




劇場アニメ『楽園追放 心のレゾナンス』テクニカルミーティングレポート、「3Dの顔をどこから見ても可愛くする」「Mayaでエフェクトを組み上げる苦労話」など盛りだくさんの内容

2026年11月13日に公開予定の劇場アニメ『楽園追放 心のレゾナンス』について水島精二監督を含む制作陣が語るトークイベント「『楽園追放 心のレゾナンス』テクニカルミーティング」が2026年5月17日にマチ★アソビ vol.30の一部として実施されました。「3Dモデルの顔をどこから見ても可愛く見えるように調整する」といったフル3Dアニメを作る上で重要な要素が惜しみなく語られたイベントの様子をまとめてみました。
マチ★アソビVol.30にてテクニカルミーティング開催決定 | 『楽園追放 心のレゾナンス』
https://rakuen-tsuiho-r.com/news/?article_id=70285
『楽園追放 心のレゾナンス』テクニカルミーティング|マチアソビ30
https://www.machiasobi.com/event/283/
『楽園追放 心のレゾナンス』テクニカルミーティングに登壇したのは以下の4名。左から順にプロデューサーの野口光一さん、水島精二監督、エフェクト担当の多家正樹さん、アニメーションスーパーバイザーの荻田直樹さんです。

会場は「ufotable CINEMA 」のシアター2で、しっかり満席になっていました。
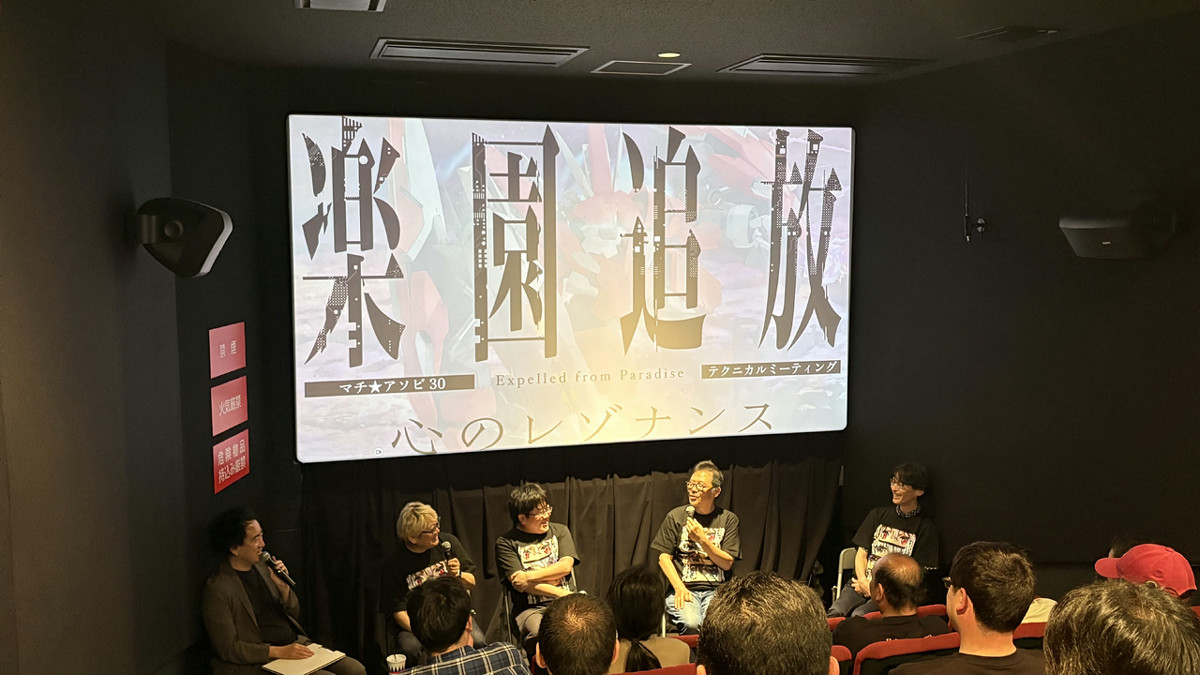
テクニカルミーティングでは、まず荻田さんが「楽園追放流のアニメーションの作り方」を解説してくれました。荻田さんいわく、アニメーターにとって最も重要な能力は「観察力」とのこと。アクションでもギャグでも基本的に「現実の動きのデフォルメ」であるため、現実世界の人や物の動きを観察する力が最重要となるそうです。
具体的には「細分化する力」が求められます。例えば「座っている状態から立ち上がる」という動作の場合、素人では「『座っている状態』『立ち上がっている状態』『立っている状態』の3コマで成立しそう」と考えてしまいますが、実際には「足の位置を調整する」「手で支える」「手で押し出す」といった細かい動きをしています。さらに、「両手両足は異なる角度で動く」「左右のタイミング差もある」「風が吹いているとか酔っているとかでの動きが変わる」といったように立ち上がる動作だけでも非常に多くの部分に気を配る必要があるのです

アニメ作品の制作には大勢のアニメーターが参加しており、アニメーターによってアニメーションのできあがりに差ができます。この差をなるべく減らすのが荻田さんのようなスーパーバイザーの仕事というわけ。水島監督は荻田さんを「影の監督」と評していました。
荻田さんによる「フェイシャルチェック」の実例も紹介されました。『楽園追放 心のレゾナンス』はフル3D作品であり、キャラクターは3Dモデルを動かすことで描画されています。しかし、単純な3Dモデルでは角度によって顔が「アニメ的に不自然な顔」になってしまうことがあるため、さまざまな工夫によってキャラクターの顔を可愛く見せる必要があります。荻田さんはアニメーターが提出した映像にさらに修正点を指摘してブラッシュアップする役割を担っています。
「ラグエル」が登場するシーンの修正前(左)と修正後(右)が以下。「輪郭を柔らかくする」「口の変形を大胆に変更して、輪郭からはみ出るくらい変形させる」といった修正指示によってシーンの意図にあった描写になりました。

顔が大きく映るシーンでは「白目の影の大きさ」「口の位置」「歯の見え方」といった細かいところにまでこだわって修正します。荻田さんの可愛い見せ方へのこだわりは半端なものではなく、水島監督が「可愛くできてるよ」と言っても荻田さんが「いや、これは」と言いながらとことんこだわって制作が進んでいるそうです。

続いて、エフェクト担当の多家さんが『楽園追放 心のレゾナンス』に登場する「REBUILDER(リビルダー)」と呼ばれるスライム状の正体不明物体を例に、3Dエフェクトを作り上げる過程について語ってくれました。多家さんは生粋のMaya使いであり、『THE FIRST SLAM DUNK』などの撮影を担当してきた人物です。水島監督いわく、多家さんは魔法使いのような存在とのこと。
リビルダーは「ブヨブヨの透明構造の中を外側とは異なる色のブヨブヨがうごめいている」という構造をしています。こういった構造を扱う際は「Houdini」という別の制作ツールを用いるのがスタンダードだそうですが、多家さんはMayaに含まれるビジュアルプログラミング環境である「Bifrost」を駆使して映像を作り上げました。多家さんが作り上げた「Bifrostの大量のノードがスパゲッティのように複雑に絡み合う画面」も提示されて会場がザワついていました。

イベントの最後には制作中の初公開映像が流され、大盛り上がりで幕を閉じました。

『楽園追放 心のレゾナンス』は2026年11月13日に公開予定。水島監督いわく「(公開までの)全体の見通しは立っている。みんながケツに火がついている。こういう現場はなんとかなる」とのことなので期待して待ちましょう。
・関連記事
アニメーター出身ではない「非作画系監督」はどうやってアニメを演出するのか?『楽園追放』水島精二×『デデデデ』黒川智之両監督によるトークイベント in マチ★アソビ Vol.30 - GIGAZINE
オリジナル劇場アニメ『楽園追放 心のレゾナンス』キービジュアル&最新ティザーPV&声優発表インタビュー映像公開 - GIGAZINE
監督・水島精二&脚本・虚淵玄のオリジナルアニメ映画「楽園追放 心のレゾナンス」特報映像公開 - GIGAZINE
映画「楽園追放 心のレゾナンス」制作決定、フルCGアニメ映画「楽園追放」の続編で水島精二&虚淵玄らメインスタッフ続投 - GIGAZINE
「マチ★アソビ vol.30」全記事一覧まとめ - GIGAZINE
・関連コンテンツ








in 試食, アニメ, 映画, Posted by log1o_hf
You can read the machine translated English article This report covers the technical meeting….