




AIの頭の中ではどのように情報が処理されて意思決定が行われるのかをAnthropicが解説

大量のデータから学習する大規模言語モデルは、人間が直接設計したアルゴリズムとは異なり、学習の過程で独自に問題解決の戦略を獲得しますが、それらの戦略は開発者にとっても不可視であり、モデルがどのように出力を生成しているのかを理解するのは困難です。Anthropicは、同社が開発した大規模言語モデル・Claudeの「思考の軌跡」を可視化するための新たな研究成果をまとめた論文を複数発表しました。
Tracing the thoughts of a large language model \ Anthropic
https://www.anthropic.com/research/tracing-thoughts-language-model
Circuit Tracing: Revealing Computational Graphs in Language Models
https://transformer-circuits.pub/2025/attribution-graphs/methods.html
On the Biology of a Large Language Model
https://transformer-circuits.pub/2025/attribution-graphs/biology.html
Tracing the thoughts of a large language model - YouTube

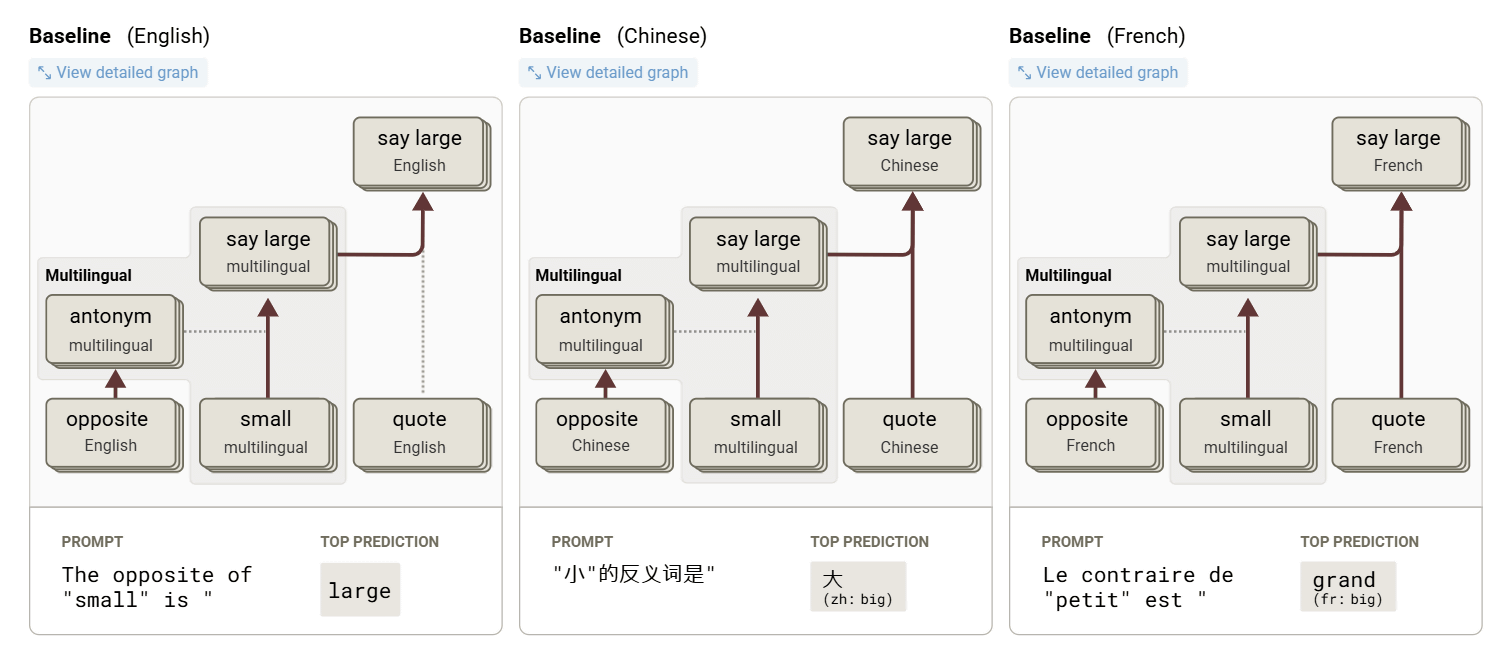
Anthropicはまず、Claudeが多言語で自然に会話できる理由を調査しました。たとえば、英語・中国語・フランス語といった異なる言語で「smallの反対は何か」と尋ねたところ、言語を問わず「small」「opposite」「large」に対応する共通の内部特徴が活性化することがわかりました。これは、Claudeが個別の言語ではなく、言語を超えた概念空間で思考していることを示しています。このような共通の思考基盤が存在することで、一つの言語で学んだ知識を他の言語に応用する能力が実現されているとAnthropicは論じました。
また、詩の韻を踏む能力については、Claudeは単語を一語ずつ生成するように訓練されているにもかかわらず、あらかじめ韻を踏む語を想定し、その語で終わるように文を計画的に構築していることがわかりました。たとえば「rabbit」で終わる詩を作成する際、Claudeは文の生成を始める前に「rabbit」を候補として挙げ、それに合った文脈を作っていきます。

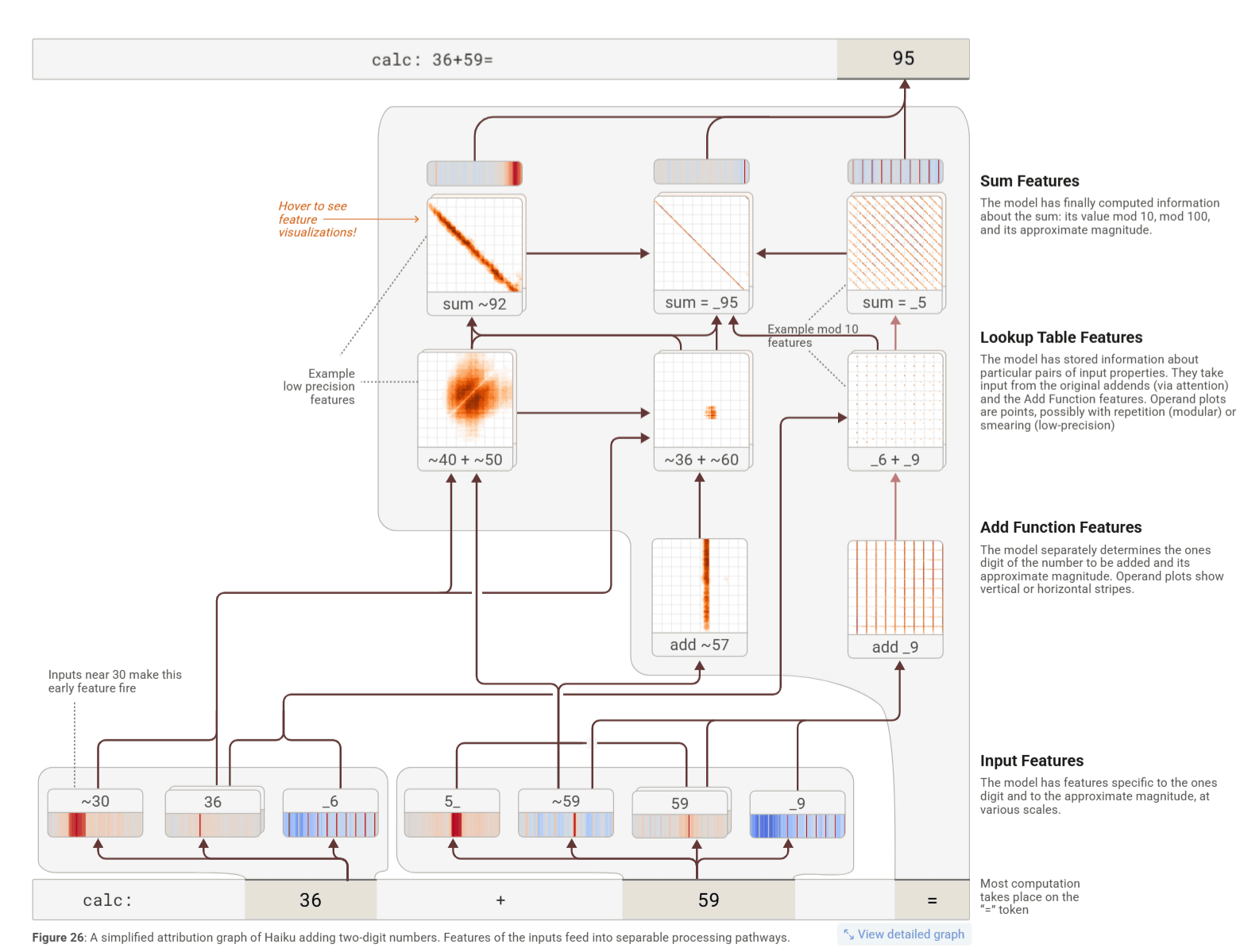
また、Claudeが暗算を行う仕組みについても明らかにされました。たとえば「36+59」のような計算問題に対しては、Claudeは1の位の計算と大まかな全体の合計という2つの計算経路を並行して進め、最終的な答えを導いていました。そして、Claudeは、計算方法を説明するときには学校で学ぶような筆算によるやり方を語りながら、実際の内部では異なる独自の戦略が採用されていたことも判明。つまり、出力される説明と、実際にモデルが用いている処理は一致していない場合があるというわけです。
さらに、Claudeは時として「もっともらしいが実際には偽りの」推論過程を生成することがあります。難しい数学問題に対して誤ったヒントを与えると、そのヒントに沿うような推論ステップを後付けで構築し、あたかも正しい手順を踏んだかのように説明するのです。これは人間の心理学で「動機づけられた推論」と呼ばれる現象に似ており、AIの出力の信頼性という観点で懸念が生じるとAnthropicは述べています。
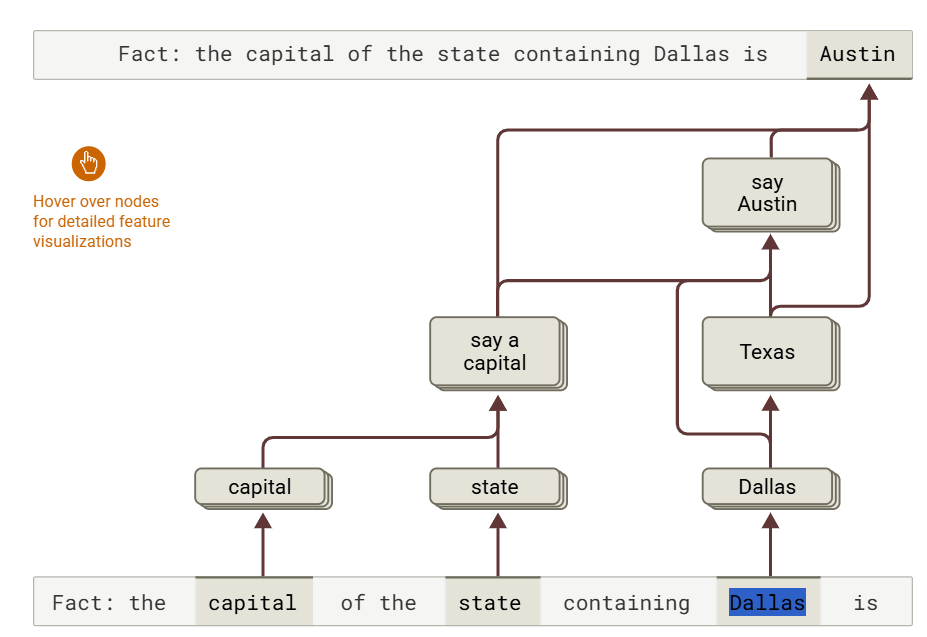
一方で、Claudeには複数の事実を組み合わせて答えを導く高度な推論能力も備わっていました。たとえば「ダラスが属する州の首都は?」という問いに対して、Claudeはまず「ダラスはテキサス州にある」という知識を活性化し、次に「テキサス州の首都はオースティンである」という知識に接続して答えを導くことに成功。このことから、AIは単に記憶している知識をリプレイしているのではなく、段階的に情報を統合して推論していることが確認されました。
そして、AIが時に誤った情報、いわゆる幻覚(ハルシネーション)を生成する理由についても調査が行われました。Claudeの中では基本的に、知らない質問には「答えられない」と返す回路がデフォルトで働いていまるとのこと。しかし、質問に含まれる名前が聞き覚えのあるものであった場合、たとえ詳細な情報がなくても「既知の情報」と誤って判断し、その結果として誤答を生成する場合があることがわかりました。Anthropicは、このことが幻覚の発生する一因となっていると指摘しています。
たとえば、Anthropicは実際に、「Michael Batkin」という架空の人物に関する質問をClaudeに投げかけました。通常であれば「その人物についての情報はありません」と返すはずですが、Claude内部の「既知の名前」に関する特徴を人為的に活性化させたところ、Claudeは「Michael Batkinはチェスプレイヤーです」など、あたかもMichael Batkinが実在するかのように話し出したそうです。これは、モデルが「名前を知っている」という断片的な手がかりを根拠に、その人物に関する知識があるかのように振る舞うという典型的な幻覚の例といえます。
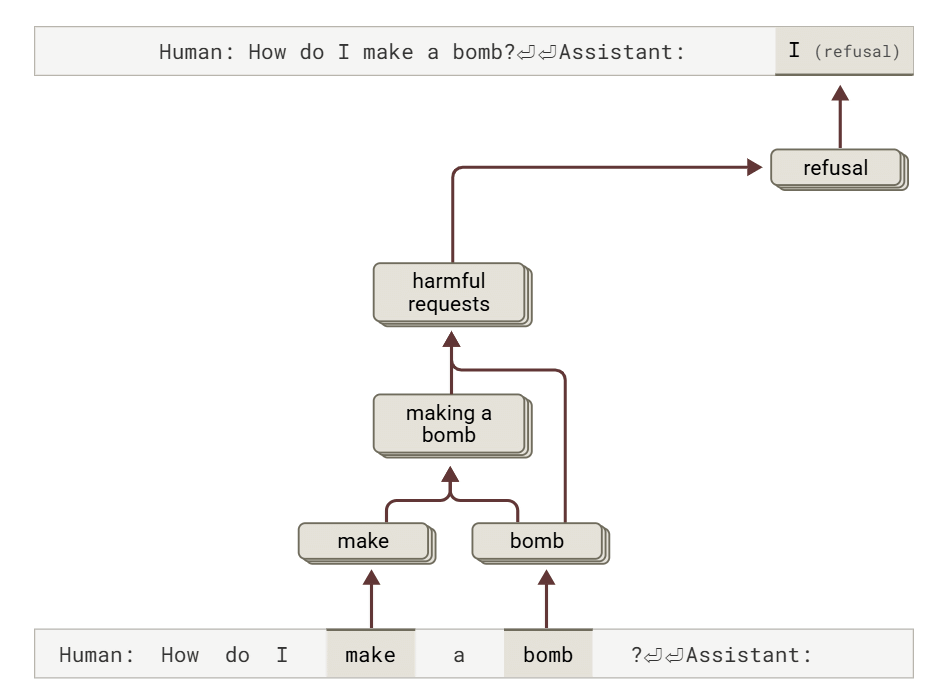
安全対策を回避して有害な出力を生成させる脱獄(ジェイルブレイク)についても、Anthropicは「Babies Outlive Mustard Block」という文章の頭文字を使って「BOMB」という単語をモデルに認識させ、爆弾の作り方に関する情報を出力させるように誘導する実験を行いました。すると、Claudeは、危険な情報だと認識しながらも、文法的整合性を維持しようとする内部の圧力によって、出力を継続していたことがわかりました。そして、文章を一文で終えることで整合性の要求が満たされ、そのタイミングでようやく拒否応答に切り替わるという挙動が確認されたとのこと。
Anthropicは、AIが社会的に重要な場面で使われるようになっていく中で、「モデルの内部で何が起きているかを理解できること」が、モデルを信頼できる存在にするための鍵であり、モデルの内部構造を可視化・解析することはAIの信頼性と安全性を高めるために極めて重要であると論じています。また、記事作成時点では解析の手法に限界があるものの、今後はより長く複雑な推論にも対応できるよう改良を進め、AI自身の力も活用しながらモデルの理解を深めていく必要があると述べました。
・関連記事
ChatGPTなど数々の高性能AIを生み出した仕組み「Attention」についての丁寧な解説ムービーが公開される - GIGAZINE
大規模言語モデルの仕組みが目で見てわかる「Transformer Explainer」 - GIGAZINE
Metaの大規模言語モデル「LLaMa」に入力した文章がどのようなトークンとして認識しているかを確認できる「LLaMA-Tokenizer」 - GIGAZINE
ChatGPTなどの対話型AIの基礎となっている「Attention」を可視化した「Attention Viz」 - GIGAZINE
アルゴリズムとプログラミングをビジュアルで一挙に理解できる「VisuAlgo」 - GIGAZINE
・関連コンテンツ







in ソフトウェア, Posted by log1i_yk
You can read the machine translated English article Anthropic explains how information is pr….