




GoogleがAI処理チップの第8世代TPUを発表、学習特化の「TPU 8t」と推論特化の「TPU 8i」が存在しワットあたりの性能は2倍に

GoogleはAI処理に特化したプロセッサー「TPU」を独自開発しています。2026年4月22日には第8世代TPUとして学習に特化した「TPU 8t」と推論に特化した「TPU 8i」が発表されました。
Two chips for the agentic era
https://blog.google/innovation-and-ai/infrastructure-and-cloud/google-cloud/eighth-generation-tpu-agentic-era/
スンダー・ピチャイCEOが投稿したTPU 8i(左)とTPU 8t(右)の実物写真が以下。第8世代TPUは学習特化のTPU 8tと推論特化のTPU 8iに分かれて設計されているのが大きな特徴です。

TPU 8tは9600個のチップを1つのポッドに納めて並列実行することが可能。9600個のTPU 8tを接続することでFP4での演算性能は121エクサフロップスに達します。また、新開発のネットワーク技術「Virgo Network」を用いることで、チップを100万個まで増やしてもほぼ線形のスケーリングを実現できます。
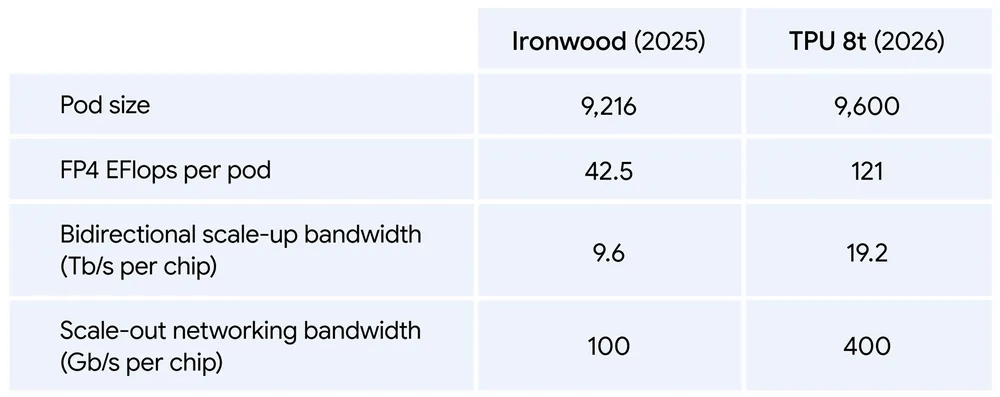
大規模なAIモデルの学習には数カ月の時間が必要であり、ハードウェア障害などによる再起動によって1%でも非稼働時間が増えると数日分の時間損失が発生します。TPU 8tは数万個の信頼性の向上も大きな特徴で、有用で計算的な生産時間の指標であるグッドプットが97%を超えているとのこと。GoogleはTPU 8tの性能および信頼性の向上によって「数カ月かかる最先端モデルの開発サイクルを数週間へと短縮する」とアピールしています。
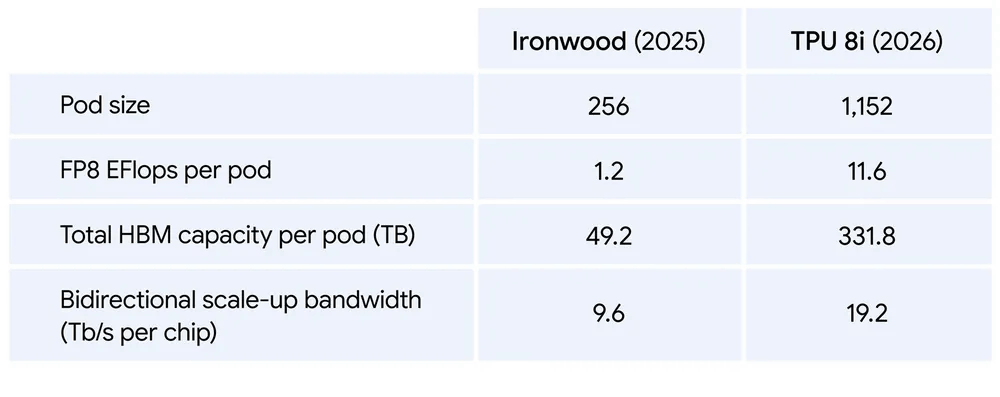
TPU 8iは288GBの広帯域幅メモリ(HBM)と384MBのSRAMを搭載した推論特化チップです。1ポッドに1152個のTPU 8iを納めることが可能で、ポッド当たりの演算性能はFP8精度で11.6エクサフロップスに達しています。TPU 8iは推論ワークロードにけるレイテンシを削減するように設計されているほか、インターコネクトの帯域幅を19.2TB/sに倍増することでMoEモデルの低遅延実行も可能としています。
TPU 8tとTPU 8iはGoogle Cloudの第4世代液冷技術に対応してエネルギー効率の最適化を実現しています。これにより、前世代のIronwoodと比較して1ワット当たりの処理性能が2倍に向上しています。

TPU 8tとTPU 8iは2026年後半に一般提供される予定です。
・関連記事
NVIDIAがAI特化GPU「Rubin」とAI特化CPU「Vera」の詳細を発表、AIラック「Vera Rubin NVL72」の処理性能はFP64精度で2400TFLOPS&Groqの高速推論チップも統合 - GIGAZINE
MetaとBroadcomが提携を拡大、Metaの独自AIチップ「MTIA」の展開が加速する見込み - GIGAZINE
Amazonが3nmの新AIチップ「Trainium3」を発表、「Trainium2」より4倍高速&コスト最大50%削減&さらに「Trainium4」も予告 - GIGAZINE
AMDがAIスーパーコンピューター「Lux」と「Discovery」の開発を発表、Discoveryには次世代AI特化GPU「Instinct MI430X」を搭載し官民合わせて1500億円の投資 - GIGAZINE
Microsoft製AIチップ「Maia 200」が稼働開始、3nmプロセスで製造されGPT-5.2などの推論をサポート - GIGAZINE
Claude開発企業のAnthropicがGoogleのTPUを大規模導入するべくGoogleおよびBroadcomと契約締結 - GIGAZINE
・関連コンテンツ








in AI, ハードウェア, Posted by log1o_hf
You can read the machine translated English article Google has announced its 8th generation ….