




FacebookがオープンソースのSQL対応分散クエリエンジンPrestoを発表、ペタバイト規模のデータ処理も可能

By Intel Free Press
ギガバイトからペタバイト(100万ギガバイト)まであらゆるサイズのデータをインタラクティブに解析して必要なデータを発見可能となるオープンソースのSQL対応分散クエリエンジンがPrestoです。Facebookのような企業が持つ大量の商業データでも高速に処理可能となるように設計されており、Prestoの出すクエリ(データベース管理システムに対する処理要求を文字列として表したもの)は複数ソースのデータと組み合わせることも可能。このシステムを開発したFacebookでは、約300ペタバイトにも及ぶ企業内部のデータを保管するデータ・ウェアハウスにてPrestoを使用しており、毎日1000人を超えるFacebookの従業員たちが1日当たり3万以上のクエリを走らせ、1ペタバイト以上のデータがスキャンされている、とのことです。
Presto | Distributed SQL Query Engine for Big Data
http://prestodb.io/
Presto: Interacting with petabytes of data at Facebook
https://www.facebook.com/notes/facebook-engineering/presto-interacting-with-petabytes-of-data-at-facebook/10151786197628920
◆FacebookがPrestoを開発するに至った経緯
Facebookは大量のデータを扱う企業です。アクティブユーザーが10億人以上も存在する、このモンスターソーシャルネットワークサービスにおいて、データの処理と解析は事業の中枢部分を担っています。Facebookのデータ・ウェアハウスは世界最大級ものの1つであり、そこでは300ペタバイト以上のデータを保管しており、そこに保存されるデータたちは従来のバッチ処理からグラフ解析、機械学習およびリアルタイムのインタラクティブ解析など、広範囲のアプリケーションに使われている、とのこと。データを処理し、洞察してFacebookのサービス改善に貢献してくれるアナリストやデータサイエンティスト、エンジニアなどにとって、このデータ・ウェアハウスのパフォーマンスの詳細は重要な情報であり、より多くのクエリを実行できたり結果をより速く導き出せるようになれば、彼らの生産性も改善されることになります。

By Intel Free Press
Facebookのデータ・ウェアハウスのデータたちはHadoop/HDFSベースのコンピュータ・クラスターに保存されており、大規模かつシステム全体の処理能力を能率的に利用するようHadoop MapReduce(データの分散処理技術)と、Hive(Hadoopの上に構築されるデータ・ウェアハウス構築環境で、データの集約・問い合わせ・分析を行う)に最適化されていました。しかし、Facebookのデータ・ウェアハウスはペタバイト規模の非常にスケールの大きなものであり、データも徐々に増えている状況だったそうです。そこで、ペタバイト規模でも素早く動作可能な新しいインタラクティブ・クエリシステムのPrestoを構築することを決めた、とのこと。
◆Presto
Prestoはインタラクティブにアドホック分析を行うことに最適化されたSQL対応分散クエリエンジンで、標準ANSI SQLをサポートしています。Prestoのシステム・アーキテクチャーを簡単に表したのが以下の図で、クライアントがPrestoのコーディネーター(調整者)にSQL(データの操作や定義を行うための問い合わせ言語)を送ります。コーディネーターは分解・分析を行い、クエリの実行計画を立て、実行パイプラインを引き、データに近いノードに仕事を割り当て、データ処理の進捗をモニター。クライアントは出力段階からの各段階でもデータをプルすることが可能です。
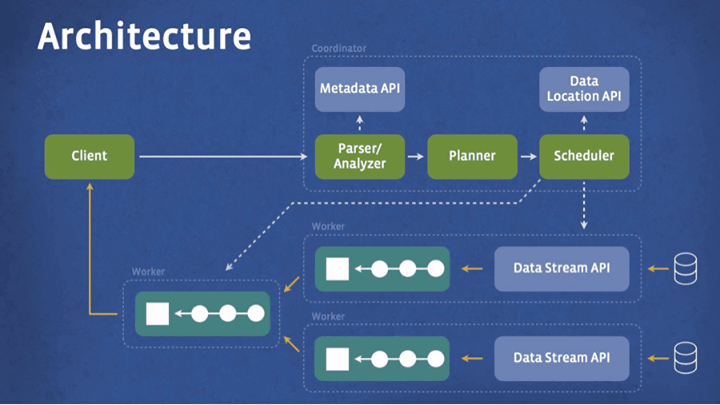
PrestoのクエリエンジンはMapReduceを使用せず、カスタムクエリとセマンティック検索の実行エンジンをサポート。クエリの実行スケジューリングが改善されており、それに加えて全てのデータ処理はメモリとネットワーク内のパイプライン上で行われ、不必要な入出力なども回避します。PrestoのシステムはJavaで実行されるのですが、これは開発が素早く行え、大きなエコシステムを持ち、Facebookの他データ・インフラストラクチャー・コンポーネントに統合するのが容易になるためです。また、メモリとデータ構造を慎重に扱うことでJavaコードでよく起こる、メモリ割り当てとガベージコレクションの問題を回避しています。
拡張性はPrestoの重要な要素の1つ。大きなデータセット(処理されるデータのまとまり)がHDFSに加えて他の多くのシステム内に保管されている、ということをプロジェクトの初期段階でFacebookのエンジニアたちは発見したそうです。そしてFacebookのデータ・ウェアハウスのデータ保管場所は、HBaseのような有名なデータベースもあればカスタムメイドのものにも保存されていました。こういった経緯からPrestoはシンプルかつ異なるデータソースに対しても簡単にSQLクエリを提供できるように設計されたようです。
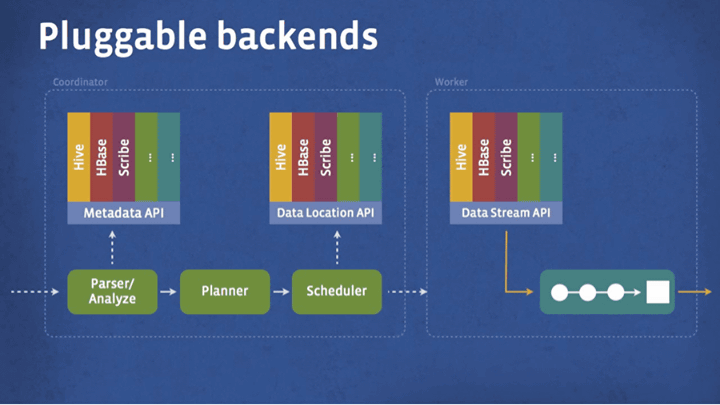
Prestoの開発は2012年秋からスタートし、2013年の初め頃に最初の運用をスタート、2013年の春にはFacebookのデータ・ウェアハウス全体で運用されるようになりました。CPU効率や処理スピードという点でみれば、PrestoはHive/MapReduceを運用するよりも10倍もよい結果を出す、とのこと。現在サポートしているのはANSI SQLの部分集合的のようなもので、表結合・表の外部結合・サブクエリ・共通抽出・スカラ関数・近似値検索などが利用可能ですが、結合テーブルのサイズや基数に制限があります。クエリ結果はクライアントに流されますが、各テーブルにデータを出力することは現在のところ不可能となっています。
なお、Prestoはオープンソースのクエリエンジンであり、GitHubにてソースコードを見ることができます。
・関連記事
Facebook最新の自社サーバとデータセンターの写真や仕様が満載、高度なサーバ効率化技術を公開する「Open Compute Project」開始 - GIGAZINE
「世界初のウェブサーバ」と「日本最初のホームページ」 - GIGAZINE
Googleの初代サーバを間近から詳細に撮影した写真いろいろ - GIGAZINE
「あけおめことよろ」ツイート殺到でTwitter撃沈、サーバが落ちる - GIGAZINE
「アメーバピグのサーバ(仮)」を入手することに成功、じっくりと調べて撮影してみた - GIGAZINE
ドラゴンクエストXは「世界は一つ」を実現するためにどのようなサーバ構成にしているのか? - GIGAZINE
・関連コンテンツ





in ソフトウェア, ネットサービス, Posted by logu_ii
You can read the machine translated English article Facebook announces Presto, an open-sourc….