




Mistral AIが自分の声をクローンして使えるテキスト音声合成AIモデル「Voxtral TTS」を発表、9言語に対応し爆速読み上げ&軽量&オープンソースで利用可能

フランスのAI企業・Mistral AIが、自然で感情豊かな音声を生成できるテキスト読み上げモデル「Voxtral TTS」を発表しました。主要な9言語に対応しているほか事前学習のいらない「ゼロショットクローンボイス再生」が可能で、文脈を理解して巧みな感情表現を行う音声を爆速で生成することができます。
Speaking of Voxtral | Mistral AI
https://mistral.ai/news/voxtral-tts
🔊Introducing Voxtral TTS: our new frontier open-weight model for natural, expressive, and ultra-fast text-to-speech
— Mistral AI (@MistralAI) 2026年3月26日
🎭Realistic, emotionally expressive speech.
🌍Supports 9 languages and accurately captures diverse dialects.
⚡Very low latency for time-to-first-audio.
🔄Easily… pic.twitter.com/Q2mdo8UBVo
Mistral releases a new open source model for speech generation | TechCrunch
https://techcrunch.com/2026/03/26/mistral-releases-a-new-open-source-model-for-speech-generation/
Mistral AI just released a text-to-speech model it says beats ElevenLabs — and it's giving away the weights for free | VentureBeat
https://venturebeat.com/orchestration/mistral-ai-just-released-a-text-to-speech-model-it-says-beats-elevenlabs-and
Voxtral TTSは英語、フランス語、ドイツ語、スペイン語、オランダ語、ポルトガル語、イタリア語、ヒンディー語、アラビア語の9言語に対応しており、その他細かい方言なども含めた音声エージェントの構築を可能にします。Mistral AIによると、5秒未満のボイスサンプルから微妙なアクセントや抑揚、イントネーション、話し方の流れの不規則性といった特徴を捉えたカスタム音声を生成できるとのこと。
Voxtral TTSはリアルタイム性能を重視して設計されており、入力を受けてからモデルがボイスを再生し始めるまでの時間を示すTTFA(Time-to-First Audio)は、500文字の10秒間のサンプル音声で90ミリ秒と高速になっています。また、リアルタイム係数(RTF)は6倍で、10秒間のクリップを約1.6秒でレンダリングできると示されています。
また、Voxtral TTSは「カスケード型音声間翻訳」の機能を備えており、例えばフランス語の音声から作成したボイスサンプルで、英語のテキストを入力して英語の音声を生成できます。公式ページでは、アメリカ英語・フランス語・イギリス英語の話者を選択し、英語・フランス語・スペイン語・ドイツ語のプロンプトを選択して音声を生成するデモを動かすことができます。
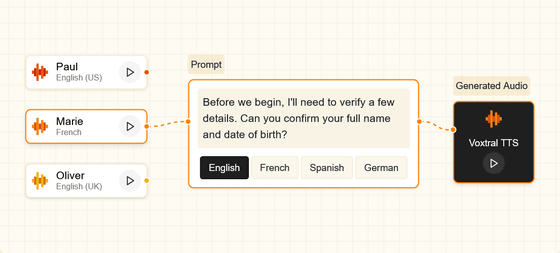
以下のムービーでは、実際に話し声を収録してクローン音声を作るデモを見ることができます。
Voice Customization 101 with Voxtral in Mistral Studio - YouTube
ゼロショットのカスタムボイステストにおいて、ネイティブスピーカーによる自然さ、アクセントの正確さ、オリジナルボイスとの類似性の評価に基づいた指標で、Voxtral TTSはElevenLabsの高速音声読み上げモデルのElevenLabs v2.5 Flashを上回り、レイテンシーの高いより高度なモデルであるElevenLabs v3と同等の性能を発揮したことが報告されています。
State-of-the-art performance.
— Mistral AI (@MistralAI) 2026年3月26日
In zero-shot custom voice tests, Voxtral TTS outperformed ElevenLabs v2.5 Flash - judged by native speakers for naturalness, accent accuracy, and similarity to the original voice. pic.twitter.com/ZY7PcRZGY3
Mistral AIの科学オペレーション担当副社長であるピエール・ストック氏は「ユーザーから音声モデルの要望が寄せられていました。そこで、スマートウォッチ、スマートフォン、ノートパソコン、その他のエッジデバイスに搭載できる小型の音声モデルを開発しました。ロボットのような声ではなく、人間らしい声を目指しています。価格は市場に出回っている他の製品と比べてかなり安価ですが、最先端の性能を提供します」と述べています。
また、今回公開されたモデルは「オープンウェイト」として提供されている点も大きな特徴です。これにより開発者はモデルを自由にダウンロードし、自分の環境で実行・改良することが可能なため「外部サービスに自身のボイスサンプルを送る」というようなプライバシー上の懸念がいらない点も特徴です。Voxtral TTSはHugging Faceからダウンロードできます。
mistralai/Voxtral-4B-TTS-2603 · Hugging Face
https://huggingface.co/mistralai/Voxtral-4B-TTS-2603
ストック氏はVoxtral TTSの次の展開について、2つの方向性を示しました。1つ目は言語と方言のサポートを拡大することで、特に文化的なニュアンスをすべて考慮して機能することを目標としています。2つ目の方向性は、テキストから音声を生成するだけでなく、話し言葉のイントネーションやリズム、話し方を理解して意図やニュアンスを読み取って応答するAIをMistral AIのビジョンとして掲げています。
・関連記事
Mistral AIが「Forge」をリリース、企業が独自知識を取り入れたAIモデルを簡単に構築するためのシステム - GIGAZINE
信頼できるAIコーディングを実現するためのオープンソース証明検証基盤「Leanstral」をMistral AIがリリース、重大なボトルネック「人間によるレビュー」の克服を目指す - GIGAZINE
Mistral AIが文字起こしAI「Voxtral Mini Transcribe V2」と「Voxtral Realtime」を発表 - GIGAZINE
Mistral AIが小型かつ高性能なオープンAIモデル「Devstral 2」とバイブコーディング用ツール「Mistral Vibe CLI」を公開 - GIGAZINE
・関連コンテンツ




You can read the machine translated English article Mistral AI has announced 'Voxtral TTS,' ….