




PDFからテキストを抽出するのはなぜ難しいのか?

PDFファイルは、どんな環境のPCでもテキストや画像の表示を崩すことなく見られるデータ形式です。しかし、PDFからテキストデータをコピーしようとすると、うまく選択できなかったり、テキストの内容がおかしくなってしまったりすることがあります。なぜPDFファイルからのテキスト抽出が難しいのかを、PDFファイルのテキスト化およびデータベース作成を行う団体、FilingDBが報告しています。
PDF text extraction | FilingDB
https://www.filingdb.com/pdf-text-extraction
◆読み取り保護
PDFファイルの中には内容が保護されているものが存在します。テキスト自体は正しく表示されていても、テキストをコピーしようとすると「Copying text was denied (テキストのコピーが拒否されました)」といった内容が表示され、テキストの抽出ができないようになっています。

なぜコピーができないのかというと、PDFファイルに、テキストのコピーを許可するかどうかを決める「アクセス許可」の設定がされているためです。この設定によって、PDFは問題なく表示されていても、PDFビューアーがテキストのコピーを禁止してしまいます。
◆ページ外の文字
PDFファイルには、ページに実際に表示されているよりも多くのテキストデータが含まれることがあります。以下の画像はネスレの2010年における年次報告書のPDFファイルです。
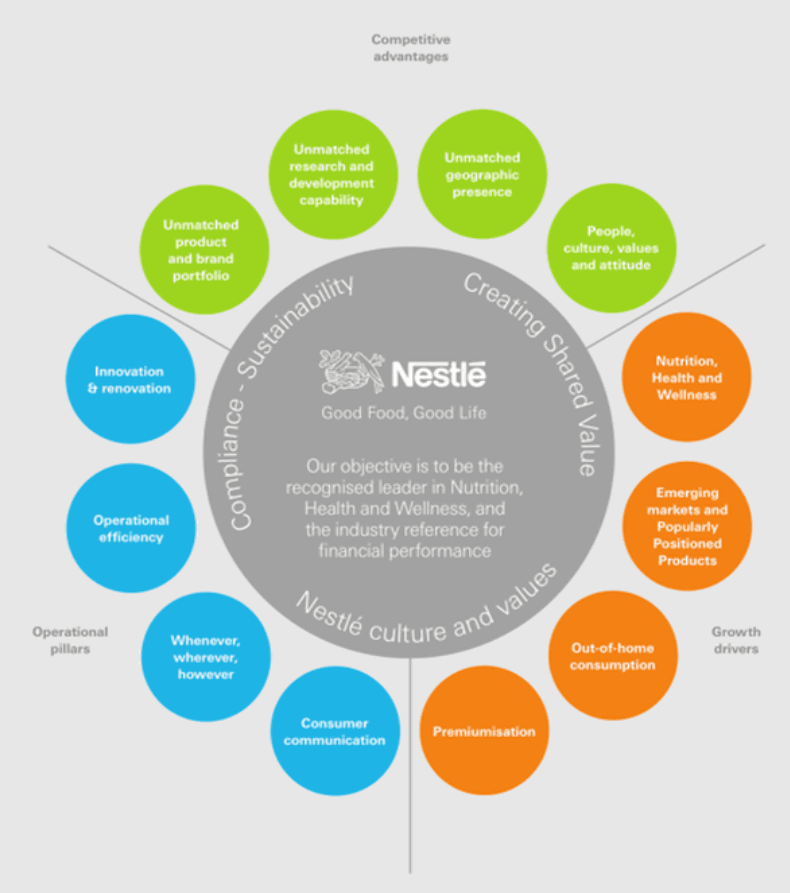
上記のファイルには、ページ上に表示されていない「キットカットは2010年に創立75周年を迎えました。まだ若く、トレンドにも敏感で、Facebookでは250万人以上のファンを抱えています。70カ国以上で販売され、先進国および中東、インド、ロシアなどの新興市場でも高い成長を遂げています。日本は二番目に大きな市場です」というテキストが存在していました。
このテキストは、実際にはページの枠外に配置されていたので、ほとんどのPDFビューアでは表示されません。しかし、作成者がデータを消し忘れたためか、データ自体は残っており、ページ全体のテキストを抽出すると表示されてしまいます。
◆小さすぎる文字と見えない文字
PDFファイルには、非常に小さいテキストや非表示のテキストが存在することがあります。例えば、ネスレの2012年における年次報告書のテキストでは、白い背景に小さな白いテキスト「Wyeth Nutrition logo Identity Guidance to markets」「Vevey Octobre2012RCC/CI&D」が表示されます。こういったテキストは、テキスト作成時のメモ書きや、検索のしやすさのために挿入された可能性があります。

◆余分なスペース
PDFファイルのテキストデータには、単語の文字間に余分なスペースが含まれることがあります。これはほとんどの場合、文字間の距離を調整するカーニングという処理のために発生します。
例えば、2013年におけるHikma Pharmaceuticalsの年次報告書では、赤枠部分のテキストをコピーすると「CH A I R M A N ' S S TAT EM EN T」という風に、不要なスペースを含んだ状態でコピーされ、単語がバラバラになってしまう場合があります。

◆スペースの消失
不要なスペースが含まれるだけでなく、もともとあったスペースがなくなったり、スペースが違う文字に置き換えられたりしてしまう場合もあります。例えば、以下の2017年におけるSEBの年次報告書からの抜粋で「Ten years after the financial crisis started(金融危機対策を開始した)」という文章をコピーすると、「Tenyearsafterthefinancialcrisisstarted」という風にスペースが消えた状態でコピーされてしまう場合があります。

また、以下の2013年におけるユーロ銀行の年次報告書では、「On April 7, 2013, the competent authorities(2013年4月7日 管轄官庁)」というテキストをコピーすると、スペースがアンダーバーに置き換わり「On_April_7,_2013,_the_competent_authorities」となってしまう場合もあります。

余分なスペースおよびスペースの消失については、PDFビューアーでテキストをコピーするよりも、光学文字認識(OCR)でテキストに変換する方が効率的です。
◆埋め込みフォント
PDFにおけるフォントの処理は複雑です。PDF文書によっては非標準フォントや独自のエンコーディングが含まれている場合があり、テキストを違った文字として表示したり、PDFファイル上でテキストではなく画像データとして認識されていたりする場合があるため、テキストの抽出がより困難になります。
◆テキストと段落の順序
段落の順序を抽出するのは、2つの点で難しいとされています。まず、正解がない場合があります。例えば、以下の赤枠部分にあるテキストは、ページ全体の文章の最後に挿入するべきか、または文章の途中に表示するかは不明で、テキストを作った本人にしか分からない場合がほとんどです。

そして、読書は左から右、上から下の順に読むのが基本ですが、以下のような段落の分かれ方では、A B C Dという順番が正しいのか、A C B Dという順番が正しいのかは分かりません。人間の脳であれば、テキストを読んで、何が書いてあるのかを理解することで正しい順序を判断できます。しかしプログラムのアルゴリズムで正しい順序を判断するのは難しい問題です。

段落の順序に対しては、テキストがPDFファイルに格納された順序を参照するというアプローチがよく用いられています。
◆埋め込みイメージ
PDFファイルに変換された内容全てが、テキストデータではなく画像データとして保存されてしまう場合も多くあります。このような場合、直接抽出できるテキストデータがないため、OCRに頼らざるを得ません。
例えば、以下の2011年におけるYELLの年次報告書のようなPDFファイルは、テキストデータではなく、全て画像データとしてPDFファイルに保存されています。

FilingDBが挙げた問題について、ほとんどはOCRで解決することができますが、OCRにもいくつか欠点があります。まず、OCRによるスキャンは、PDFファイルからテキストを直接抽出する場合よりも十数倍長い時間がかかります。また、OCRでは、顔文字や、複雑な数学記号などの文字を扱えない場合があり、PDFファイルのように、挿入された順序を参照してテキストの順序付けを行うこともできません。
そもそも、PDFファイルはテキストエディタのようなデータ入力フォーマットとして設計されたのではなく、ドキュメントを精密に出力するデータ出力フォーマットとして設計されたものです。PDFファイルはテキスト抽出には不向きな形式であり、FilingDBは、PDFファイルからテキストを抽出する前に、他のフォーマットでデータが提供されていないかどうかを確認することを推奨しています。
・関連記事
無料でウェブページやPDFを保存し複数端末で同期してオフライン閲覧可能にする「POLAR」を使ってみた - GIGAZINE
PDFファイルには目に見えないデータがたくさん眠っている - GIGAZINE
なぜPDFでサイトを表示するべきではないのか? - GIGAZINE
本を完璧にデジタル化するため6年の歳月と情熱をつぎ込んで完成した自炊マシン「Archivist」 - GIGAZINE
本のページを切断・裁断せずに済む「非破壊自炊」とは? - GIGAZINE
・関連コンテンツ




in メモ, Posted by darkhorse_log
You can read the machine translated English article Why is it difficult to extract text from….