MarekさんはIPアドレスを詐称するIPスプーフィング攻撃を調査するため、パケットの地理的な経路が正当であるかを、画像のようなIPアドレスのリストから判断しようとしました。例えば、イタリアのプロバイダから送信されたパケットが、イタリアから遠く離れたブラジルのデータセンターを経由しているのは正当とは言えません。

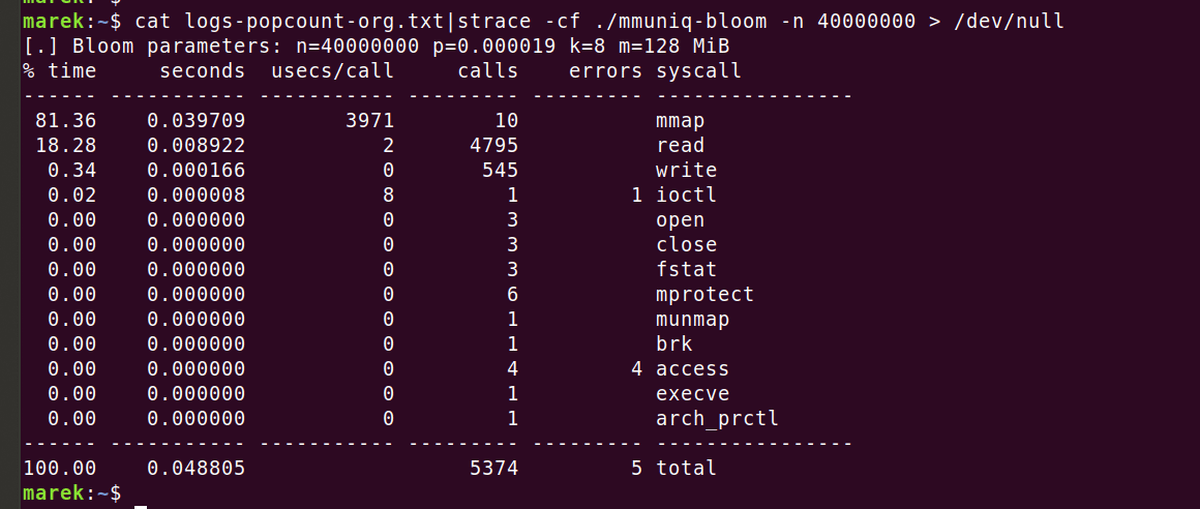
MarekさんがIPアドレスのリストを収集した結果、10億行ものリストができあがってしまったとのこと。普段はsortコマンドとuniqコマンドを組み合わせたBashのワンライナーでリストから重複を取り除くそうですが、ここまで膨大なリストは計算に時間がかかりすぎます。Marekさんの環境では、リストの行数が4000万行、容量が600MiBのファイルでも、スクリプト処理しようとすると2分以上かかってしまう計算結果に。

そんな時に思いついたのが「ブルームフィルタ」を使う方法。ブルームフィルタの動作はプログラミングで用いられるデータ型のひとつである「セット型」と基本的には同じで、1つのデータ構造に同じ要素があるかどうかを判定してくれる、計算効率がいいデータ構造です。確率に応じて「データが入っていないのに入っていると判定する」偽陽性は発生しますが、「データが入っているのに入っていないと判定する」偽陰性は起こりません。
ブルームフィルタはセット型と同じく、使用するハッシュ関数の衝突と、ビット配列を格納するメモリ容量による制限を受けます。ブルームフィルタは4つの変数を持っており、入力する要素数を表す「n」、ビット配列が使用するメモリ容量を表す「m」、ハッシュ関数の数を表す「k」、偽陽性の起こる確率を表す「p」で構成されています。下記サイトを使うと、指定する要素数と偽陽性の確率から適切なメモリ容量とハッシュ関数の数を求めることができます。
Bloom filter calculator
https://hur.st/bloomfilter/
Marekさんはブルームフィルタを用いて、C言語で「mmuniq-bloom」というプログラムを実装。4つの変数を引数として指定できます。
cloudflare-blog/mmuniq-bloom.c at master · cloudflare/cloudflare-blog · GitHub
https://github.com/cloudflare/cloudflare-blog/blob/master/2020-02-mmuniq/mmuniq-bloom.c
さっそくmmuniq-bloomを用いてリストを処理した場合にかかる時間を計算してみると、およそ12秒という結果に。sortコマンドとuniqコマンドを使用した場合にかかる時間である2分と比較すると大きな進歩ですが……

改行の数を出力する「wc -l」コマンドは0.4秒ほどで完了する計算でした。mmuniq-bloomは計算効率のいいブルームフィルタを使っているにも関わらず、12秒という計算時間はMarekさんの満足のいくものではありませんでした。

ブルームフィルタの処理を省いてプログラムを実行してみると、実行速度は2秒ほどに縮まりました。つまり、ブルームフィルタの処理だけで10秒ほどかかっていることになります。
![]()
プログラムの動作を確認するため、straceコマンドを使ってシステム呼出しを監視してみましたが、目立った異常は見られませんでした。
![]()
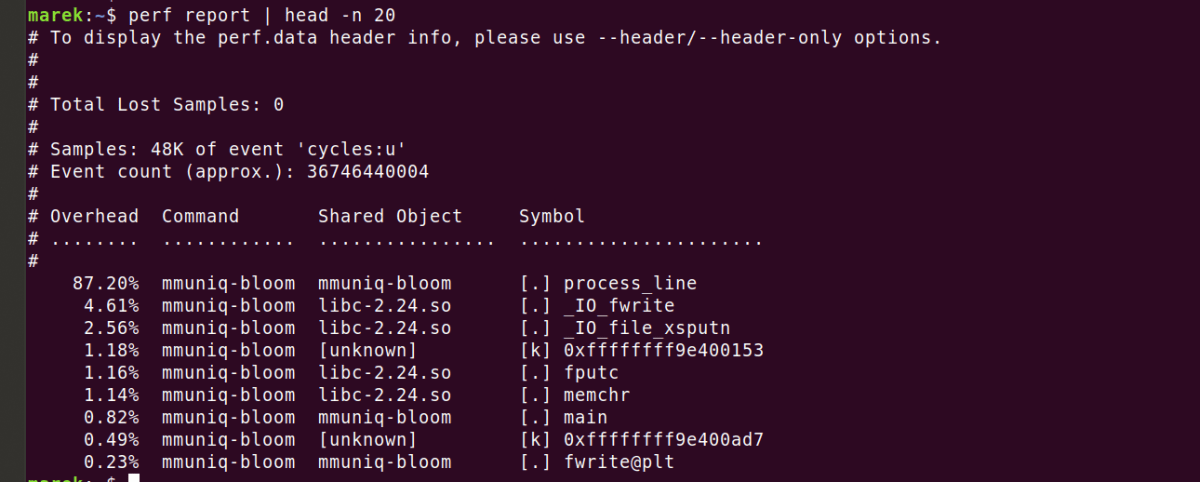
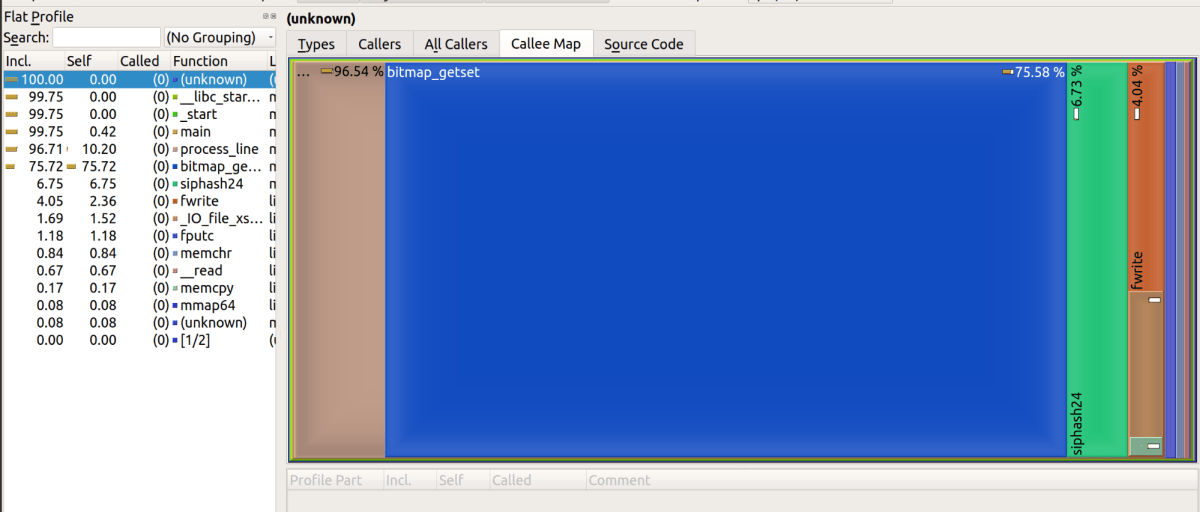
続いてperfコマンドで性能を解析すると、mmuniq-bloomのprocess_line関数が87.2%もCPUリソースを消費していることが判明。
![]()
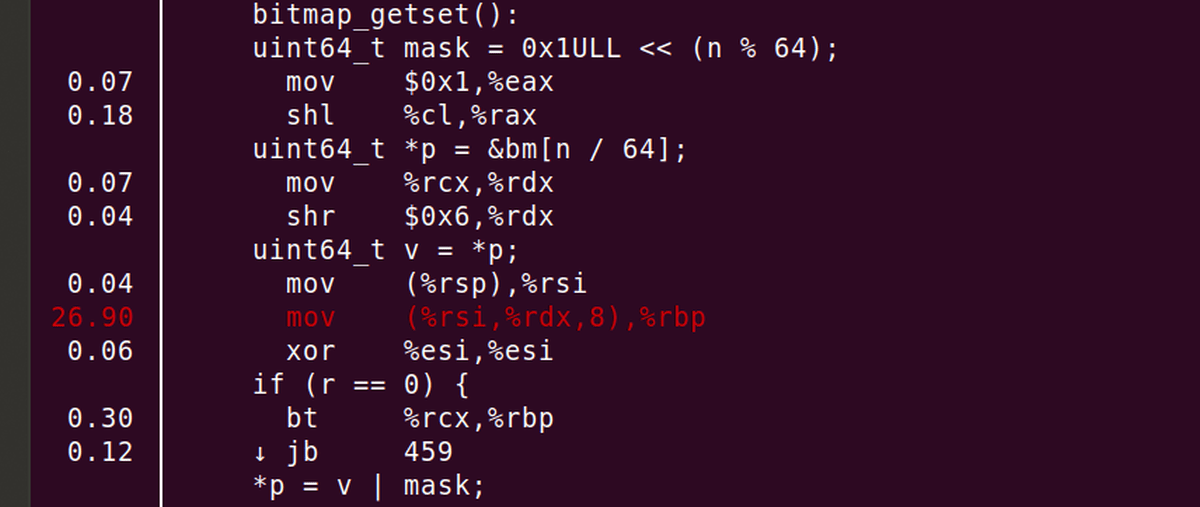
さらに詳しく解析すると、データを複写するアセンブラ命令である「MOV命令」がリソースを消費していることが明るみに。
![]()
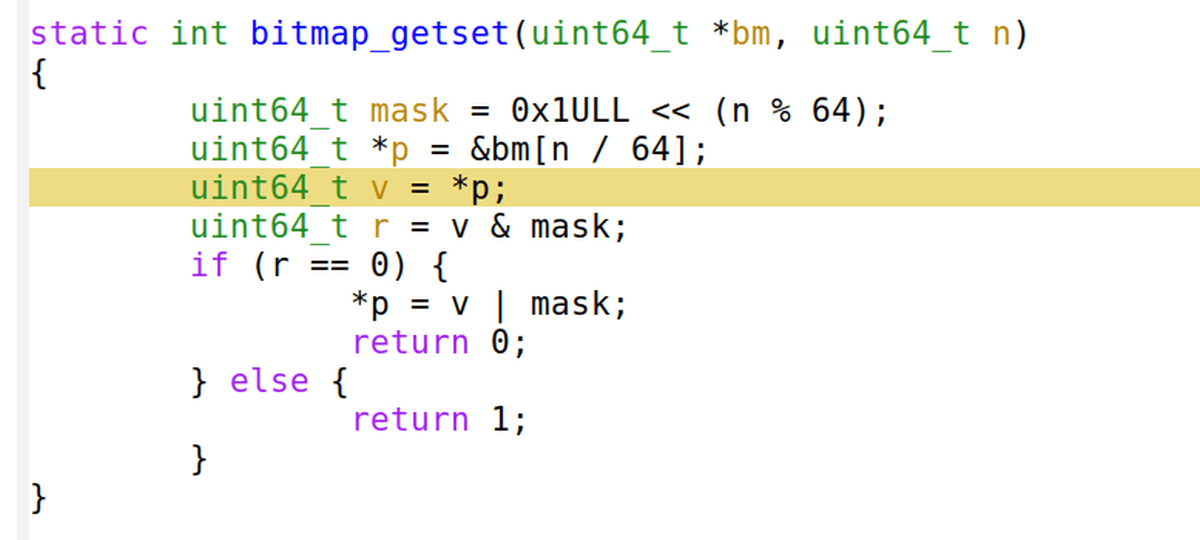
コンパイル後にMOV命令を使用する「uint64_t v = *p」というソースコードの部分がプログラムの処理サイクルの大部分を占めていることになります。
![]()
perfと同じ性能解析ツールである「google-perftools」でも検証してみましたが、やはり「uint64_t v = *p」を含むbitmap_getset関数のリソース消費が多いという結果に。
![]()
改行を数える「wc -l」の動作は速いのに、mmuniq-bloomは遅い、ということを改めて振り返ったMarekさんは「ブルームフィルタはランダムアクセスを使用しており、その速度が非常に遅い」という結論に到達します。
ランダムアクセスメモリー(RAM)からの一回のフェッチにかかる速度は100ナノ秒とされているので、4000万行のリストを8つのハッシュ値でハッシュ化したデータを読み出すには、32秒もかかる計算になります。
![]()
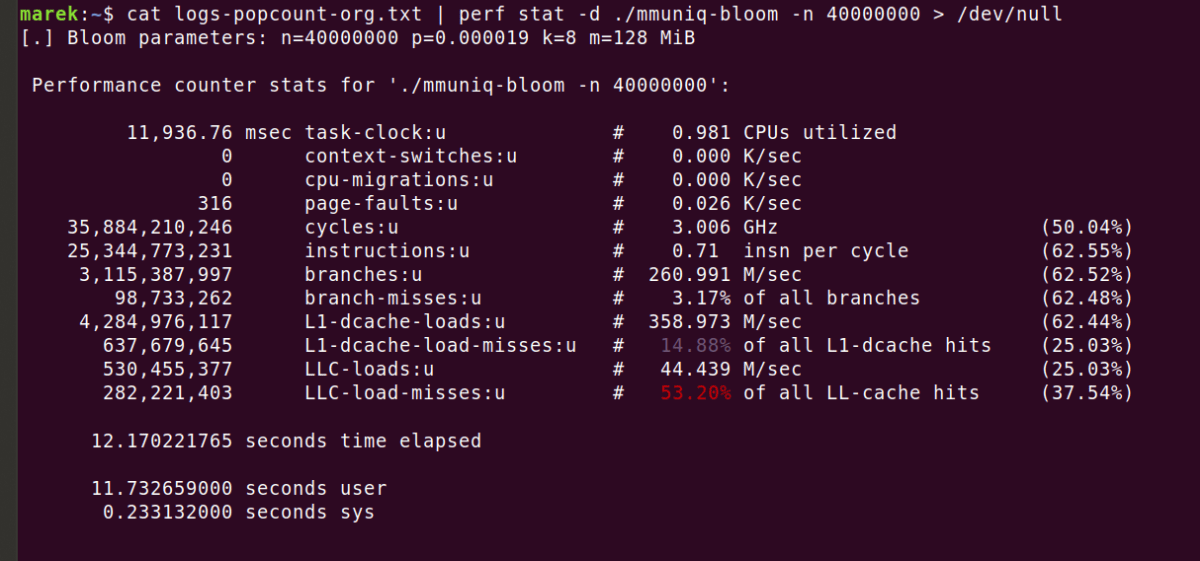
また、作成したブルームフィルタのビット配列として使用するメモリ容量は128MiBであったため、高速なメモリーであるCPUのL3キャッシュにはビット配列が収まらなかったとのこと。perfコマンドによる性能測定を確認してみると、最終レベルのキャッシュのロードミスを表す「LLC-load-misses」が発生していることがわかります。
![]()
Marekさんの同僚はしばしば「現代のCPUの計算速度は無限大と考えていい。メモリーの読み込み速度の壁にぶち当たるまでは」と口にしているそう。現代のCPUは記憶媒体を端から順に読み込むシーケンシャルアクセスは得意ですが、ランダムアクセスは苦手としているとのこと。ブルームフィルタのようなデータ構造を使用するときは、CPUのキャッシュにそのデータ構造が収まるかどうか確認する必要があるとMarekさんは語っています。