




Appleが新たなマスコットキャラ「Little Finder Guy」をアピールしつつある

Appleの廉価版MacBook「MacBook Neo」のプロモーションでmacOSのファイル管理アプリ「Finder」を擬人化したキャラクターを登場させたところ、「Lil(Little) Finder Guy」という愛称で予想以上の人気を博していると報じられています。Lil Finder GuyはAppleが公開したTikTok動画にも登場し、さらに新作動画も公開されています。
Lil Finder Guy — Basic Apple Guy
https://basicappleguy.com/basicappleblog/lil-finder-guy
Apple Leans Into Little Finder Guy With New TikTok Videos - MacRumors
https://www.macrumors.com/2026/03/30/apple-tiktok-little-finder-guy/
FinderはAppleのファイル管理アプリで、Classic Mac OS時代から顔をイメージしたアイコンデザインとなっています。このFinderの顔アイコンはClassic Mac OSの起動画面にも表示されており、リンゴのロゴと並んでAppleを象徴するアイコンといえます。

そして、AppleはMacBook Neoを発表した3月上旬にTikTokの公式アカウントを開設。このTikTokに投稿されたMacBook Neoを紹介するコンテンツに、Finderの擬人化キャラクター「Lil Finder Guy」が登場し、人気を呼びました。

SNS上には二次創作も登場しています。
The Findies pic.twitter.com/CvuH0hspGD
— Andreas Storm (@avstorm) March 7, 2026
そして、Appleは2026年3月30日に、このLil Finder Guyが登場するムービーを新たに3本投稿しました。
動画では、Macデスクトップ上のスタック機能、動画アプリ用のリングライト、音声入力などが紹介されています。
チュートリアルはすべてMacBook Neoで行われ、それぞれにLil Finder Guyが登場します。動画へのコメントを見ると、そのほとんどはLil Finder Guyに関するものです。
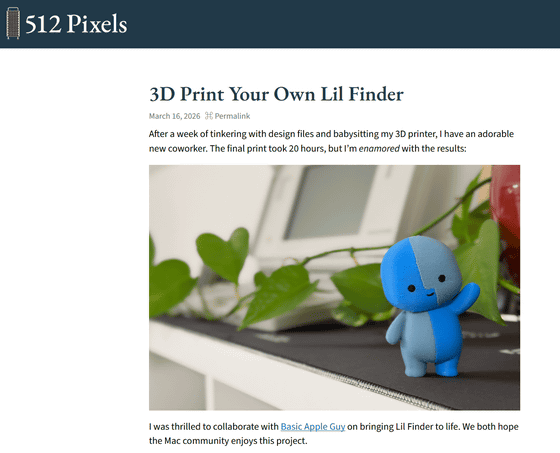
512 PixelsのStephen Hackett氏は、Little Finder Guyを3Dプリントするための.3mfファイルを配布しています。
3D Print Your Own Lil Finder - 512 Pixels
https://512pixels.net/2026/03/3d-print-lil-finder/
Apple関連ニュースを扱うMacRumorsは「Androidには以前から虫(Bug)と人型ロボット(Droid)を掛け合わせたような『ドロイド君(Bugdroid)』が存在していますが、今やAppleにもそれに相当するキャラクターが登場しました」と、Lil Finder Guyを歓迎しています。
・関連記事
Appleとアイコンの未来を切り開いたグラフィックデザイナーとは? - GIGAZINE
メニュー項目の横に添えられたアイコンは必要なのか? - GIGAZINE
Appleの「伝説的な細部へのこだわり」はmacOSやiOS 26で失われてしまったという指摘 - GIGAZINE
Androidに新機能追加&ロゴやドロイドくんの外観変更 - GIGAZINE
SamsungがAppleのFace IDアイコンを丸パクリしていると指摘される - GIGAZINE
・関連コンテンツ




in 動画, デザイン, Posted by log1i_yk
You can read the machine translated English article Apple is promoting its new mascot charac….