




AIのトレーニングで使用されるチップ「H100」「H200」「MI300X」の性能を比較した結果判明した事実とは?

AIの学習や推論に用いるAIインフラストラクチャーの市場では、「H100」「H200」といったNVIDIA製のAI特化チップが大きなシェアを獲得しています。一方で、NVIDIAのライバル企業となるAMDも2023年12月に「Instinct MI300X」を発表しています。そんなH100・H200・MI300Xについて、テクノロジー系メディアのSemianalysisがさまざまなベンチマークテストを実施し、それぞれの結果について報告しています。
MI300X vs H100 vs H200 Benchmark Part 1: Training – CUDA Moat Still Alive – SemiAnalysis
https://semianalysis.com/2024/12/22/mi300x-vs-h100-vs-h200-benchmark-part-1-training/
2023年12月に発表されたAMDの「MI300X」は、前世代のInstinct MI250Xより約40%多いコンピューティングユニットや1.5倍のメモリ容量、1.7倍のピーク理論メモリ帯域幅を備えており、NVIDIAのH100のような競合製品に対しても優位を保っていることがアピールされてきました。
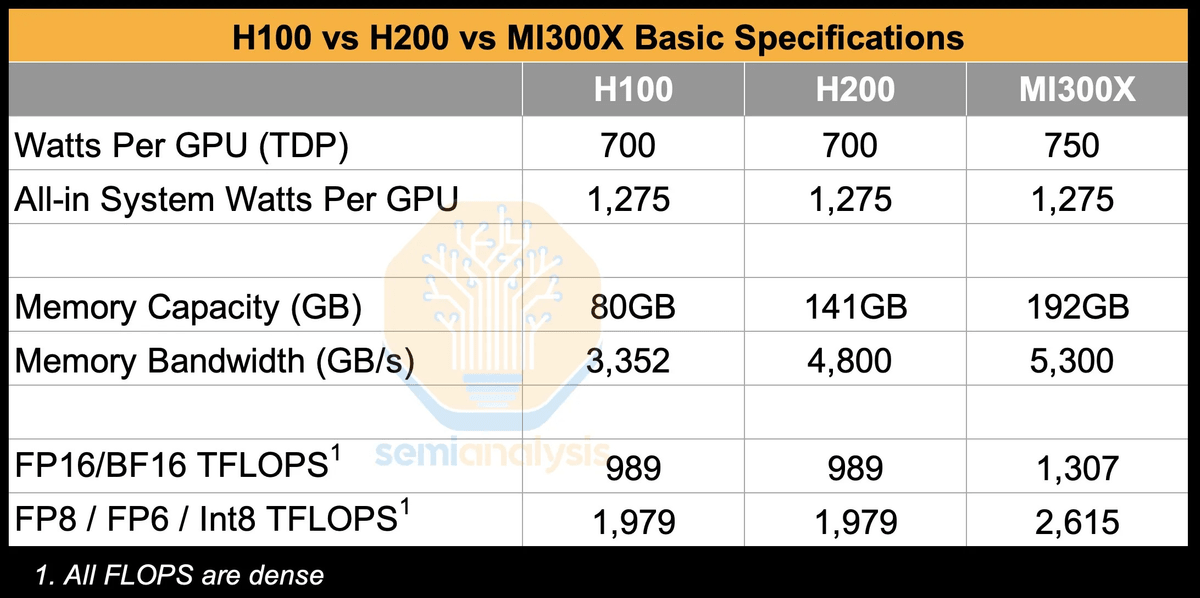
実際に、H100・H200・MI300Xの熱設計電力(TDP)やGPU当たりのワット数、メモリ容量、メモリ帯域幅、FP16やBF16、ならびにFP8・FP6・Int8での処理性能を比較した表が以下。H100やH200のTDPは700、MI300XのTDPは750のほか、GPU当たりのワット数は同じ、H100のメモリ容量は80GB、H200のメモリ容量は141GB、MI300Xは192GBです。H100・H200のメモリ帯域幅はそれぞれ3352GB/s、4800GB/sでMI300Xは5300GB/s。さらにFP16やBF16での処理性能はNVIDIA製チップが989TFLOPS、MI300Xが1307TFLOPS、FP8・FP6・Int8での処理性能はH100・H200が1979TFLOPS、MI300Xが2615TFLOPSと、MI300Xが高い性能を有していることが示されています。
Semianalysisはこれらのチップを用いてさまざまなベンチマークテストを実施。一例として、ChatGPTやLlamaなどTransformerモデルを採用した最先端のチャットAIをハードウェア上でどのようにトレーニングできるかを確かめるための指標であるGEMMパフォーマンステストでは、H100とH200が約720TFLOP/sを達成した一方で、MI300Xはわずか620TFLOP/sにとどまり、MI300XがH100およびH200よりも約14%遅いことが示されました。
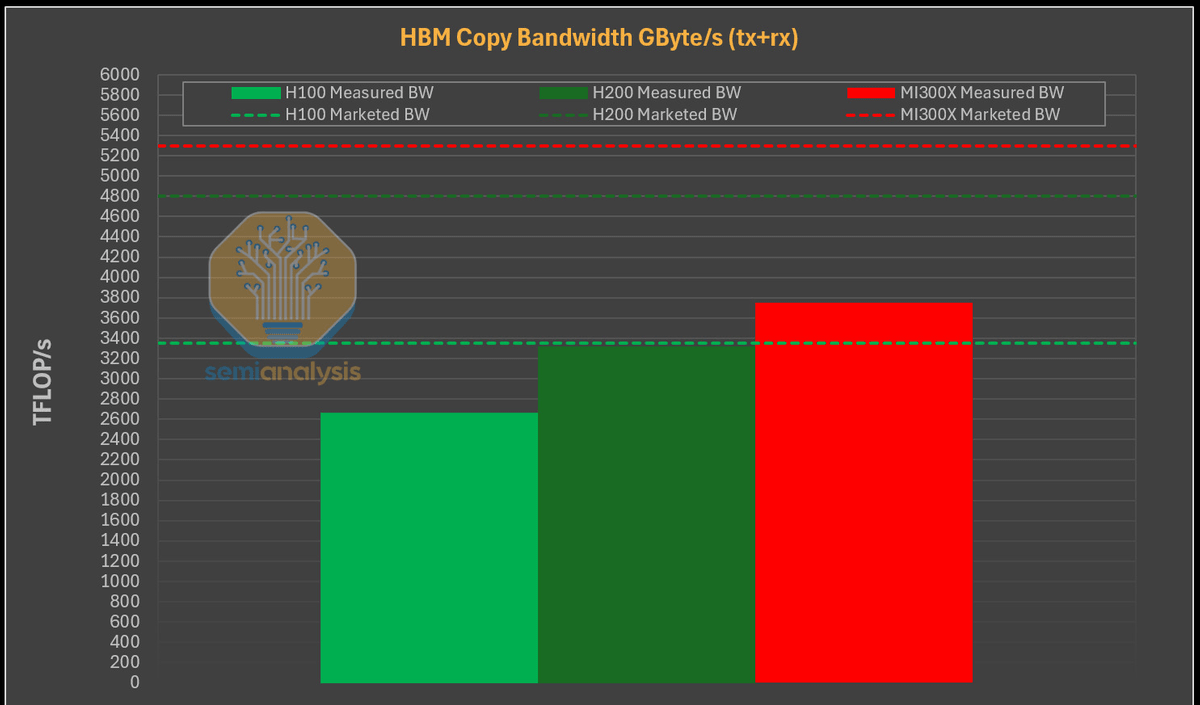
その一方で、MI300XはH200の4.8TB/sおよびH100の3.35TB/sと比較して、5.3TB/sの帯域幅を備えていることが広く知られています。PytorchのTensor.copy_を用いたテストの結果、MI300XはH100ならびにH200よりもはるかに優れたメモリ帯域幅を備えていることが確認されました。
しかし、これらのチップでシングルノードトレーニングパフォーマンスをテストした結果、緑色で示されたH100とH200が、赤ならびに茶色で示されたMI300Xの複数バージョンよりも優れていることが明らかになっています。
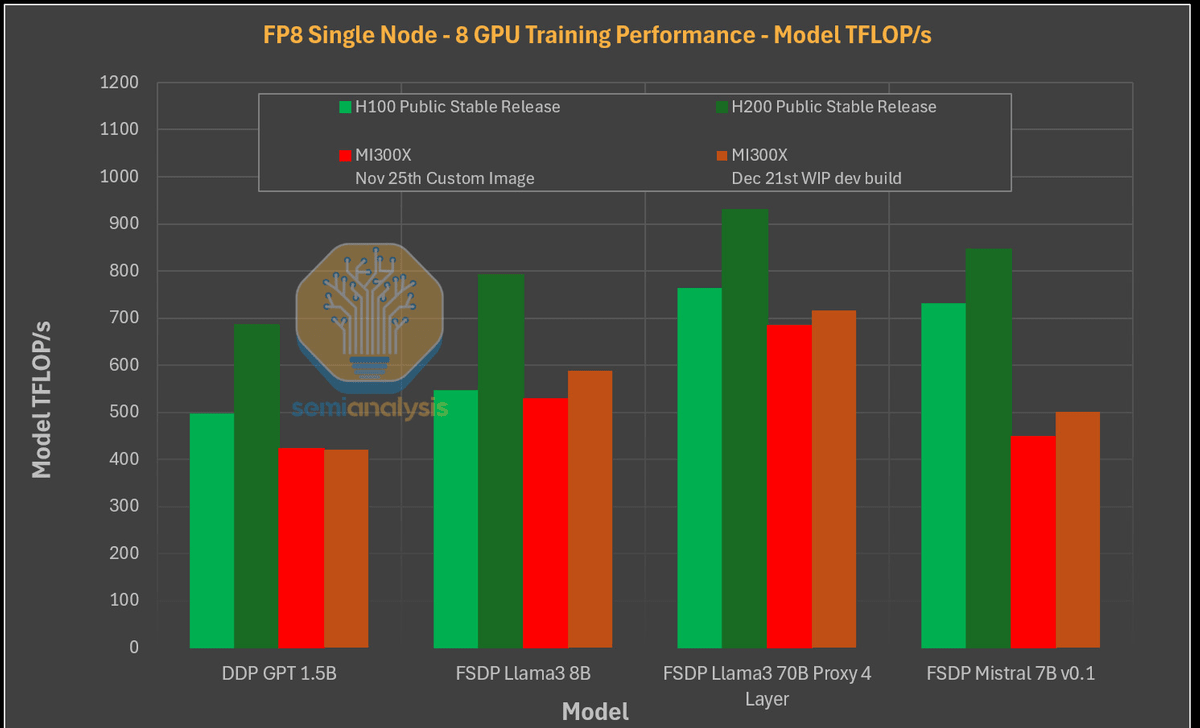
また、MI300XはGPT-2 1.5Bなどの小型モデルやMistral 7B v0.1などのモデルではパフォーマンスが比較的低かったことが指摘されています。Semianalysisによると、NVIDIA製AIチップでは性能を最適化するFlexAttentionが機能していた一方で、記事作成時点でのAMD製チップはFlexAttentionが完全に機能していなかったとのこと。そのため、H100ならびにH200は、MI300Xの2024年11月25日時点でのビルドと比べて2.5倍以上の性能を発揮したことが報告されています。
さらに、マルチノードトレーニングのパフォーマンスを比較した結果、H100がMI300Xと比べて約10~25%高速であることが示されました。Semianalysisは「この差は、単一のトレーニングワークロードで連携するノードを増やすにつれて広がります」と述べています。
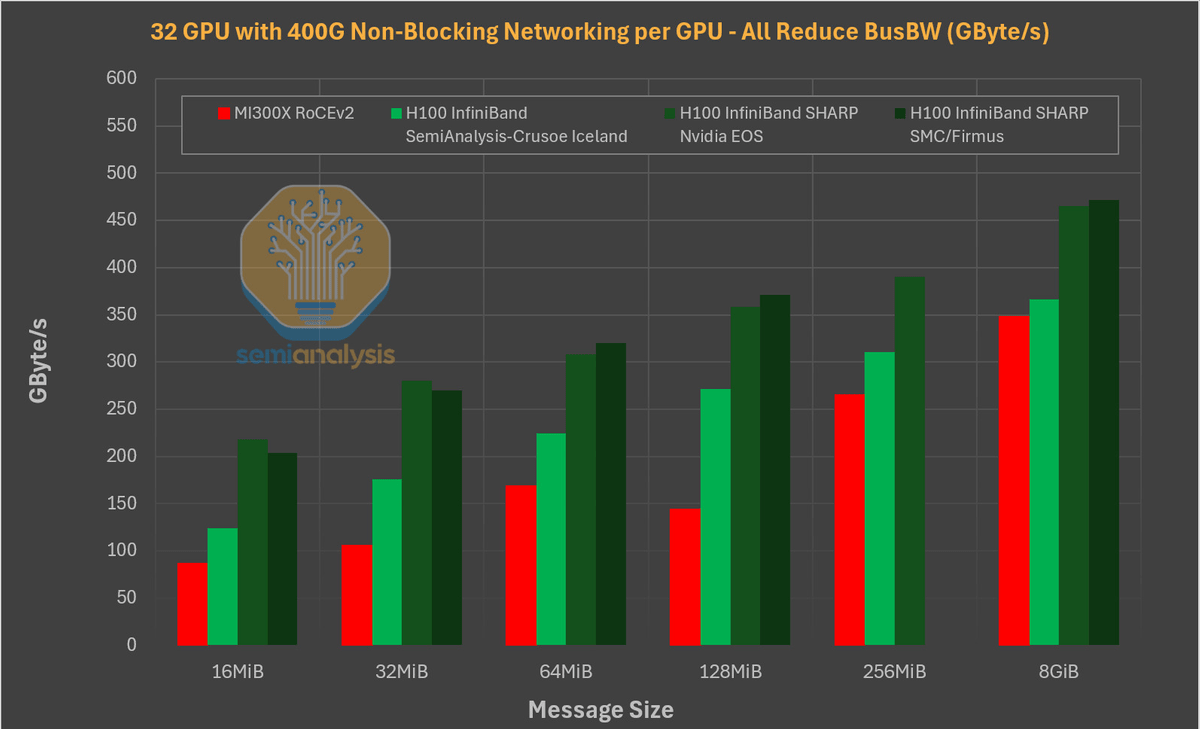
今回のベンチマークテストの結果について、Semianalysisは「NVIDIA製のチップと比べて性能が高いはずのMI300Xのベンチマーク結果が振るわなかった要因は、AMDのソフトウェアがMI300Xのパフォーマンスを阻害していることが示唆されました」と述べ「AMDが本当の意味でトレーニングワークロードの分野でNVIDIAに挑戦するためには、ソフトウェアの改善に重点を置く必要があります」と指摘しました。
・関連記事
Microsoftはライバルの2倍にあたる48万5000基もNVIDIAのHopper GPUを購入、ByteDanceとTencentがそれぞれ約23万基、Metaが22万5000基 - GIGAZINE
NVIDIA B200とGoogle TrilliumがMLPerfベンチマークチャートに出現、B200はH100と比較し2倍のパフォーマンス - GIGAZINE
AMDがAIチップ「Instinct MI300」シリーズでNVIDIAの牙城に切り込む、既にOpenAI・Microsoft・Meta・Oracleが採用を決定 - GIGAZINE
MicrosoftがAMDのAIチップ「MI300X」を用いた高コスパのAI開発用クラウドサービスを提供開始 - GIGAZINE
AMDが最大192GBのメモリをサポートした生成AI向けアクセラレータ「AMD Instinct MI300X」を発表 - GIGAZINE
AMDがAIソフトウェア開発企業のNod.aiを買収、NVIDIAに対する競争力強化の狙いか - GIGAZINE
NVIDIAの独占を防ぐためにMicrosoftとAMDが協力体制を取っている - GIGAZINE
・関連コンテンツ








in ハードウェア, ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article What did we find out by comparing the pe….