




クリックするだけで性別・年齢・髪型などを自然に変化させてリアルな顔写真を生成できる「TL-GAN」

機械学習の技術が進むことで、特徴を記述するだけでコンピューターがぴったりの画像を生成してくれる画像生成モデルが開発されています。従来のように巨大なマシンパワーを使うことなく、効率的に顔の特徴を自由に変更できる画像生成モデル「TL-GAN」をニューラルネットワーク研究者のシャオボ・グアン氏が開発しています。
Generating custom photo-realistic faces using AI – Insight Data
https://blog.insightdatascience.com/generating-custom-photo-realistic-faces-using-ai-d170b1b59255
◆生成モデルと識別モデル
「画像を記述(説明)する」ことは人間には容易で、幼い子どもでさえ自然に行うことができます。人間には簡単な「画像を記述する」行為は、コンピューターの機械学習では入力画像から特徴ラベルを予測するという形で行われています。
これに対して、「記述した説明から現実的なイメージを作り出す」という逆向きの行為はずっと難しく、人間でさえ何年間にもわたってデザイン訓練を積む必要があります。コンピューターに「記述からイメージを作らせる」ことは、機械学習では「generative(生成)」タスクであり、「discriminative(識別)」タスクよりもはるかに難しい作業とされ、小さな入力にも精細な画像が大量に必要とされるなど、扱う情報量が膨大になるという特徴があります。
◆生成モデル
「生成モデル」をうまく構築できれば、例えば、ウェブページのコンテンツやスタイルにぴったりの製品イメージ画像を自動的に生成したり、「レジャー」「夏」「情熱」などのキーワードを入力して新しいデザインを生み出したりといった「コンテンツの作成」が可能になります。
また、写真を数回クリックするだけで表情やしわ、髪形を調整したり、曇った夜の撮影映像を晴れた朝の撮影映像に変更したりと「コンテンツを編集」したり、自動運転技術のために足りないトレーニング用データセットを補うために、特定の事故シーンを作り出すことで、「データを補強」したりできるようになります。
・3つのモデル
生成モデルには、大きくわけて「autoregressive models(自己回帰モデル)」「VAE(Variational Autoencoders)」「GAN(Generative Adversarial Network)」の3つの有望なモデルがありますが、これまでのところ、最も現実的で説得力のある多様なイメージを生み出すのに成功しているのはGANだとグアン氏には述べています。
以下の人物の画像は、NVIDIAの「pg-GAN」が作り出した「実在しないニセモノのセレブ」たち。もはや、現実と虚構の境目境界を見分けられないレベルに到達していることがわかります。

◆GANモデルの出力コントロール
オリジナルのGANや派生したDC-GANやpg-GANなどは学習データにラベルをつけないで学習せさる「教師なし学習」モデルです。トレーニングの後、ジェネレーターネットワークは「ランダムノイズ」を入力として、トレーニングデータセットとほとんど区別できない現実的なイメージを生成します。しかし、生成したイメージの特徴をこれ以上はコントロールすることができないとのこと。

そこで、さらにイメージをコントロールするためにGANの改良版が作成されていますが、それらは「style-transfer networks(スタイル転送ネットワーク)」と「conditional generators(条件付きジェネレーター)」の2種類に大別できます。
・スタイル転送ネットワーク
「CycleGAN」と「pix2pix」に代表されるスタイル転送ネットワークは、ウマからシマウマへ、スケッチからカラー写真へなど、画像をある領域から別の領域に翻訳できるように訓練されたモデルです。スタイル転送ネットワークでは、ある1つの特徴について、離れた状態の間を連続的に調整することはできません。また、1つのネットワークは1つの転送専用のため、10個の機能をコントロールするには10個の異なるニューラルネットワークが必要になります。
・条件付きジェネレーター
AC-GANやStack-GANなどの条件付きGANは、トレーニングの途中に特徴ラベルとともに画像を共同学習するモデルで、画像生成に条件付けすることができます。そのため、新しい調整機能を生成プロセスに追加する場合には、GANモデル全体を再トレーニングする必要があり、これには膨大な計算リソースと時間がかかるという欠点があります。
・TL-GAN
既存の2つのGANネットワークの欠点を克服すべく、制御された生成タスクに新しい角度からアプローチすることで「単一のネットワークを使って、1つまたは複数の機能を徐々にチューニング(調整)できる機能」を持たせたのが、グアン氏が開発した「Transparent Latent-space GAN(TL-GAN)」です。グアン氏によると、チューニング可能な新しい特徴を加えるのにかかる時間は1時間未満という効率性だとのこと。
◆TL-GANによる効率的なアプローチ
グアン氏らのチームはTL-GAN(透過的潜在空間GAN)のベースとして、リアルな高解像度の顔イメージを生成するモデルであるNVIDIAのpg-GANを活用しています。1024×1024ピクセルの画像のすべての特徴は、画像コンテンツの低次元の表現として「latent-space(潜在空間)内の512次元ノイズベクトル」として決定されます。したがって、潜在空間が何を表しているのかを理解できれば、すなわち「透過」にできれば、生成プロセスを完全に制御できるという特長があるとグアン氏は述べています。

事前にトレーニングされたpg-GANをテストした結果、潜在空間(ノイズを含む領域)内の2点はとても連続的であり、2点を補うことで破綻のないリアルな画像を生成できるということがわかったとのこと。ここから、グアン氏は、例えば男性と女性など画像を特徴づける様々な潜在空間の方向性(ベクトル)を見つけられるのではないかと直感したそうです。
TL-GANでは、よくトレーニングされたpg-GANを使って、それぞれ40個のラベルを持つ3万以上の顔画像を含む「セレブA」データセットで、単純な畳み込みニューラルネットワークを訓練しました。そして、合成画像を作るためにトレーニングされたGANジェネレーターを通して多数のランダムな潜在空間ベクトルを作り出し、トレーニングされた特徴抽出器を使ってすべての画像の特徴を抜き出しました。さらに、一般化線形モデル(GLM)を使って潜在空間ベクトルと特徴の間の回帰を評価し、潜在空間ベクトルを特徴軸に沿って移動させることで生成されるイメージにどのような影響が出るのかを調べたとのこと。
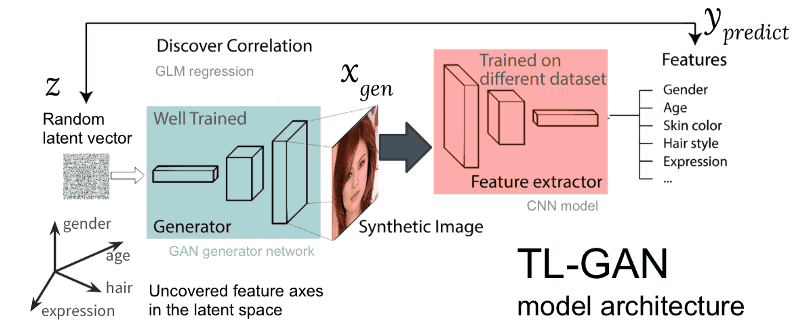
グアン氏は、上記プロセスを効率化することで、一度GANモデルが事前にトレーニングすると、単一のGPUを使ってわずか1時間で特徴軸を特定できるようになったそうです。
◆TL-GANでの画像生成
「性別」「年齢」「口の開き」など、いくつかの特徴軸にそって潜在空間ベクトルを移動させると以下のような画像を生成できました。5行×7列の画像は、中央の行が元の画像で、特徴軸ごとの列は縦方向に潜在空間ベクトルの量が変化します。非常にリニアに画像を変化させることには成功しましたが、「beard(ヒゲ)」の量を減らしていくと、オリジナルの男性画像が女性化してしまうなどの不具合が生じているのが分かります。

この問題を解決するために、グアン氏は線形代数学的なトリックを用いたとのこと。具体的には、ヒゲの軸を性別の軸に直交する新たな方向に投影してヒゲと性別との相関関係を効果的に除去することで、「ヒゲ成分を下げると女性成分も高まる」という問題を解消したそうです。
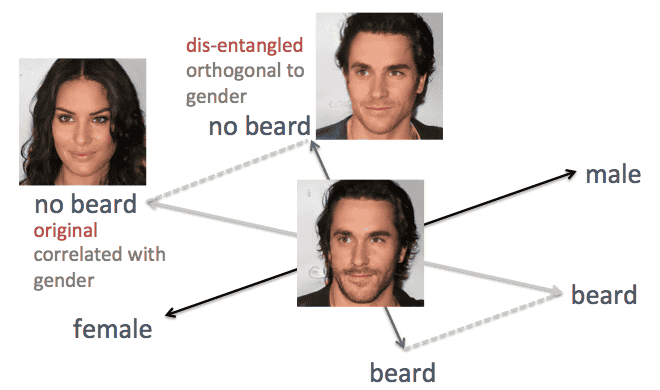
以上の改良の結果、得られたのが以下の画像。各特徴軸にそって、オリジナル画像の特徴をリニアかつ自然に変化させることに成功しています。

グアン氏の開発したTL-GANによる画像生成の様子は以下のムービーから。特徴軸のベクトルを調整するだけで、「もうちょっと年齢を若くして、笑みを増やし、ヒゲも増やして……」ということが実現できる驚愕の画像生成法が確認できます。
TL-GAN interface demo run 1 - YouTube

GANモデルを再トレーニングすることなく、40個の特徴を追加するのに1時間未満でOKというTL-GANは、以下のGitHubページで公開されています。
GitHub - SummitKwan/transparent_latent_gan: Use supervised learning to illuminate the latent space of GAN for controlled generation and edit
https://github.com/SummitKwan/transparent_latent_gan
・関連記事
AIが自動生成する「セレブっぽい写真」が実在するセレブっぽ過ぎて見分けがつかないレベル - GIGAZINE
Microsoftがテキストから本物と見間違うレベルの架空のイメージを自動生成する新AI技術「AttnGAN」を開発 - GIGAZINE
架空のアイドルを自動生成しまくる「アイドル生成AI」が誕生、どこかで見たことがあるようなないような顔が生成されまくり - GIGAZINE
邪魔な物体を塗りつぶすだけでAIが画像を違和感ないレベルに自動修正する技術「Image Inpainting」をNVIDIAが公開 - GIGAZINE
8×8ピクセルに縮小した画像から元の画像を予想する技術をGoogle Brainが開発 - GIGAZINE
頭に描いた「人の顔」のイメージを映像化する研究がエール大学で進行中 - GIGAZINE
ガビガビの低解像度写真を高解像度な写真に変換できる「EnhanceNet-PAT」が登場 - GIGAZINE
・関連コンテンツ







in 動画, ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article 'TL-GAN' that can generate realistic fac….