




Googleの新たな自然言語処理AI「T5」の特徴とは?実際にAIとクイズで対決も可能

Googleの新たな自然言語処理モデル「T5」は、ある領域の学習済みモデルを別の領域に転用する「転移学習」を利用した機械学習モデルであり、多くの自然言語処理ベンチマークで最も高いスコアを残しています。そのT5の特徴と能力をGoogleが解説しており、実際にT5とクイズで対決できるウェブサイトも公開されています。
Google AI Blog: Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer
https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
T5 trivia
https://t5-trivia.glitch.me/
Googleが発表した論文である「Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer」の中で、新しい自然言語処理モデルであるT5が登場しました。同じくGoogleによって開発されたBERTがクラスラベルや入力の範囲など、人間が言語としてそのまま理解できないデータしか出力できないのに対し、T5は入力と出力が常にテキスト形式になるように自然言語処理タスクを再構成するため、機械翻訳や文書要約に柔軟に対応することが可能であるとのこと。
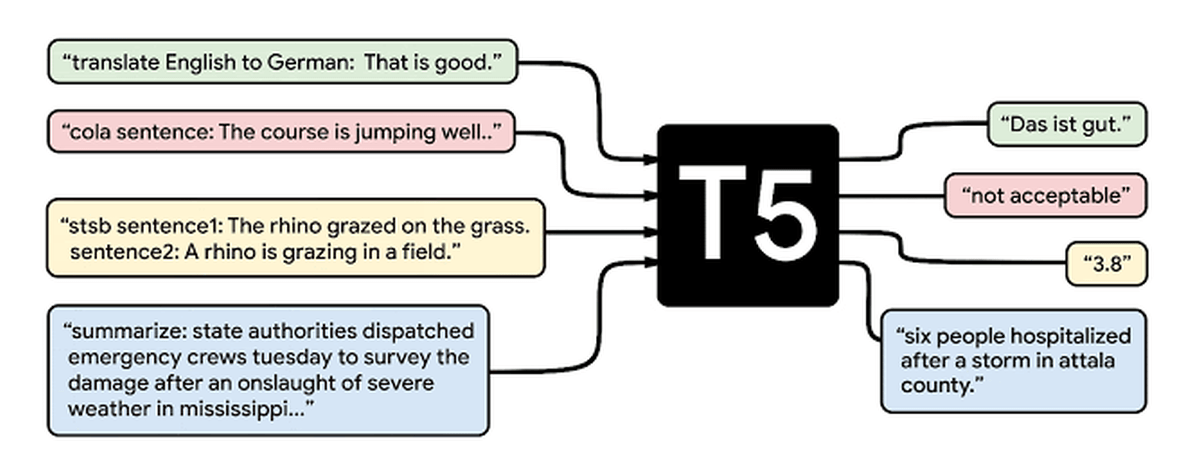
T5の性能を支えているのは「C4」と呼ばれるデータセットです。Googleが開発したこのデータセットは、ウェブスクレイピングによって用意されたデータセットである「Common Crawl」から重複や不完全な文章、過激な内容、ノイズを除去することで、110億のパラメーターを持つデータセットの巨大さを確保しつつ、高品質かつ多様性が担保されたものとなっているとのこと。C4は機械学習プラットフォーム「TensorFlow」に公開されており、誰でも利用することができます。
c4 | TensorFlow Datasets
https://www.tensorflow.org/datasets/catalog/c4
T5を開発するにあたり、Googleがこれまでの転移学習による自然言語処理モデルの実装方法を調査したところ、以下のような洞察が得られました。以下のような洞察と学習に使用するC4データセットの大きさが、数多くのベンチマークで最高得点をたたき出す結果につながっているとのこと。
モデル構造:一般的に、デコーダーのみのモデルよりもエンコーダー・デコーダーモデルのほうが性能が高い。
事前学習の目標:ブランクのある不完全な文章を用いた穴埋め形式の学習が、計算コストの面で最もパフォーマンスが高い。
未ラベルデータセット:小さなデータセットによる事前学習は有害な過剰適合につながる可能性がある。
学習戦略:マルチタスク学習はそれぞれのタスクを学習させる頻度を慎重に検討する必要がある。
規模:事前学習に使うモデルの大きさ、学習にかける時間、アンサンブル学習に利用するモデルの数を比較し、限られた計算リソースを最も効率よく使用する方法を決める。
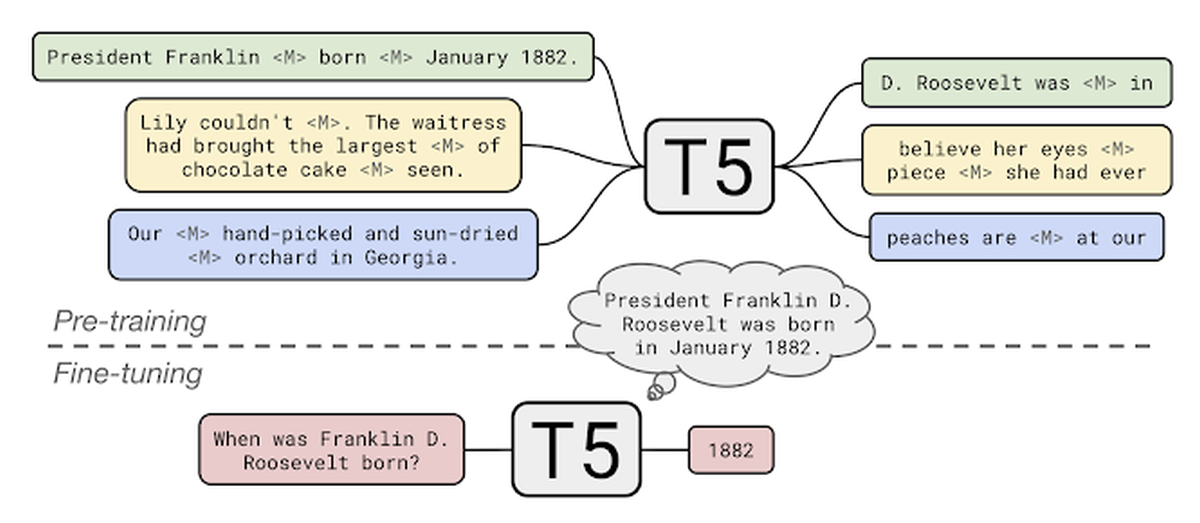
T5には革新的な2つの能力が備わっており、その1つが「未知の質問に対する回答」です。T5は事前学習において、質問と質問に答えるための背景を与えられ、その背景を考慮に入れて質問に回答するようにトレーニングされています。例えば「ハリケーンのコニーはいつ発生したか」という質問と、Wikipediaのコニーに関する記事を同時に与えると、T5は記事内の日付である「1955年8月3日」を見つけるようにトレーニングされています。また、T5は外部のデータにアクセスすることなく事前学習時にインプットされたデータのみを元にして質問に回答する、自分の「知識」を頼りにする自然言語処理モデルです。
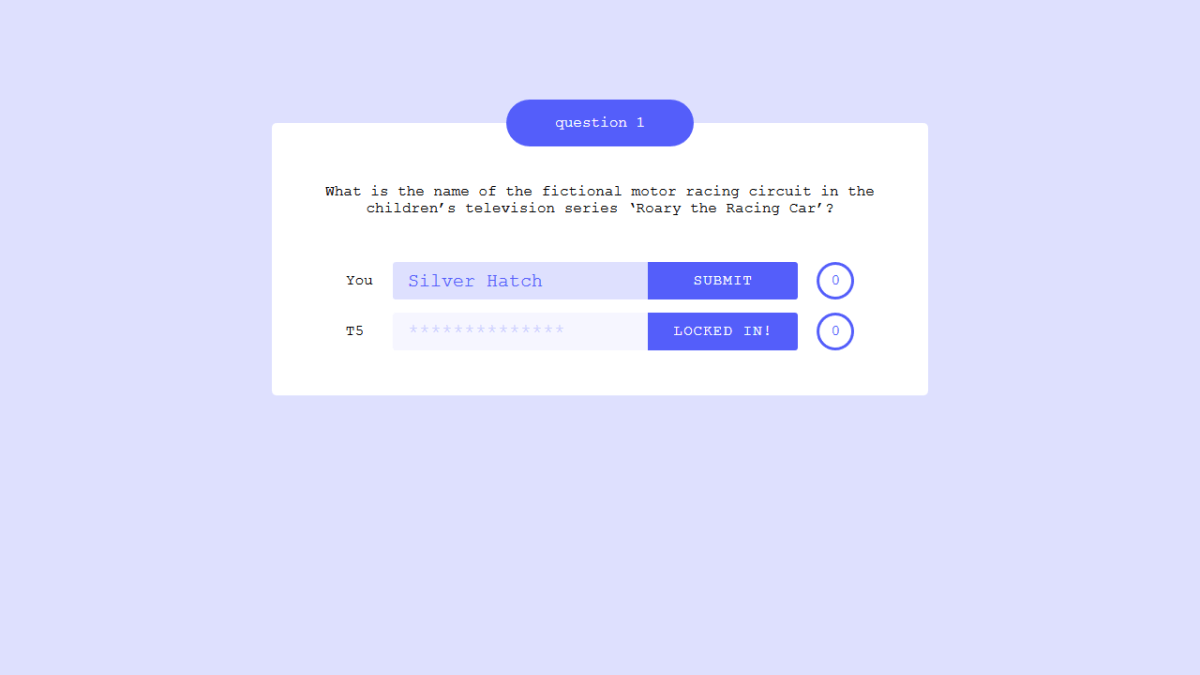
下記URLにアクセスすることで、実際にT5とクイズ対決をすることが可能です。
T5 trivia
https://t5-trivia.glitch.me/
「Roary the Racing Carに出てくる架空のサーキットの名称は?」という質問。答えは実在するイギリスのサーキット「Silverstone」と「Brands Hatch」を合わせた「Silver Hatch」ですが……
T5は「Isle of Man TT(マン島TTレース)」と誤答しました。回答は間違いではありますが、モータースポーツを連想した回答であることがうかがえます。
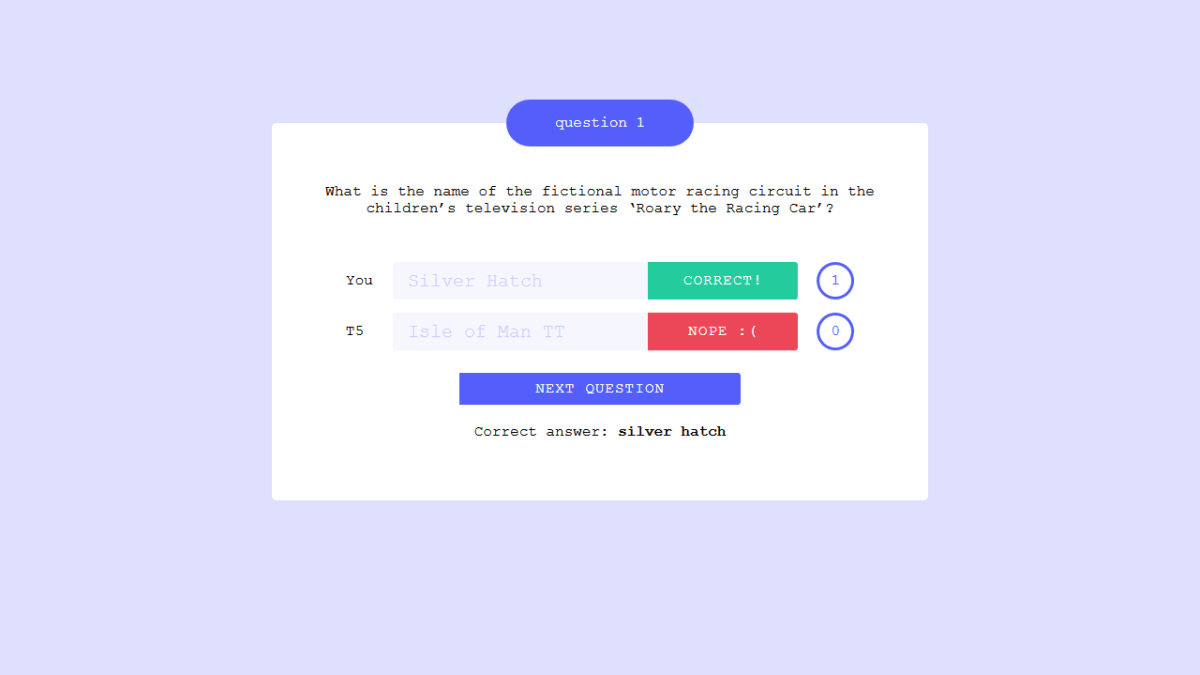
「衛星パンドラを舞台にした映画は?」という質問の回答は「Avater(アバター)」です。
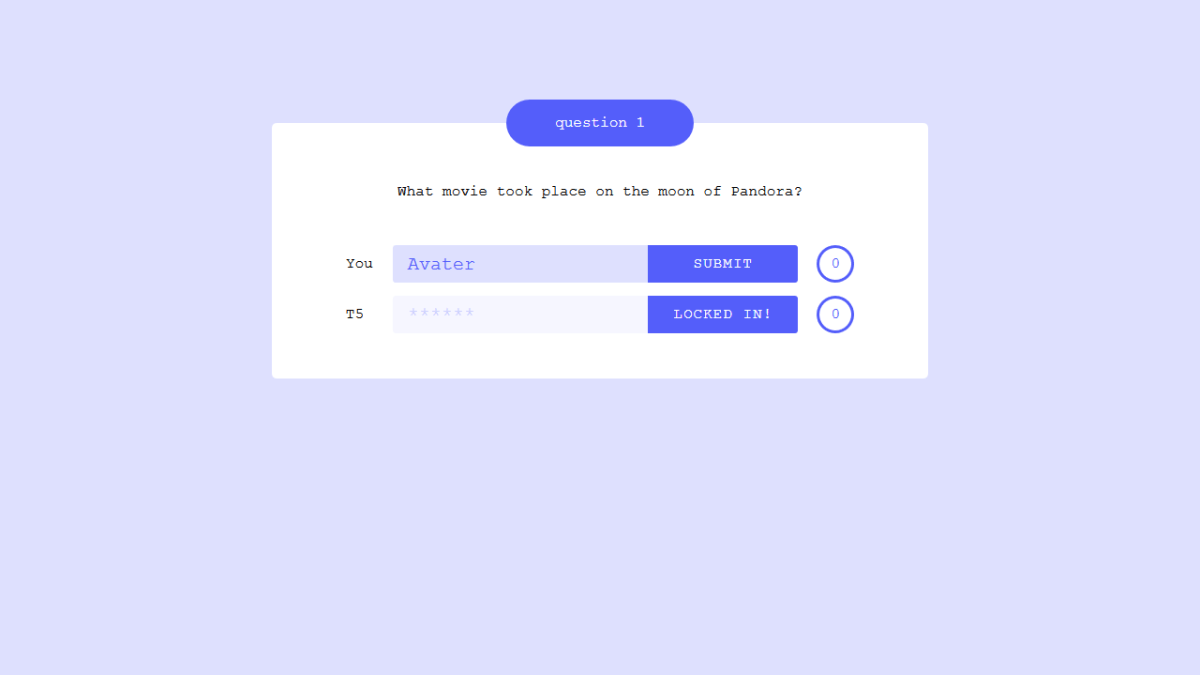
こちらはきっちり正解してきました。質問に対する回答の精度を測ることができるTriviaQA、WebQuestions、Natural Questionsの3つのベンチマークでそれぞれ50.1%、37.4%、34.5%の正答率を記録し、T5の開発チームはT5にクイズ対決で敗北してしまったそうです。

2つめの革新的な能力は「ブランクの大きさの変化に対応できる穴埋め問題の解決」です。「危険すぎる」と話題になった文章生成AI「GPT-2」は、文章の次に来るべき単語を予測するように学習していますが、T5の事前学習方法である穴埋め形式の学習も、ブランクの大きさを変化させることでさまざまな長さの文章を生成できるとのこと。ブランクの大きさをNとし、「I love peanut butter and (ブランク) sandwiches.」という文章を入力した例が公開されています。
N=1では、「I love peanut butter and jelly sandwiches.(私はピーナッツバターとジェリーのサンドイッチが好きです)」という文章になりました。

N=32では、「I love peanut butter and banana sandwiches and the Peanut Butter Chocolate Chip Cookie Bites are now very easy to prepare. The best part is that the PB&J Cookie Bites are the perfect size for kid lunch boxes and everyone will enjoy them. Kids love these sandwiches.(私はピーナッツバターとバナナのサンドイッチがとても好きで、ピーナッツバターチョコレートチップクッキーは今は用意するのがとても簡単です。ピーナッツバターとゼリーのクッキーは子ども用のランチボックスにちょうどいいサイズなのが最高で、みんなそれを楽しんでくれると思います。子どもたちはそれらのサンドイッチがとても好きです)」という文章が生成されました。さらに大きいブランクを選択すれば、より長い文章も生成可能です。

T5のソースコードはGitHub上に公開されており、誰でも利用することができます。
GitHub - google-research/text-to-text-transfer-transformer: Code for the paper "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer"
https://github.com/google-research/text-to-text-transfer-transformer
・関連記事
Googleが自然言語処理の弱点「言い換え」を克服するデータセットを公開 - GIGAZINE
Googleの自然言語処理モデル「BERT」はインターネット上から偏見を吸収してしまうという指摘 - GIGAZINE
Googleの新たな自然言語処理モデル「ALBERT」はどのように進化したのか? - GIGAZINE
AIが前衛的で不気味な絵画を延々と描き続けるサイト「Art42」 - GIGAZINE
実際のところ「AIが表情から感情を読み取る」ことは可能なのか? - GIGAZINE
・関連コンテンツ







in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article What are the features of Google's ne….