``Random access'' may be the cause of abnormally slow program operation.

When programming, it is necessary to consider factors such as choosing a language according to the purpose, the beauty of coding, and the cost of calculation. However,
When Bloom filters don't bloom
https://blog.cloudflare.com/when-bloom-filters-dont-bloom/
In order to investigate IP spoofing attacks that spoof IP addresses, Marek tried to determine whether a packet's geographical route is legitimate from a list of IP addresses like the one in the image. For example, it would not be legitimate for a packet sent by an Italian provider to go through a data center in Brazil, which is far away from Italy.

Marek collected a list of IP addresses and ended up with a list of 1 billion lines. Usually, duplicates are removed from a list using a Bash

That's when I came up with the idea of using
Like the set type, Bloom filters are limited by the collision of hash functions used and the memory capacity for storing bit arrays. A Bloom filter has four variables: 'n' representing the number of input elements, 'm' representing the memory capacity used by the bit array , 'k' representing the number of hash functions, and the probability of false positives occurring. It is made up of 'p' which stands for 'p'. Using the site below, you can find the appropriate memory capacity and number of hash functions from the specified number of elements and the probability of false positives.
Bloom filter calculator
https://hur.st/bloomfilter/
Marek implemented a program called ``mmuniq-bloom'' in C language using a bloom filter. You can specify four variables as arguments.
cloudflare-blog/mmuniq-bloom.c at master · cloudflare/cloudflare-blog · GitHub
https://github.com/cloudflare/cloudflare-blog/blob/master/2020-02-mmuniq/mmuniq-bloom.c
I immediately calculated the time it would take to process the list using mmuniq-bloom, and found that it was approximately 12 seconds. This is a big improvement compared to the 2 minutes it takes when using the sort and uniq commands...

The 'wc -l' command that outputs the number of line breaks was calculated to complete in about 0.4 seconds. Even though mmuniq-bloom uses a bloom filter with high computational efficiency, Marek was not satisfied with the calculation time of 12 seconds.

When I ran the program without Bloom filter processing, the execution speed was reduced to about 2 seconds. In other words, Bloom filter processing alone takes about 10 seconds.

In order to check the operation of the program, I used
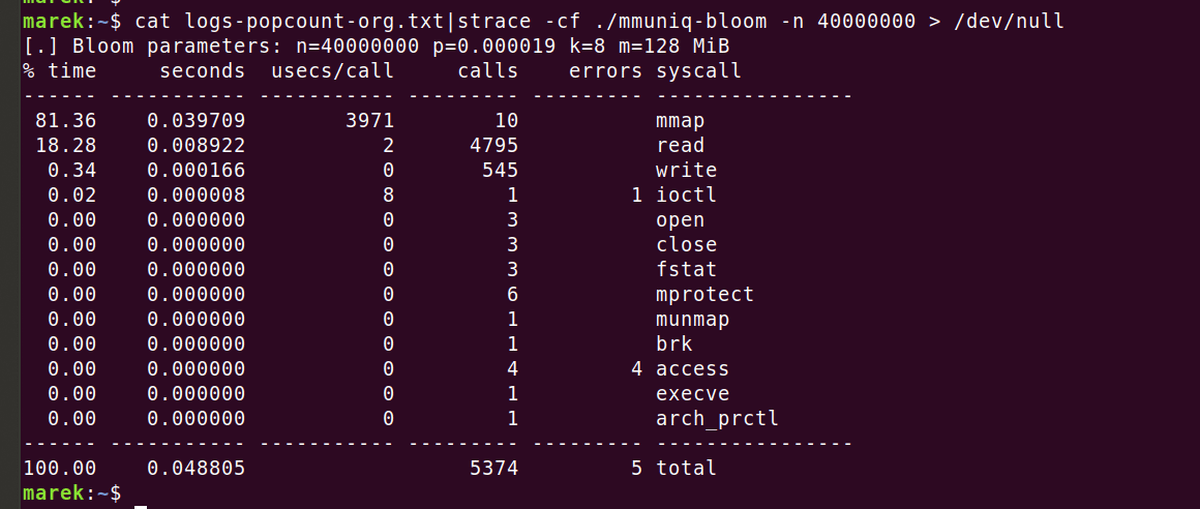
Next, when we analyzed the performance using
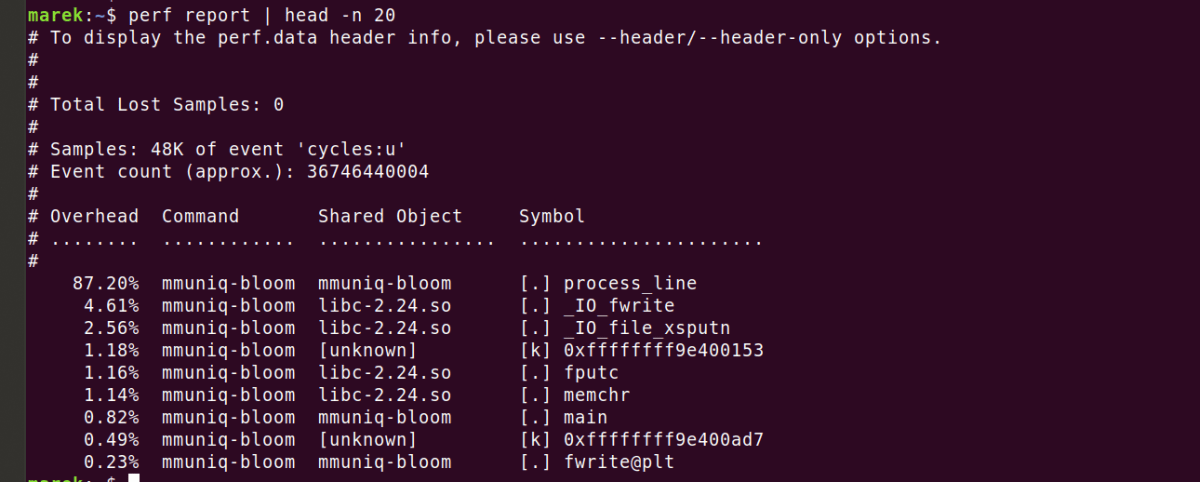
Further analysis revealed that the ``MOV instruction'', an assembler instruction that copies data, was consuming resources.
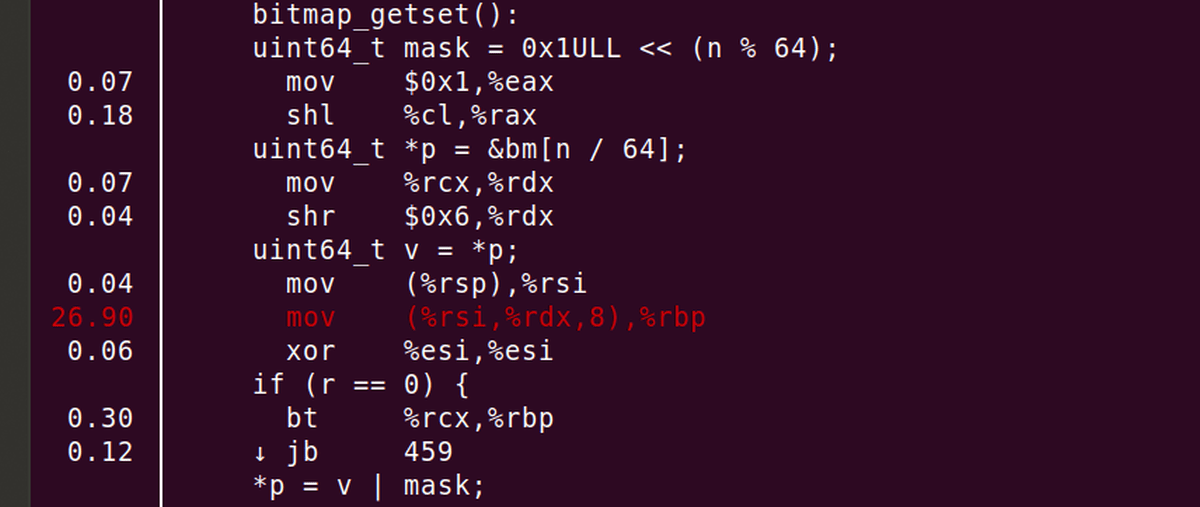
After compilation, the part of the source code that uses the MOV instruction 'uint64_t v = *p' occupies most of the program's processing cycles.
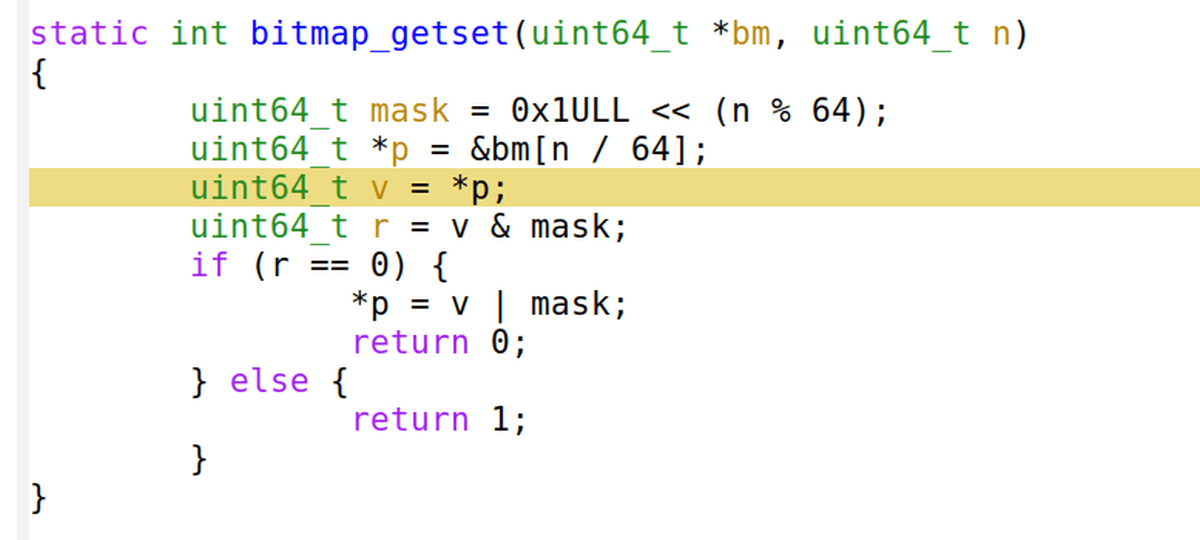
I also tested it with '
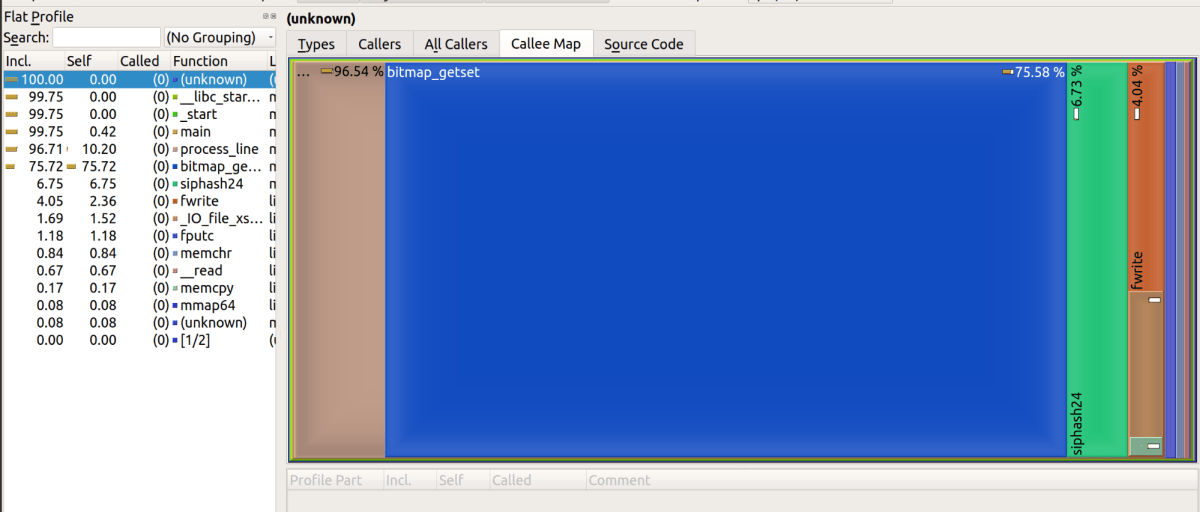
Looking back on the fact that ``wc -l'', which counts line breaks, is fast, mmuniq-bloom is slow, Marek says, ``Bloom filter uses
The speed of one fetch from random access memory (RAM) is said to be 100 nanoseconds, so it would take 32 seconds to read a list of 40 million rows hashed with 8 hash values. It will be.

Also, since the memory capacity used as the bit array of the created Bloom filter was 128MiB, the bit array could not fit into the CPU's L3 cache, which is a high-speed memory. If you check the performance measurement using the perf command, you will see that 'LLC-load-misses', which indicates a load miss of the final level cache, is occurring.
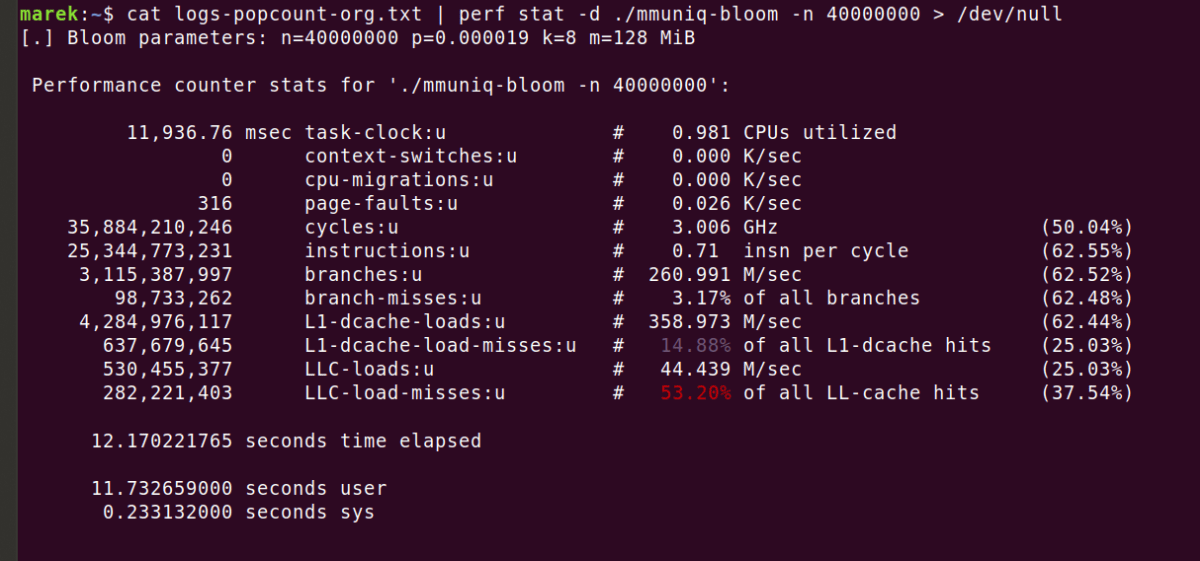
Marek's colleagues often say, ``You can think of the computational speed of modern CPUs as infinite, until you hit the wall of memory read speed .'' Modern CPUs are good at sequential access , which reads a storage medium sequentially from the end, but are weak at random access . Marek says that when using a data structure like a Bloom filter, you need to check whether the data structure will fit in the CPU's cache.
Related Posts:







in Free Member, Software, Posted by darkhorse_log