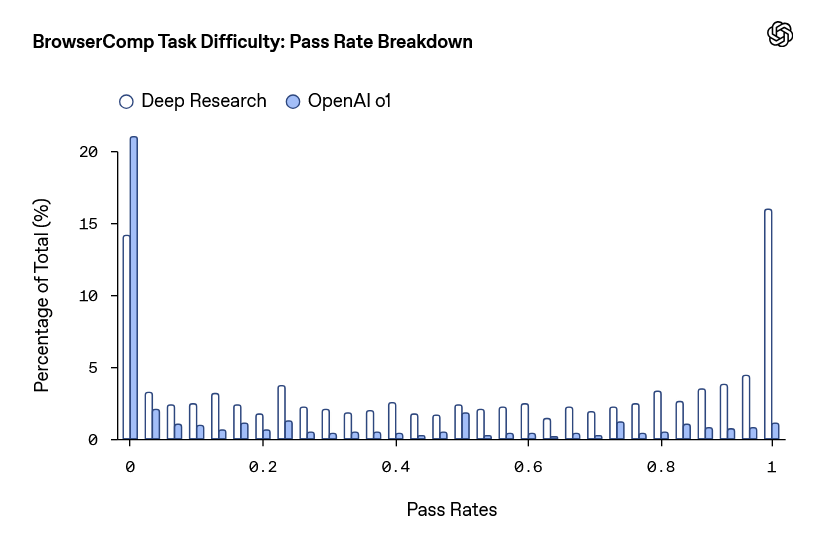
なお、BrowseCompは正解が1つしかない問題を扱うテストであり、BrowseCompのスコアが「自由回答形式の問題を解く能力」とどの程度相関しているのかは不明です。
BrowseCompはOpenAIのベンチマークツール集「simple-evals」に含まれています。
GitHub - openai/simple-evals
https://github.com/openai/simple-evals
また、BrowseCompについて記した論文は以下のリンク先で確認できます。
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
(PDFファイル)https://cdn.openai.com/pdf/5e10f4ab-d6f7-442e-9508-59515c65e35d/browsecomp.pdf

・関連記事
OpenAIがAIの論文理解&再現能力を評価するベンチマーク「PaperBench」を発表、人間とAIのどちらが研究開発力が高いのか? - GIGAZINE
OpenAIがAIベンチマーク「SWE-Lancer」を公開、フリーランスエンジニアに100万ドルで依頼するレベルのタスクをこなせるか測定 - GIGAZINE
OpenAIがGPT-4oの改良版となる「GPT-4.1」を含む複数モデルのリリースを準備中か - GIGAZINE
OpenAIが「o3」と「o4-mini」を数週間以内にリリースすることを発表、ただし「GPT-5」のリリースは先送り - GIGAZINE
ChatGPTに高精度な画像生成機能「4o Image Generation」が追加される、GPT-4oの知識を活用しつつ画像を生成可能で著名人を含む画像も可 - GIGAZINE
OpenAIが日本語にも対応した音声文字起こしモデルやテキスト読み上げモデルをリリース、無料で読み上げモデルを試せるデモも登場したので使ってみた - GIGAZINE
・関連コンテンツ







in ソフトウェア, Posted by log1o_hf
You can read the machine translated English article OpenAI launches BrowseComp, a highly cha….