




「CAPTCHA」を人間以上の精度で突破するAIが登場

by Duncan Rawlinson - Duncan.co
英語圏で最もアクセス数が多い世界最大規模の画像掲示板「4chan」では、書き込みを投稿する際に自分が人間であることを証明するCAPTCHAをクリアしなければなりません。機械学習を使用してこのCAPTCHAを突破するプロジェクトの記録を、フルスタックソフトウェア開発者のBlackjack氏が公開しました。
Breaking the 4Chan CAPTCHA | nullpt.rs
https://www.nullpt.rs/breaking-the-4chan-captcha
Blackjack氏はまず、モデルをトレーニングするためのデータを取得するため、スクリプトを作成して4chanのCAPTCHA画像数百枚をスクレイピングしました。
その過程で、頻繁にリクエストするなどの行動を取ると不正対策としてCAPTCHAがどんどん難しくなることがわかりました。以下は、難しめのCAPTCHA画像の例です。

トレーニング用のデータセットには、CAPTCHAを実際に解いた正解を含める必要があります。
Blackjack氏は自分でCAPTCHAを解いたり、信頼できる友だちに頼んだり、作業者がCAPTCHA画像を突破してくれる外注サービスを利用したりといった方法を試してみましたが、精度が低すぎるなどの問題で断念せざるを得ませんでした。
人力での解決を諦めたBlackjack氏は、合成データを使う方法を思いつきました。4chanのCAPTCHAは、背景のノイズと特定の文字で構成されています。以下がその例で、CAPTCHA画像から文字をなくしたノイズだけが残されています。
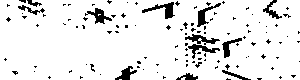
Blackjack氏によると、CAPTCHA画像に含まれる文字の成分である「大きめの輪郭」だけを除去してノイズだけを残すのは簡単だったとのこと。
続いて、スクリプトで文字を抜き出しつつ、MicrosoftのオープンソースソフトウェアであるVoTTを使って手動でタグ付けをして、各文字ごとに50~150枚の画像を収集しました。
その過程で、Blackjack氏はCAPTCHA画像に使われているのは限られた文字だけだということに気づきました。
以下はCAPTCHAの文字のサンプルです。数字の「3」やアルファベットの「B」などがないのは、紛らわしい文字の使用を避けるためだと推測されています。
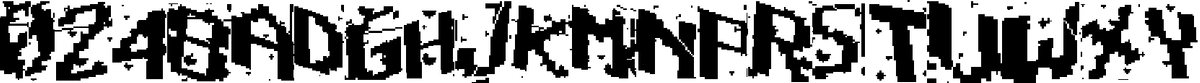
トレーニング用データセットには、最終的に手作業で作成した回答済みCAPTCHA画像約500枚と、合成生成画像約5万枚が含まれました。そして3つの畳み込み層を持つ畳み込みニューラルネットワーク(CNN)と2つの長・短期記憶(LSTM)層を組み合わせたLSTM CNNアーキテクチャのモデルを構築し、データセットでトレーニングしました。
こうして開発されたAIモデルは、4chanのCAPTCHAを90%を超える精度で突破できたとのこと。これは人間の作業者が実際にCAPTCHAを解く前述の商業サービスの80%よりも高い精度です。
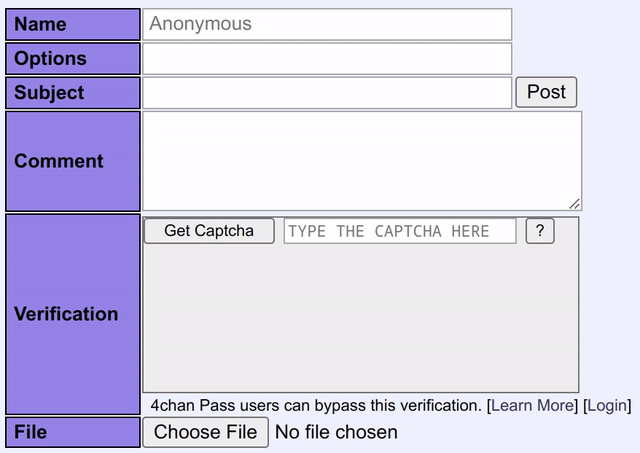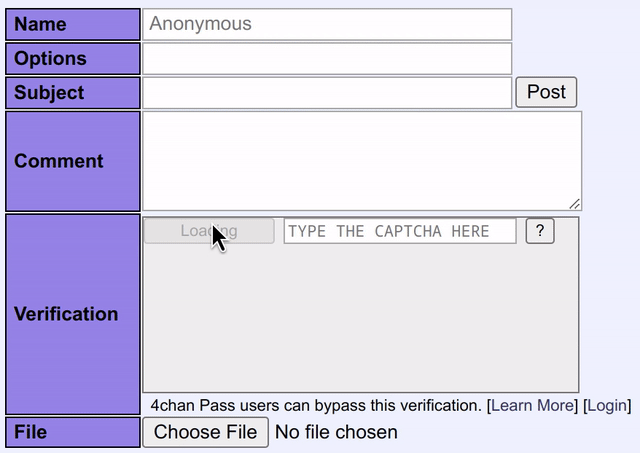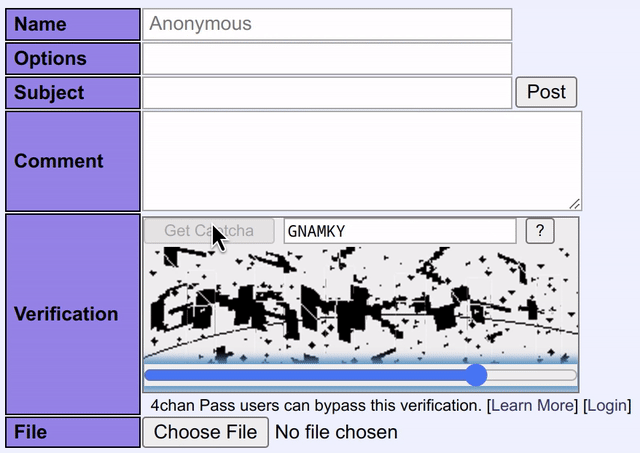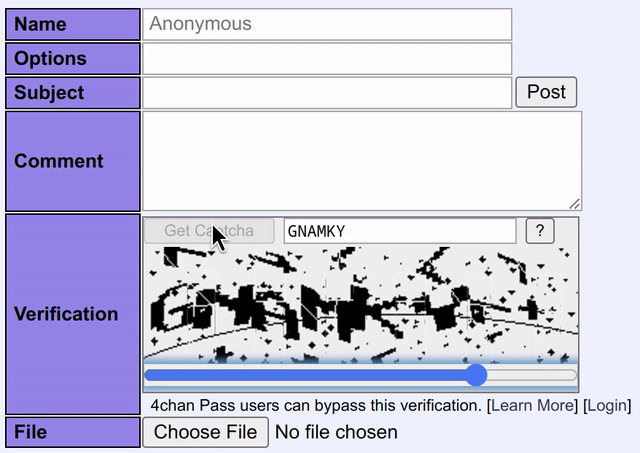
Blackjack氏は「このプロジェクトはとても楽しかったです。克服すべき課題がいくつかありましたが、その過程で機械学習やコンピュータビジョンについて学ぶことができました。もちろん改善点も残っていますが、当初目指していた目標は達成できたので、今のところ成果に満足しています」と述べました。
・関連記事
AIの進化でボットの方が人間よりも高速かつ高精度でCAPTCHA認証を突破することが可能に - GIGAZINE
自分がロボットでないことを示すGoogleの「reCAPTCHA v2」をAIで突破することに成功 - GIGAZINE
CAPTCHA認証でこの世に存在しない物体が指定されてしまうトラブルが発生 - GIGAZINE
「私はロボットではありません」を証明するCAPTCHAの難易度がどんどん上がっている - GIGAZINE
GPT-4が「私はロボットではありません」を突破、事情を知らない人間に「私は盲目の人間なので代わりに解いて」とおねだり - GIGAZINE
機械学習を使ってCAPTCHAをわずか15分で突破するチャレンジが行われる - GIGAZINE
面倒で難しい「私はロボットではありません」をワンクリックで突破できるCAPTCHA自動回答ツール「Buster」レビュー - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article AI that breaks through CAPTCHAs with gre….