Why is it difficult to extract text from PDF?

A PDF file is a data format that can be viewed on a PC in any environment without breaking the display of text and images. However, if you try to copy text data from PDF, you may not be able to select it properly, or the text content may be incorrect.
PDF text extraction | FilingDB
https://www.filingdb.com/pdf-text-extraction
◆ Read protection
Some PDF files have protected content. Even if the text itself is displayed correctly, if you try to copy the text, a message such as 'Copying text was denied' is displayed, and the text cannot be extracted.

The reason why copying is not possible is that the PDF file has 'permissions' that determine whether text copying is allowed. This setting prevents the PDF viewer from copying text even if the PDF is displayed without any problems.
◆ Off-page characters
PDF files may contain more text data than is actually displayed on the page. The image below is a PDF file of Nestlé's 2010 Annual Report.
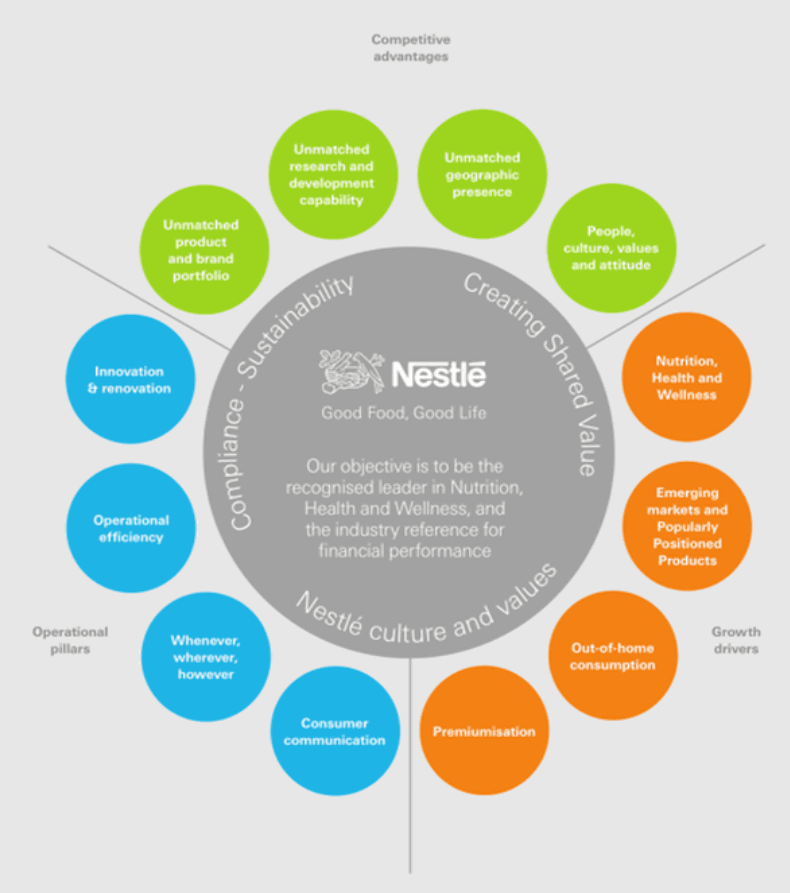
The file above does not show on the page that 'KitKat celebrated its 75th anniversary in 2010. It is still young, sensitive to trends and has more than 2.5 million fans on Facebook. It is sold in more than 70 countries and is also experiencing strong growth in developed countries and emerging markets such as the Middle East, India, and Russia. Japan is the second largest market. '
This text is not displayed in most PDF viewers because it was actually placed outside the page border. However, because the creator forgot to erase the data, the data itself remains, and it will be displayed when extracting the text of the entire page.
◆ Too small and invisible characters
PDF files can contain very small or hidden text. For example, the text of Nestlé's 2012 Annual Report shows a small white text 'Wyeth Nutrition logo Identity Guidance to markets' and 'Vevey Octobre2012RCC / CI & D' on a white background. These texts may have been inserted into the notes when creating the text or for ease of searching.

◆ Extra space
Text data in PDF files may contain extra spaces between the letters of a word. This most often occurs because of a process called
For example, in the annual report of Hikma Pharmaceuticals in 2013, if you copy the text in the red frame part, it will be copied with unnecessary spaces like `` CH AIRMAN 'SS TAT EM EN T' ', and the words will be separated It may become.

◆ Loss of space
In addition to containing unnecessary space, the original space may be lost or replaced with a different character. For example, if you copy the text `` Ten years after the financial crisis started '' in the following excerpt from the 2017 SEB's annual report, the space disappeared as `` Tenyearsafterthefinancialcrisisstarted '' It may be copied in a state.

Also, in the following 2013 Eurobank report, if you copy the text 'On April 7, 2013, the competent authorities', the space is replaced by an underscore and 'On_April_7 , _2013, _the_competent_authorities '.

For extra space and lost space, converting to text with
◆ Embedded font
Handling fonts in PDF is complex. Some PDF documents may contain non-standard fonts or proprietary encodings, which may cause text to be displayed as different characters or may be recognized as image data instead of text in PDF files, Extracting text becomes more difficult.
◆ Text and paragraph order
Extracting paragraph order is difficult in two respects. First, there may not be a correct answer. For example, it is unclear whether the text in the red frame below should be inserted at the end of the sentence on the entire page or displayed in the middle of the sentence, and it is often unknown only to the person who created the text.

And reading is basically from left to right and from top to bottom, but it is not clear whether the order of ABCD or ACBD is correct in the following paragraph division. The human brain can determine the correct order by reading the text and understanding what is being written. However, it is difficult to determine the correct order with the algorithm of the program.

A common approach to paragraph order is to refer to the order in which the text is stored in the PDF file.
◆ Embedded image
In many cases, all the contents converted to a PDF file are saved as image data instead of text data. In such cases, there is no text data that can be directly extracted, so you have to rely on OCR.
For example, PDF files such as the following YELL's annual report for 2011 below are all stored in PDF files as image data, not text data.

Most of the issues raised by FilingDB can be solved with OCR, but OCR also has some drawbacks. First, scanning with OCR takes ten times longer than extracting text directly from a PDF file. In addition, OCR may not be able to handle characters such as emoticons or complicated mathematical symbols, and it is not possible to order text by referring to the insertion order like PDF files.
In the first place, PDF files are not designed as a data input format like a text editor, but as a data output format that outputs documents precisely. PDF files are a poor format for text extraction, and FilingDB recommends that you check for data in other formats before extracting text from PDF files.
Related Posts:


in Note, Posted by darkhorse_log